Known Issues and Limitations in CDH 6.3.3
The following sections describe the known issues in CDH 6.3.3, grouped by component:
- Operating System Known Issues
- Apache Accumulo
- Apache Crunch
- Apache Flume
- Apache Hadoop
- Apache HBase
- Hive/HCatalog/Hive on Spark
- Hue
- Apache Impala
- EMC Isilon
- Apache Kafka
- Apache Kudu
- Apache Oozie
- Apache Parquet
- Apache Pig
- Cloudera Search
- Apache Sentry
- Apache Spark
- ORC file format is not supported
- Apache Sqoop
- Apache ZooKeeper
Operating System Known Issues
Known issues and workarounds related to operating systems are listed below.
Linux kernel security patch and CDH services crashes CVE-2017-10000364
A fatal error has been detected by the Java Runtime Environment: SIGBUS (0x7) at pc=0x00007fe91ef6cebc, pid=30321, tid=0x00007fe930c67700
Cloudera services for HDFS and Impala cannot start after applying the patch.
Commonly used Linux distributions are shown in the table below. However, the issue affects any CDH release that runs on RHEL, CentOS, Oracle Linux, SUSE Linux, or Ubuntu and that has had the Linux kernel security patch for CVE-2017-1000364 applied.
If you have already applied the patch for your OS according to the advisories for CVE-2017-1000364, apply the kernel update that contains the fix for your operating system (some of which are listed in the table). If you cannot apply the kernel update, you can workaround the issue by increasing the Java thread stack size as detailed in the steps below.
| Distribution | Advisories for CVE-2017-1000364 | Advisory updates |
|---|---|---|
| Oracle Linux 6 | ELSA-2017-1486 | Oracle has fixed this problem in ELSA-2017-1723. |
| Oracle Linux 7 | ELSA-2017-1484 | Oracle has also added the fix for Oracle Linux 7 in ELBA-2017-1674. |
| RHEL 6 | RHSA-2017-1486 | RedHat has fixed this problem for RHEL 6, marked this as outdated and superseded by RHSA-2017-1723. |
| RHEL 7 | RHSA-2017-1484 | RedHat has fixed this problem for RHEL 7 and has marked this patch as outdated and superseded by RHBA-2017-1674. |
| SLES | CVE-2017-1000364 | SUSE has also fixed this problem and the patch names are included in this same advisory. |
Workaround
If you cannot apply the kernel update, you can set the Java thread stack size to -Xss1280k for the affected services using the appropriate Java configuration option or the environment advanced configuration snippet, as detailed below.
For role instances that have specific Java configuration options properties:
- Log in to Cloudera Manager Admin Console.
- Select , and then click the Configuration tab.
- Type java in the search field to display Java related configuration parameters. The Java Configuration Options for Catalog Server property field displays. Type -Xss1280k in the entry field, adding to any existing settings.
- Click Save Changes.
- Navigate to the HDFS service by selecting .
- Click the Configuration tab.
- Click the Scope filter DataNode. The Java Configuration Options for DataNode field displays among the properties listed. Enter -Xss1280k into the field, adding to any existing properties.
- Click Save Changes.
- Select the Scope filter NFS Gateway. The Java Configuration Options for NFS Gateway field displays among the properties listed. Enter -Xss1280k into the field, adding to any existing properties.
- Click Save Changes.
- Restart the affected roles (or configure the safety valves in next section and restart when finished with all configurations).
For role instances that do not have specific Java configuration options:
- Log in to Cloudera Manager Admin Console.
- Select , and then click the Configuration tab.
- Click the Scope filter Impala Daemon and Category filter Advanced.
- Type impala daemon environment in the search field to find the safety valve entry field.
- In the Impala Daemon Environment Advanced Configuration Snippet (Safety Valve), enter:
JAVA_TOOL_OPTIONS=-Xss1280K
- Click Save Changes.
- Click the Scope filter Impala StateStore and Category filter Advanced.
- In the Impala StateStore Environment Advanced Configuration Snippet (Safety Valve), enter:
JAVA_TOOL_OPTIONS=-Xss1280K
- Click Save Changes.
- Restart the affected roles.
The table below summarizes the parameters that can be set for the affected services:
| Service | Settable Java Configuration Option |
|---|---|
| HDFS DataNode | Java Configuration Options for DataNode |
| HDFS NFS Gateway | Java Configuration Options for NFS Gateway |
| Impala Catalog Server | Java Configuration Options for Catalog Server |
| Impala Daemon | Impala Daemon Environment Advanced Configuration Snippet (Safety Valve) |
| JAVA_TOOL_OPTIONS=-Xss1280K | |
| Impala StateStore | Impala StateStore Environment Advanced Configuration Snippet (Safety Valve) |
| JAVA_TOOL_OPTIONS=-Xss1280K |
Cloudera Issue: CDH-55771
Leap-Second Events
Impact: After a leap-second event, Java applications (including CDH services) using older Java and Linux kernel versions, may consume almost 100% CPU. See https://access.redhat.com/articles/15145.
Leap-second events are tied to the time synchronization methods of the Linux kernel, the Linux distribution and version, and the Java version used by applications running on affected kernels.
Although Java is increasingly agnostic to system clock progression (and less susceptible to a kernel's mishandling of a leap-second event), using JDK 7 or 8 should prevent issues at the CDH level (for CDH components that use the Java Virtual Machine).
Immediate action required:
(1) Ensure that the kernel is up to date.
-
RHEL6/7, CentOS 6/7 - 2.6.32-298 or higher
-
Oracle Enterprise Linux (OEL) - Kernels built in 2013 or later
-
SLES12 - No action required.
-
Java 8 - No action required.
(3) Ensure that your systems use either NTP or PTP synchronization.
For systems not using time synchronization, update both the OS tzdata and Java tzdata packages to the tzdata-2016g version, at a minimum. For OS tzdata package updates, contact OS support or check updated OS repositories. For Java tzdata package updates, see Oracle's Timezone Updater Tool.
Cloudera Issue: CDH-44788, TSB-189
Apache Accumulo Known Issues
There are no known issues in this release of Apache Accumulo.
Apache Crunch Known Issues
Apache Flume Known Issues
The following section describes known issues and workarounds in Flume, as of the current production release.
Fast Replay does not work with encrypted File Channel
If an encrypted file channel is set to use fast replay, the replay will fail and the channel will fail to start.
