
Comparing replication and erasure coding
You must consider factors such as data temperature, i/o cost, storage cost, and file size when comparing replication and erasure coding.
- Data Temperature
- Data temperature refers to how often data is accessed. EC works best with cold data that is accessed and modified infrequently. There is no data locality, and all reads are remote. Replication is more suitable for hot data, data that is accessed and modified frequently because data locality is a part of replication.
- I/O Cost
- EC has higher I/O costs than replication for the following reasons:
- EC spreads data across nodes and racks, which means reading and writing data comes at a higher network cost.
- A parity block is generated when data is written, thus impacting write speed. This can be slower than writing to a file when the replication factor is one but is faster than writing two or more replicas.
- If data is missing or corrupt, a DataNode reads the remaining data and parity blocks in order to reconstruct the data. This process requires CPU and network resources.
Cloudera recommends at least a 10 GB network connection if you want to use EC.
- Storage Cost
- EC has a lower storage overhead than replication because multiple copies of data are not maintained. Instead, a number of parity blocks are generated based on the EC policy. For the same amount of data, EC will store fewer blocks than 3x replication in most cases. For example with a Reed-Solomon (6,3), HDFS stores three parity blocks for each set of 6 data blocks. With replication, HDFS stores 12 replica blocks for every six data blocks, the original block and three replicas. The case where 3x replication requires fewer blocks is when data is stored in small files.
- File Size
- Erasure coding works best with larger files. The total number of blocks is determined
by data blocks + parity blocks, which is the data-stripe width discussed earlier.
128 MB is the default block size. With RS (6,3), each block group can hold up to (128 MB * 6) = 768 MB of data. Inside each block group, there will be 9 total blocks, 6 data blocks, each holding up to 128 MB, and 3 parity blocks. This is why EC works best with larger files. For a chunk of data less than the block size, replication writes one data block to three DataNodes; EC, on the other hand, still needs to stripe the data to data blocks and calculate parity blocks. This leads to a situation where erasure coded files will generate more blocks than replication because of the parity blocks required. The bytes/blocks ratio is worse for small files which increases the memory usage of the NameNode.
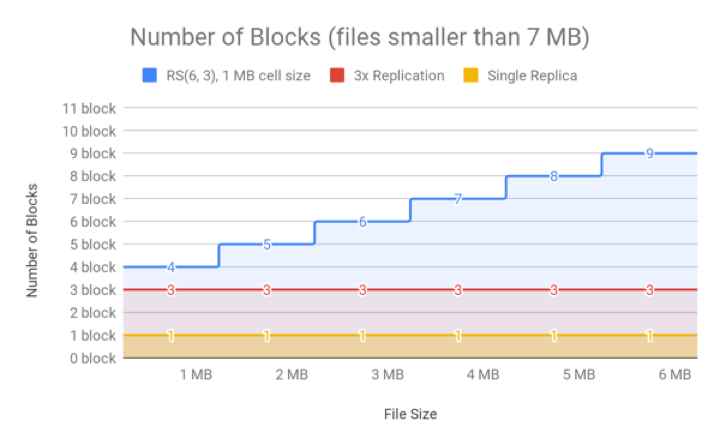
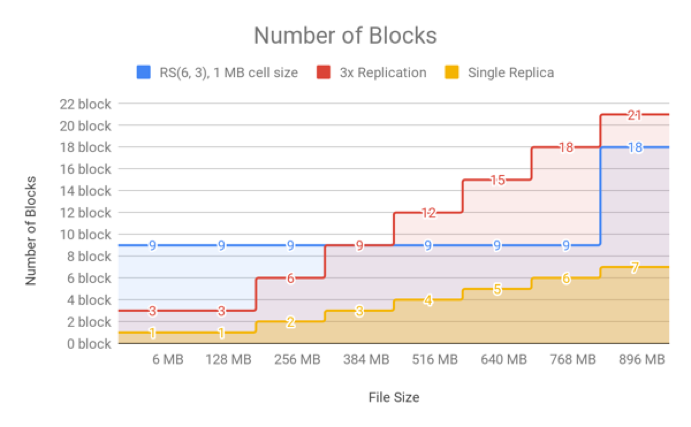
The following two figures show how replication (with a replication factor of 3) compares to EC based on the number of blocks relative to file size.
For very small files of sizes smaller than the value of data blocks * cell size (in case of RS(6, 3) it is (6 * 1) MB), the number of actual data blocks is less than the data blocks defined by the erasure coding policy, though the number of parity blocks is always the same. For example, in the case of RS(6,3) with a cell size of 1 MB, a 1MB file consists of one data block, rather than six, but it still has three parity blocks. A 1MB file would therefore require four block objects in total. If 3x replication were used, the same file would require only three block objects.
As shown in the following figure, the RS(6,3) EC policy ensures that the number of data blocks continues to remain less than that used by 3x replication for larger file sizes.
- Supported Engines
-
Replication supports all data processing engines that CDP supports.
EC supports the following data processing engines: Hive, MapReduce, and Spark.
- Unsupported Features
- The XOR codec for EC is not supported. Additionally, certain HDFS functions are not
supported with EC:
hflush,hsync,concat,setReplication,truncateandappend. For more information, see Erasure Coding Limitations. and HDFS Erasure Coding Limitations.
