
Configure the processor for your data target
This example use case shows you two options for ingesting data to Google Cloud Storage (GCS). Learn how you can configure these data NiFi processors for your GCS ingest flow.
- When you have finished configuring the options you need, save the changes by
clicking Apply.
The following properties are used for PutHDFS:
Table 1. PutHDFS processor properties Property Description Example value for ingest data flow Hadoop Configuration Resources
Specify the path to the
core-site.xmlconfiguration file.Make sure that the default file system (fs, default.FS) points to the GCS bucket you are writing to.
/etc/hadoop/conf.cloudera.core_settings/core-site.xml
Kerberos Principal
Specify the Kerberos principal (your username) to authenticate against CDP.
srv_nifi-gcs-ingest
Kerberos Password
Provide the password that should be used for authenticating with Kerberos.
password
Directory
Provide the path to your target directory in Google Cloud expressed in a GCS compatible path. It can also be relative to the path specified in the
core-site.xmlfile.gs://your path/customer
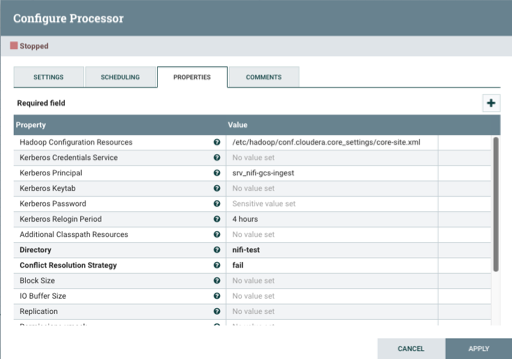
You can leave all other properties as default configurations.
For a complete list of PutHDFS properties, see the processor documentation.
If you want to use the PutGCSObject processor to store the data in Google Cloud Storage, you have to configure your processor to reference the controller service you configured before:
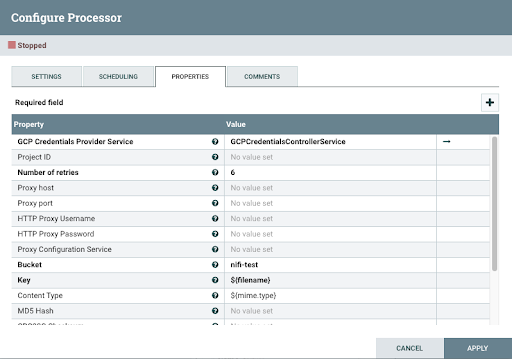
If you want to move data to a different location, review the other use cases in the Cloudera Data Flow for Data Hub library.