Workaround: Disable fast replay for the encrypted channel by setting use-fast-replay to false.
Apache Issue: FLUME-1885
Apache Hadoop Known Issues
This page includes known issues and related topics, including:
Deprecated Properties
Several Hadoop and HDFS properties have been deprecated as of Hadoop 3.0 and later. For details, see Deprecated Properties.
Hadoop Common
KMS Load Balancing Provider Fails to invalidate Cache on Key Delete
The KMS Load balancing Provider has not been correctly invalidating the cache on key delete operations. The failure to invalidate the cache on key delete operations can result in the possibility that data can be leaked from the framework for a short period of time based on the value of the hadoop.kms.current.key.cache.timeout.ms property. Its default value is 30,000ms. When the KMS is deployed in an HA pattern the KMSLoadBalancingProvider class will only send the delete operation to one KMS role instance in a round-robin fashion. The code lacks a call to invalidate the cache across all instances and can leave key information including the metadata and key stored (the deleted key) in the cache on one or more KMS instances up to the key cache timeout.
-
CDH
-
HDP
-
CDP
-
CDH 5.x
-
CDH 6.x
-
CDP 7.0.x
-
CDP 7.1.4 and earlier
-
HDP 2.6 and later
Users affected: Customers with Data-at-rest encryption enabled that have more than 1 kms role instance and the services Key Cache enabled.
Impact: Key Meta-data and Key material may remain active within the service cache.
Severity: Medium
- CDH customers: Upgrade to CDP 7.1.5 or request a patch
- HDP customers: Request a patch
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: TSB 2020-434: KMS Load Balancing Provider Fails to invalidate Cache on Key Delete
HDFS
Possible HDFS Erasure Coded (EC) Data Files Corruption in EC Reconstruction
Cloudera has detected two bugs that can cause corruption of HDFS Erasure Coded (EC) files during the data reconstruction process.
The first bug can be hit during DataNode decommissioning. Due to a bug in the data reconstruction logic during decommissioning, some parity blocks may be generated with a content of all zeros.
Usually the NameNode makes a simple copy of the block when re-replicating it during decommissioning. However, if a decommissioning DataNode is already assigned with more than the replication streams hard limit (It can be set by using the dfs.namenode.replication.max-streams-hard-limit property. Its default value is 4.), the node will be treated as busy and instead of performing a simple copy, the parity blocks may be reconstructed as all zeros.
Subsequently if any other data blocks in the same EC group are lost (due to node failure or disk failure), the reconstruction may use a bad parity block to generate bad data blocks. So, once parity blocks are corrupted, any further reconstruction in the same block group can propagate further corruptions in the same block group.
The second issue occurs in a corner case when a DataNode times out in the reconstruction process. It will reschedule a read from another good DataNode. However, the stale DataNode reader may have polluted the buffer and subsequent reconstruction which uses the polluted buffer will suffer from EC block corruption.
- CDH
- HDP
- CDP Private Cloud Base
- CDH 6.0.x
- CDH 6.1.x
- CDH 6.2.x
- CDH 6.3.x
- HDP 3.1.x
- CDP 7.1.x
- Using an affected version of the product.
- Have enabled EC policy on one or more HDFS directories and have some EC files.
- Decommissioned DataNodes after enabling the EC policy will increase the probability of corruption.
- Rarely EC reconstructions can create dirty buffer issues which will lead to data corruption.
hdfs fsck / -files | grep "erasure-coded: policy=" /ectest/dirWithPolicy/sample-sales-1.csv 215 bytes, erasure-coded: policy=RS-3-2-1024k, 1 block(s): OK
If there are any file paths listed in the output of the above command, and if you have decommissioned DataNodes after creating those files, your EC files may have been affected by this bug.
If no files were listed by the above command, then your data is not affected. However, if you plan to use EC or if you have enabled EC policy on any directory in the past, then we strongly recommend requesting a hotfix from Cloudera.
Severity: High
Impact: With erasure coded files in the cluster, if you have done the decommission, the data files are potentially corrupted. HDFS/NameNode cannot self-detect and self-recover the corrupted files. This is because checksums are also updated during reconstruction. So, the HDFS client may not detect the corruption while reading the affected blocks, however applications may be impacted. Even in the case of normal reconstruction, the second dirty buffer issue can trigger corruption.
- If EC is enabled, request for a hotfix immediately from Cloudera.
- In case EC was enabled and decommission of DataNodes was performed in the past after enabling EC, Cloudera has implemented tools to check the possibility of corruption. Contact Cloudera support in such a situation.
- If no decommission was done in the past after enabling EC, then it is recommended not to perform decommission of DataNodes until the hotfix is applied.
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: Cloudera Customer Advisory: Possible HDFS Erasure Coded (EC) Data Files Corruption in EC Reconstruction
HDFS NFS gateway and CDH installation (using packages) limitation
HDFS NFS gateway works as shipped ("out of the box") only on RHEL-compatible systems, but not on SLES or Ubuntu. Because of a bug in native versions of portmap/rpcbind, the HDFS NFS gateway does not work out of the box on SLES or Ubuntu systems when CDH has been installed from the command-line, using packages. It does work on supported versions of RHEL-compatible systems on which rpcbind-0.2.0-10.el6 or later is installed, and it does work if you use Cloudera Manager to install CDH, or if you start the gateway as root. For more information, see CDH and Cloudera Manager Supported Operating Systems.
- On Red Hat and similar systems, make sure rpcbind-0.2.0-10.el6 or later is installed.
- On SLES and Ubuntu systems, do one of the following:
- Install CDH using Cloudera Manager; or
- Start the NFS gateway as root; or
- Start the NFS gateway without using packages; or
- You can use the gateway by running rpcbind in insecure mode, using the -i option, but keep in mind that this allows anyone from a remote host to bind to the portmap.
No error when changing permission to 777 on .snapshot directory
Snapshots are read-only; running chmod 777 on the .snapshots directory does not change this, but does not produce an error (though other illegal operations do).
Affected Versions: All CDH versions
Apache Issue: HDFS-4981
Snapshot operations are not supported by ViewFileSystem
Affected Versions: All CDH versions
Snapshots do not retain directories' quotas settings
Affected Versions: All CDH versions
Apache Issue: HDFS-4897
Permissions for dfs.namenode.name.dir incorrectly set
Hadoop daemons should set permissions for the dfs.namenode.name.dir (or dfs.name.dir) directories to drwx------ (700), but in fact these permissions are set to the file-system default, usually drwxr-xr-x (755).
Workaround: Use chmod to set permissions to 700.
Affected Versions: All CDH versions
Apache Issue: HDFS-2470
hadoop fsck -move does not work in a cluster with host-based Kerberos
Workaround: Use hadoop fsck -delete
Affected Versions: All CDH versions
Apache Issue: None
Block report can exceed maximum RPC buffer size on some DataNodes
On a DataNode with a large number of blocks, the block report may exceed the maximum RPC buffer size.
<property> <name>ipc.maximum.data.length</name> <value>268435456</value> </property>
Affected Versions: All CDH versions
Apache Issue: None
MapReduce2 and YARN
YARN Resource Managers will stay in standby state after failover or startup
ERROR org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Failed to load/recover state java.lang.NullPointerException at org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.addApplicationAttempt
This issue is fixed as YARN-7913.
Products affected: CDH with Fair Scheduler
-
CDH 6.0.x
-
CDH 6.1.x
-
CDH 6.2.0, CDH 6.2.1
-
CDH 6.3.0, CDH 6.3.1, CDH 6.3.2, CDH 6.3.3
User affected:
Any cluster running the Hadoop YARN service with the following configuration:
-
Scheduler set to Fair Scheduler
-
The YARN Resource Manager Work Preserving Recovery feature is enabled. That includes High Available setups.
Impact:
On startup or failover the YARN Resource Manager will process the state store to recover the workload that is currently running in the cluster. The recovery fails with a “null pointer exception” being logged.
Due to the recovery failure the YARN Resource Manager will not become active. In a cluster with High Availability configured the standby YARN Resource Manager will fail with the same exception leaving both YARN Resource Managers in a standby state. Even if the YARN Resource Managers are restarted, they still stay in standby state.
- Customers requiring an urgent fix who are using CDH 6.2.x or earlier: Raise a support case to request a new patch.
- Customers on CDH 6.3.x: Upgrade to the latest maintenance release.
-
CDH 6.3.4
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: TSB 2020-408: YARN Resource Managers will stay in standby state after failover or startup snapshot
Using OpenJDK 11 on CDH6.3 and above requires re-installation of YARN MapReduce Framework JARs
```
2019-07-18 14:54:52,483 ERROR [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Error starting MRAppMaster
java.lang.NoSuchMethodError: sun.nio.ch.DirectBuffer.cleaner()Lsun/misc/Cleaner;
at org.apache.hadoop.crypto.CryptoStreamUtils.freeDB(CryptoStreamUtils.java:41)
at org.apache.hadoop.crypto.CryptoInputStream.freeBuffers(CryptoInputStream.java:687)
at org.apache.hadoop.crypto.CryptoInputStream.close(CryptoInputStream.java:320)
at java.base/java.io.FilterInputStream.close(FilterInputStream.java:180)
```- Go to the YARN service.
- Select Actions > Install YARN MapReduce Framework JARs and click Install YARN MapReduce Framework JARs
- To verify, you will find the new MR Framework JARs under the MR Application Framework Path (default: /user/yarn/mapreduce/mr-framework/) For example:
`` hdfs dfs -ls /user/yarn/mapreduce/mr-framework/ Found 5 items -rw-r--r-- 332 yarn hadoop 215234466 2018-07-19 11:40 /user/yarn/mapreduce/mr-framework/3.0.0-cdh6.0.0-mr-framework.tar.gz -rw-r--r-- 97 yarn hadoop 263033197 2018-05-18 18:38 /user/yarn/mapreduce/mr-framework/3.0.0-cdh6.0.x-mr-framework.tar.gz -rw-r--r-- 331 yarn hadoop 222865312 2018-11-08 14:39 /user/yarn/mapreduce/mr-framework/3.0.0-cdh6.1.0-mr-framework.tar.gz -rw-r--r-- 327 yarn hadoop 232020483 2019-02-25 22:46 /user/yarn/mapreduce/mr-framework/3.0.0-cdh6.2.0-mr-framework.tar.gz -rw-r--r-- 326 yarn hadoop 234641649 2019-07-23 15:49 /user/yarn/mapreduce/mr-framework/3.0.0-cdh6.3.0-mr-framework.tar.gz ```
Cloudera Bug: CDH-81350
NodeManager fails because of the changed default location of container executor binary
The default location of container-executor binary and .cfg files was changed to /var/lib/yarn-ce. It used to be /opt/cloudera/parcels/<CDH_parcel_version>. Because of this change, if you did not have the mount options -noexec and -nosuid set on /opt, the NodeManager can fail to start up as these options are set on /var.
Affected versions CDH 5.16.1, All CDH 6 versions
Workaround: Either remove the -noexec and -nosuid mount options on /var or change the container-executor binary and .cdf path using the CMF_YARN_SAFE_CONTAINER_EXECUTOR_DIR environment variable.
YARN's Continuous Scheduling can cause slowness in Oozie
When Continuous Scheduling is enabled in Yarn, this can cause slowness in Oozie due to long delays in communicating with Yarn. In Cloudera Manager 5.9.0 and higher, Enable Fair Scheduler Continuous Scheduler is turned off by default.
Workaround: Turn off Enable Fair Scheduler Continuous Scheduling in Cloudera Manager YARN Configuration. To keep equivalent benefits of this feature, turn on Fair Scheduler Assign Multiple Tasks.
Affected Versions: All CDH versions
Cloudera Issue: CDH-60788
JobHistory URL mismatch after server relocation
After moving the JobHistory Server to a new host, the URLs listed for the JobHistory Server on the ResourceManager web UI still point to the old JobHistory Server. This affects existing jobs only. New jobs started after the move are not affected.
Workaround: For any existing jobs that have the incorrect JobHistory Server URL, there is no option other than to allow the jobs to roll off the history over time. For new jobs, make sure that all clients have the updated mapred-site.xml that references the correct JobHistory Server.
Affected Versions: All CDH versions
Apache Issue: None
History link in ResourceManager web UI broken for killed Spark applications
When a Spark application is killed, the history link in the ResourceManager web UI does not work.
Workaround: To view the history for a killed Spark application, see the Spark HistoryServer web UI instead.
Affected Versions: All CDH versions
Apache Issue: None
Cloudera Issue: CDH-49165
Routable IP address required by ResourceManager
ResourceManager requires routable host:port addresses for yarn.resourcemanager.scheduler.address, and does not support using the wildcard 0.0.0.0 address.
Workaround: Set the address, in the form host:port, either in the client-side configuration, or on the command line when you submit the job.
Affected Versions: All CDH versions
Apache Issue: None
Cloudera Issue: CDH-6808
Amazon S3 copy may time out
The Amazon S3 filesystem does not support renaming files, and performs a copy operation instead. If the file to be moved is very large, the operation can time out because S3 does not report progress during the operation.
Workaround: Use -Dmapred.task.timeout=15000000 to increase the MR task timeout.
Affected Versions: All CDH versions
Apache Issue: MAPREDUCE-972
Cloudera Issue: CDH-17955
GPU or Custom Resource Type User Jobs can Fail After Recovery
When a GPU or other custom resource goes offline when it has containers that use that particular resource and they have not reached completion, after the restart the application will start to recover. However, if the resource is not available anymore the job that uses that resource will fail.
Workaround: N/A
Affected Versions: CDH 6.2.0, CDH 6.3.0
Cloudera Issue: CDH-77649
Apache HBase Known Issues
The following section describes known issues and workarounds in HBase, as of the current production release.
Cloudera Navigator plugin impacts HBase performance
Navigator Audit logging for HBase access can have a big impact on HBase performance most noticeable during data ingestion.
Component affected: HBase
Products affected: CDH
Releases affected: CDH 6.x
Impact: 4x performance increase was observed in batchMutate calls after disabling Navigator Audit.
Severity: High
- In Cloudera Manager, navigate to .
- Find the Enable Audit Collection property and clear it.
- Restart the HBase service.
Upgrade: Upgrade to CDP where Navigator is no longer used.
HBASE-25206: snapshot and cloned table corruption when original table is deleted
HBASE-25206 can cause data loss either through corrupting an existing hbase snapshot or destroying data that backs a clone of a previous snapshot.
Component affected: HBase
- HDP
- CDH
- CDP
- CDH 6.x.x
- HDP 3.1.5
- CDP PVC Base 7.1.x
- Cloudera Runtime (Public Cloud) 7.0.x
- Cloudera Runtime (Public Cloud) 7.1.x
- Cloudera Runtime (Public Cloud) 7.2.0
- Cloudera Runtime (Public Cloud) 7.2.1
- Cloudera Runtime (Public Cloud) 7.2.2
Users affected: Users of the affected releases.
Impact: Potential risk of Data Loss.
Severity: High
- Make HBase do the clean up work for the splits:
- Before dropping a table that has any snapshots, first ensure that any regions that resulted from a split have fully rewritten their data and cleanup has happened for the original host region.
- If there are any remaining children of a split that have links to their parent still, then we first need to issue a major compaction for those regions (or the entire table).
- After doing the major compaction we need to ensure it has finished before proceeding. There should no longer be any split pointers (named like "<target hfile>.<target region>").
- Whether or not we needed to do a major compaction we must always tell the catalog janitor to run to ensure the hfiles from any parent regions are moved to the archive.
- We must wait for the catalog janitor to finish.
- At this point it is safe to delete the original table without data loss.
- Manually do the archiving:
- Alternatively, as a part of deleting a table we can manually move all of its files into the archive. First disable the table. Next make sure each region and family combination that is present in the active data area is present in the archive. Finally move all hfiles and links from the active area to the archive.
- At this point it is safe to drop the table.
- Addressed in release/refresh/patch: Cloudera Runtime 7.2.6.0
Apache issue: HBASE-25206
KB article: For the latest update on this issue see the corresponding Knowledge article: TSB 2021-453: HBASE-25206 "snapshot and cloned table corruption when original table is deleted"
HBase Performance Issue
The HDFS short-circuit setting dfs.client.read.shortcircuit is overwritten to disabled by hbase-default.xml. HDFS short-circuit reads bypass access to data in HDFS by using a domain socket (file) instead of a network socket. This alleviates the overhead of TCP to read data from HDFS which can have a meaningful improvement on HBase performance (as high as 30-40%).
Users can restore short-circuit reads by explicitly setting dfs.client.read.shortcircuit in HBase configuration via the configuration management tool for their product (e.g. Cloudera Manager or Ambari).
- CDP
- CDH
- HDP
- CDP 7.x
- CDH 6.x
- HDP 3.x
Impact: HBase reads with high data-locality will not execute as fast as previously. HBase random read performance is heavily affected as random reads are expected to have low latency (e.g. Get, Multi-Get). Scan workloads would also be affected, but may be less impacted as latency of scans is greater.
Severity: High
- Cloudera Manager:
HBase → Configurations → HBase (Service-wide) → HBase Service Advanced Configuration Snippet (Safety Valve) for hbase-site.xml→
dfs.client.read.shortcircuit=true
dfs.domain.socket.path=< Add same value which is configured in hdfs-site.xml >
- Ambari:
HBase → CONFIGS → Advanced → Custom hbase-site →
dfs.client.read.shortcircuit=true
dfs.domain.socket.path=< Add same value which is configured in hdfs-site.xml >
After making these configuration changes, restart the HBase service.
Cloudera will continue to pursue product changes which may alleviate the need to make these configuration changes.
For CDP 7.1.1.0 and newer, the metric shortCircuitBytesRead can be viewed for each RegionServer under the RegionServer/Server JMX metrics endpoint. When short circuit reads are not enabled, this metric will be zero. When short circuit reads are enabled and the data locality for this RegionServer is greater than zero, the metric should be greater than zero.
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: TSB 2021-463: HBase Performance Issue
Default limits for PressureAwareCompactionThroughputController are too low
HDP and CDH releases suffer from low compaction throughput limits, which cause storefiles to back up faster than compactions can re-write them. This was originally identified upstream in HBASE-21000.
- HDP
- CDH
- HDP 3.0.0 through HDP 3.1.2
- CDH 6.0.x
- CDH 6.1.x
- CDH 6.2.x
- CDH 6.3.0, 6.3.1, 6.3.2, 6.3.3
Users affected: Users of above mentioned HDP and CDH versions.
Severity: Medium
Impact: For non-read-only workloads, this will eventually cause back-pressure onto new writes when the blocking store files limit is reached.
- Upgrade: Upgrade to the latest release version: CDP 7.1.4, HDP 3.1.5, CDH 6.3.4
- Workaround:
- Set the hbase.hstore.compaction.throughput.higher.bound property to 104857600 and the hbase.hstore.compaction.throughput.lower.bound property to 52428800 in hbase-site.xml.
- An alternative solution is to set the hbase.regionserver.throughput.controller property to org.apache.hadoop.hbase.regionserver.throttle.NoLimitThroughputController which will remove all compaction throughput limitations (which has been observed to cause other pressure).
Apache issue: HBASE-21000
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: Cloudera Customer Advisory: Default limits for PressureAwareCompactionThroughputController are too low
Multiple HBase Services on the Same CDH Cluster is not Supported
Cloudera Manager does not allow to deploy multiple HBase services on the same host of an HDFS cluster as by design a DataNode can only have a single HBase service per host. It is possible to have two HBase services on the same HDFS cluster but they have to be on different DataNodes, meaning that there will be one RegionServer per DataNode per HBase cluster. However, that requires additional configuration, for example you have to pin /hbase_enc and /hbase to avoid the HDFS balancer to cluster. However, that requires additional configuration, for example you have to pin /hbase_enc and /hbase to avoid the HDFS balancer to cause issues with data locality.
If Cloudera Manager is not used, you can manage multiple configurations per host for different RegionServers that are part of different HBase clusters but that can lead to multiple issues and difficult troubleshooting procedures. Thus, Cloudera does not support managing multiple HBase services on the same CDH cluster.
IOException from Timeouts
CDH 5.12.0 includes the fix HBASE-16604, where the internal scanner that retries in case of IOException from timeouts could potentially miss data. Java clients were properly updated to account for the new behavior, but thrift clients will now see exceptions where the previous missing data would be.
Workaround: Create a new scanner and retry the operation when encountering this issue.
IntegrationTestReplication fails if replication does not finish before the verify phase begins
During IntegrationTestReplication, if the verify phase starts before the replication phase finishes, the test will fail because the target cluster does not contain all of the data. If the HBase services in the target cluster does not have enough memory, long garbage-collection pauses might occur.
Workaround: Use the -t flag to set the timeout value before starting verification.
Cloudera Issue: None.
HDFS encryption with HBase
Cloudera has tested the performance impact of using HDFS encryption with HBase. The overall overhead of HDFS encryption on HBase performance is in the range of 3 to 4% for both read and update workloads. Scan performance has not been thoroughly tested.
ExportSnapshot or DistCp operations may fail on the Amazon s3a:// protocol
ExportSnapshot or DistCP operations may fail on AWS when using certain JDK 8 versions, due to an incompatibility between the AWS Java SDK 1.9.x and the joda-time date-parsing module.
Workaround: Use joda-time 2.8.1 or higher, which is included in AWS Java SDK 1.10.1 or higher.
Cloudera Issue: None.
An operating-system level tuning issue in RHEL7 causes significant latency regressions
There are two distinct causes for the regressions, depending on the workload:
- For a cached workload, the regression may be up to 11%, as compared to RHEL6. The cause relates to differences in the CPU's C-state (power saving state) behavior. With the same workload, the CPU is around 40% busier in RHEL7, and the CPU spends more time transitioning between C-states in RHEL7. Transitions out of deeper C-states add latency. When CPUs are configured to never enter a C-state lower than 1, RHEL7 is slightly faster than RHEL6 on the cached workload. The root cause is still under investigation and may be hardware-dependent.
- For an IO-bound workload, the regression may be up to 8%, even with common C-state settings. A 6% difference in average disk service time has been observed, which in turn seems to be caused by a 10% higher average read size at the drive on RHEL7. The read sizes issued by HBase are the same in both cases, so the root cause seems to be a change in the EXT4 filesystem or the Linux block IO later. The root cause is still under investigation.
Bug: None
Severity: Medium
Workaround: Avoid using RHEL 7 if you have a latency-critical workload. For a cached workload, consider tuning the C-state (power-saving) behavior of your CPUs.
Export to Azure Blob Storage (the wasb:// or wasbs:// protocol) is not supported
CDH 5.3 and higher supports Azure Blob Storage for some applications. However, a null pointer exception occurs when you specify a wasb:// or wasbs:// location in the --copy-to option of the ExportSnapshot command or as the output directory (the second positional argument) of the Export command.
Workaround: None.
Apache Issue: HADOOP-12717
AccessController postOperation problems in asynchronous operations
When security and Access Control are enabled, the following problems occur:
- If a Delete Table fails for a reason other than missing permissions, the access rights are removed but the table may still exist and may be used again.
- If hbaseAdmin.modifyTable() is used to delete column families, the rights are not removed from the Access Control List (ACL) table. The postOperation is implemented only for postDeleteColumn().
- If Create Table fails, full rights for that table persist for the user who attempted to create it. If another user later succeeds in creating the table, the user who made the failed attempt still has the full rights.
Workaround: None
Apache Issue: HBASE-6992
Apache Hive/HCatalog/Hive on Spark/Hive Metastore Known Issues
This topic contains:
Hive Known Issues
BDR - Hive restore failing during import
When the table filter used during hive cloud restore is different from the table filter used to create the hive cloud backup, the import step fails with the table not found error. Currently it impacts only the cloud restore scenario.
Products affected: Cloudera Manager
- Cloudera Manager 5.15, 5.16
- Cloudera Manager 6.1.x
- Cloudera Manager 6.2.x
- Cloudera Manager 6.3.x
Users affected: BDR, Hive cloud restore, where restore uses a subset of tables from the exported tables
- Limited, the hive cloud restore all tables works properly.
- The hive cloud restore from the hive cloud backup created prior to Cloudera Manager 5.15 would work without any problem.
- No other BDR functionality is affected.
- Workaround: Not available. Importing specific tables would fail. Impoting ALL tables would continue to work properly.
- Upgrade: Upgrade to a Cloudera Manager version containing the fix.
Addressed in release/refresh/patch: Cloudera Manager 7.0 and higher versions
Query with an empty WHERE clause problematic if vectorization is off
SELECT COUNT (DISTINCT cint) FROM alltypesorc WHERE cstring1; SELECT 1 WHERE 1;
If vectorization is turned on and no rules turn off the vectorization, queries run as expected.
Workaround: Rewrite queries with casts or equals.
Affected Versions: 6.3.x, 6.2.x, 6.1.x, 6.0.x
Apache Issue: HIVE-15408
Cloudera Issue: CDH-81649
Query with DISTINCT can fail if vectorization is on
A query can fail when vectorization is turned on, the query contains DISTINCT, and other rules do not turn off the vectorization. A query-specific error message appears, for example:
Error: Error while compiling statement: FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: The column KEY._col2:0._col0 is not in the vectorization context column map {KEY._col0=0, KEY._col1=1, KEY._col2=2}. (state=42000,code=40000)set hive.vectorized.execution.enabled=false;
Affected Versions: 6.3.x, 6.2.x, 6.1.x, 6.0.x
Apache Issue: HIVE-19032
Cloudera Issue: CDH-81341
When vectorization is enabled on any file type (ORC, Parquet) queries that divide by zero using the modulo operator (%) return an error
When vectorization is enabled for Hive on any file type, including ORC and Parquet, if the query divides by zero using the modulo operator (%), it returns the following error: Arithmetic exception [divide by] 0. For example, if you run the following query this issue is triggered: SELECT 100 % column_c1 FROM table_t1; and the value in column_c1 is zero. The divide operator (/) is not affected by this issue.
Workaround: Disable vectorization for the query that is triggering this at either the session level by using the SET statement or at the server level by disabling the property with Cloudera Manager. For information about how to enable or disable query vectorization, see Enabling Hive Query Vectorization.
Affected Versions: When query vectorization is enabled for Hive, this issue affects Hive ORC tables in all versions of CDH and affects Hive Parquet tables in CDH 6.0 and later
Apache Issue: HIVE-19564
Cloudera Issue: CDH-71211
When vectorization is enabled for Hive on any file type (ORC, Parquet) queries that perform comparisons in the SELECT clause on large values in columns with the data type of BIGINT might return wrong results
When vectorization is enabled for Hive on any file type, including ORC and Parquet, if the query performs a comparison operation between very large values in columns that are BIGINT data types in the SELECT clause of the query, incorrect results might be returned. Comparison operators include ==, !=, <, <=, >, and >=. This issue does not occur when the comparison operation is performed in the filtering clause of the query. This issue can also occur when the difference of values in such columns is out of range for a LONG (64-bit) data type. For example, if column_c1 stores 8976171455044006767 and column_c2 stores -7272907770454997143, a query such as SELECT column_c1 < column_c2 FROM table_test returns true instead of false because the difference (8976171455044006767 - (-7272907770454997143)) is 1.6249079225499E19 which is greater than 9.22337203685478E18, which is the maximum possible value that a LONG (64-bit) data type can hold.
Workaround: Use a DECIMAL type instead of BIGINT for columns that might contain very large values. Another option is to disable vectorization for the query that is triggering this at either the session level by using the SET statement or at the server level by disabling the property with Cloudera Manager. For information about how to enable or disable query vectorization, see Enabling Hive Query Vectorization.
Affected Versions: When query vectorization is enabled for Hive, this issue affects Hive ORC tables in all versions of CDH and affects Hive Parquet tables in CDH 6.0 and later
Apache Issue: HIVE_20207
Cloudera Issue: CDH-70996
Specified column position in the ORDER BY clause is not supported for SELECT * queries
CREATE TABLE decimal_1 (id decimal(5,0));
SELECT * FROM decimal_1 ORDER BY 1 limit 100;
Error while compiling statement: FAILED: SemanticException [Error 10219]: Position in ORDER BY is not supported when using SELECT *
Instead the query must list out the columns it is selecting.Affected Versions: CDH 6.0.0 and higher
Cloudera Issue: CDH-68550
DirectSQL with PostgreSQL
Hive doesn't support Hive direct SQL queries with PostgreSQL database. It only supports this feature with MySQL, MariaDB, and Oracle. With PostgresSQL, direct SQL is disabled as a precaution, since there have been issues reported upstream where it is not possible to fallback on DataNucleus in the event of some failures, plus other non-standard behaviors. For more information, see Hive Configuration Properties.
Affected Versions: All CDH versions
Cloudera Issue: CDH-49017
ALTER PARTITION … SET LOCATION does not work on Amazon S3 or between S3 and HDFS
Cloudera recommends that you do not use ALTER PARTITION … SET LOCATION on S3 or between S3 and HDFS. The rest of the ALTER PARTITION commands work as expected.
Affected Versions: All CDH versions
Cloudera Issue: CDH-42420
Cannot create archive partitions with external HAR (Hadoop Archive) tables
ALTER TABLE ... ARCHIVE PARTITION is not supported on external tables.
Affected Versions: All CDH versions
Cloudera Issue: CDH-9638
Object types Server and URI are not supported in "SHOW GRANT ROLE roleName on OBJECT objectName" statements
Workaround: Use SHOW GRANT ROLE roleNameto list all privileges granted to the role.
Affected Versions: All CDH versions
Cloudera Issue: CDH-19430
Change in Precision of trigonometric functions for Hive Queries with JDK 11
If your Hive queries use trigonometric functions (such as degrees-to-radians, radians-to-degrees, or sin) there may be a difference in the output of the 15th decimal place.
Cloudera Bug: CDH-81322
Logging differences create Supportability Issues
In the event you need Apache Hive support from Cloudera, the availability of logs is critical. Some CDH releases do not enable log4j2 logging for Hive by default. Because of this, logs are not generated. Furthermore, the specified CDH releases are not configured to remove old log files to make room for new ones. This can cause the new logs to be lost. When Hive logs are missing, Support cannot troubleshoot Hive problems efficiently.
Components affected: Hive
Products affected: Hive
- CDH 6.1
- CDH 6.2
- CDH 6.3
Users affected: Hive users
Severity: Medium
Impact: The absence of Hive log files causes delays in troubleshooting Hive problems.
- Open Cloudera Manager.
- Select .
- Click the Configuration tab.
- In the Search field, enter Hive Metastore Server Logging Advanced Configuration Snippet (Safety Valve).
- Add the following XML to the field (or switch to Editor mode, and enter each property and its value in the fields provided).
<property> <name>rootLogger.appenderRefs</name> <value>root, console, DRFA, PerfLogger</value> </property> <property> <name>logger.PerfLogger.name</name> <value>org.apache.hadoop.hive.ql.log.PerfLogger</value> </property> <property> <name>logger.PerfLogger.level</name> <value>DEBUG</value> </property> <property> <name>appender.DRFA.filePattern</name> <value>${log.dir}/${log.file}.%i</value> </property> <property> <name>appender.DRFA.strategy.fileIndex</name> <value>min</value> </property> - In the Search field, enter HiveServer2 Logging Advanced Configuration Snippet (Safety Valve).
- Add the XML properties from step 5.
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: TSB 2020-384: Logging differences in CDH 6 create Supportability Issues
HCatalog Known Issues
There are no notable known issues in this release of HCatalog.
Hive on Spark (HoS) Known Issues
A query fails with IllegalArgumentException Size requested for unknown type: java.util.Collection
WITH t2 AS (SELECT array(1,2) AS c1 UNION ALL SELECT array(2,3) AS c1) SELECT collect_list(c1) FROM t2
Workaround: Create a table to store the array data.
Affected Versions: 6.3.x, 6.2.x, 6.1.x
Cloudera Issue: CDH-80169
Hive on Spark queries fail with "Timed out waiting for client to connect" for an unknown reason
If this exception is preceded by logs of the form "client.RpcRetryingCaller: Call exception...", then this failure is due to an unavailable HBase service. On a secure cluster, spark-submit will try to obtain delegation tokens from HBase, even though Hive on Spark might not need them. So if HBase is unavailable, spark-submit throws an exception.
Workaround: Fix the HBase service, or set spark.yarn.security.tokens.hbase.enabled to false.
Affected Versions: CDH 5.7.0 and higher
Cloudera Issues: CDH-59591, CDH-59599
Hive Metastore Known Issues
HMS Read Authorization: get_num_partitions_by_filter Ignores Authorization
A user can get the number of partitions of a table regardless of the user's permissions
Hue Known Issues
The following sections describe known issue and workaround in Hue, as of the current production release.
Continue reading:
- Cloudera Hue is vulnerable to Cross-Site Scripting attacks
- High DDL usage in Hue Impala Editor may issue flood of INVALIDATE Calls
- Invalid S3 URI error while accessing S3 bucket
- Error while rerunning Oozie workflow
- Table Browser Must Be Refreshed to View Tables Created with the Data Import Wizard
- Hue does not support the Spark App
Cloudera Hue is vulnerable to Cross-Site Scripting attacks
-
CVE-2021-29994 - The Add Description field in the Table schema browser does not sanitize user inputs as expected.
-
CVE-2021-32480 - Default Home direct button in Filebrowser is also susceptible to XSS attack.
-
CVE-2021-32481 - The Error snippet dialog of the Hue UI does not sanitize user inputs.
Products affected: Hue
-
CDP Public Cloud 7.2.10 and lower
-
CDP Private Cloud Base 7.1.6 and lower
-
CDP Private Cloud Plus 1.2 and lower (NOTE: CDP Private Cloud Plus was renamed to CDP Private Cloud Experiences for version 1.2)
-
Cloudera Data Warehouse (DWX) 1.1.2-b1484 (CDH 7.2.11.0-59) or lower
-
CDH 6.3.4 and lower
User affected: All users of the affected versions
- CVE-2021-29994 - 5.5 (Medium) CVSS:3.1/AV:N/AC:L/PR:L/UI:R/S:U/C:L/I:L/A:L
- CVE-2021-32480 - 5.5 (Medium) CVSS:3.1/AV:N/AC:L/PR:L/UI:R/S:U/C:L/I:L/A:L
- CVE-2021-32481 - 5.5 (Medium) CVSS:3.1/AV:N/AC:L/PR:L/UI:R/S:U/C:L/I:L/A:L
Severity (Low/Medium/High): Medium
Impact:Security Vulnerabilities as mentioned in the CVEs
- Upgrade (recommended):
-
CDP Public Cloud users should upgrade to 7.2.11
-
CDP Private Cloud Base users should upgrade to CDP 7.1.7
-
CDP Private Cloud Plus users should upgrade to CDP PVC 1.3
-
Cloudera Data Warehouse users should upgrade to the latest version DWX1.1.2-b1793 & CDH 2021.0.1-b10
-
CDH users should request a patch
-
High DDL usage in Hue Impala Editor may issue flood of INVALIDATE Calls
Issuing DDL statements using Hue’s Impala editor or invoking Hue’s “Refresh Cache” function in the left-side metadata browser results in Hue issuing INVALIDATE METADATA calls to the Impala service. This call is expensive and can result in a significant system impact, up to and including full system outage, when repeated in sufficient volume. This has been corrected in HUE-8882.
- Hue
- Impala
- Cloudera Enterprise 5
- Cloudera Enterprise 6
- CDH 5.15.1, 5.15.2
- CDH 5.16.x
- CDH 6.1.1
- CDH 6.2.x
- CDH 6.3.0, 6.3.1, 6.3.2, 6.3.3
Users affected: End-users using Impala editor in Hue.
Severity: High
Impact: Users running DDL statements using the Hue Impala editor or invoking Hue’s Refresh Cache function causes INVALIDATE METADATA commands to be sent to Impala. Impala’s metadata invalidation is an expensive operation and could cause impact on the performance of subsequent queries, hence leading to the potential for significant impact on the entire cluster, including the potential for whole-system outage.
- CDH 6.x customers: Upgrade to CDH 6.3.4 that contains the fix.
- CDH 5.x customers: Contact Cloudera Support for further assistance.
Apache issue: HUE-8882
Knowledge article: For the latest update on this issue see the corresponding Knowledge article: Cloudera Customer Advisory: High DDL usage in Hue Impala Editor may issue flood of INVALIDATE Calls
Invalid S3 URI error while accessing S3 bucket
The Hue Load Balancer merges the double slashes (//) in the S3 URI into a single slash (/) so that the URI prefix "/filebrowser/view=S3A://" is changed to "/filebrowser/view=S3A:/". This results in an error when you try to access the S3 buckets from the Hue File Browser through the port 8889.
The Hue web UI displays the following error: “Unknown error occurred”.
The Hue server logs record the “ValueError: Invalid S3 URI: S3A” error.
Workaround:
- Sign in to Cloudera Manager as an Administrator.
- Go to and search for the Load Balancer Advanced Configuration Snippet (Safety Valve) for httpd.conf field.
- Specify MergeSlashes OFF in the Load Balancer Advanced Configuration Snippet (Safety Valve) for httpd.conf field.
- Click Save Changes.
- Restart the Hue Load Balancer.
You should be able to load the S3 browser from both 8888 and 8889 ports.
Alternatively, you can use the Hue server port 8888 instead of the load balancer port 8889 to resolve this issue.
Error while rerunning Oozie workflow
You may see an error such as the following while rerunning an an already executed and finished Oozie workflow through the Hue web interface: E0504: App directory [hdfs:/cdh/user/hue/oozie/workspaces/hue-oozie-1571929263.84] does not exist.
Workaround:
- Sign in to Cloudera Manager as an Administrator.
- Go to and search for the Load Balancer Advanced Configuration Snippet (Safety Valve) for httpd.conf field.
- Specify MergeSlashes OFF in the Load Balancer Advanced Configuration Snippet (Safety Valve) for httpd.conf field.
- Click Save Changes.
- Restart the Hue Load Balancer.
Table Browser Must Be Refreshed to View Tables Created with the Data Import Wizard
When you create a new table from a file by using the Data Import Wizard, the newly created table columns do not display in the Table Browser until you refresh it.
For example:
-
Create a table from the sample file web_logs_2.csv by clicking the plus sign in the left panel, which launches the Data Import Wizard:
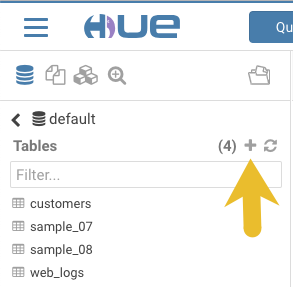
-
After you define the table, click Submit to generate the new table:
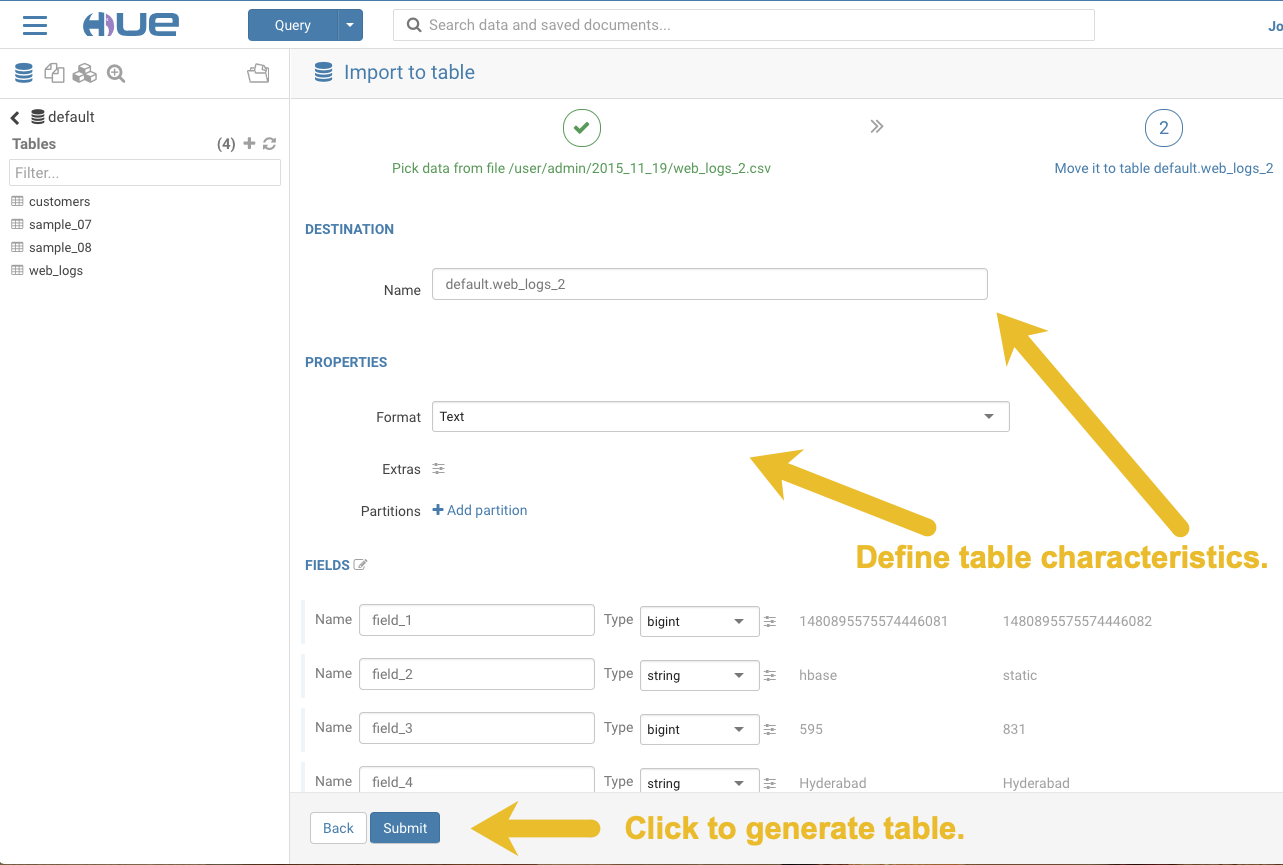
-
After you generate the new table, you can see it listed on the left assist panel, but when you click the table name to display the columns, an error displays:
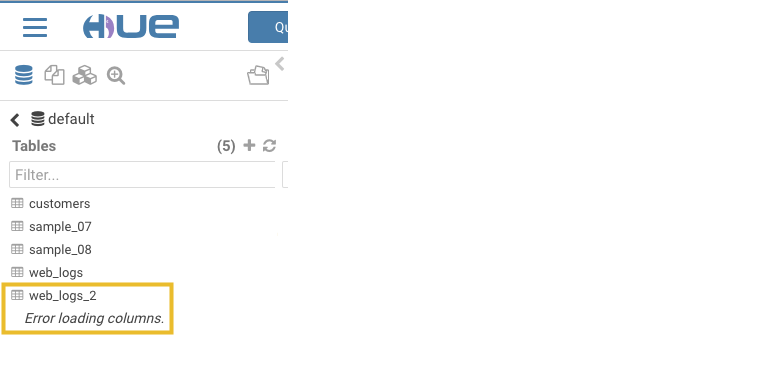
Workaround:
-
Click the information icon that is adjacent to the new table:
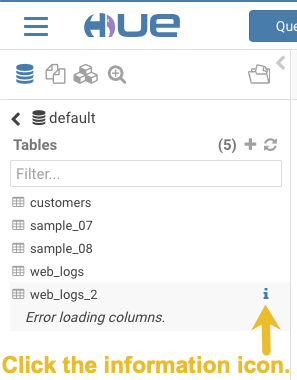
-
In the information window that opens, click the refresh icon in the upper right corner to view the table columns:
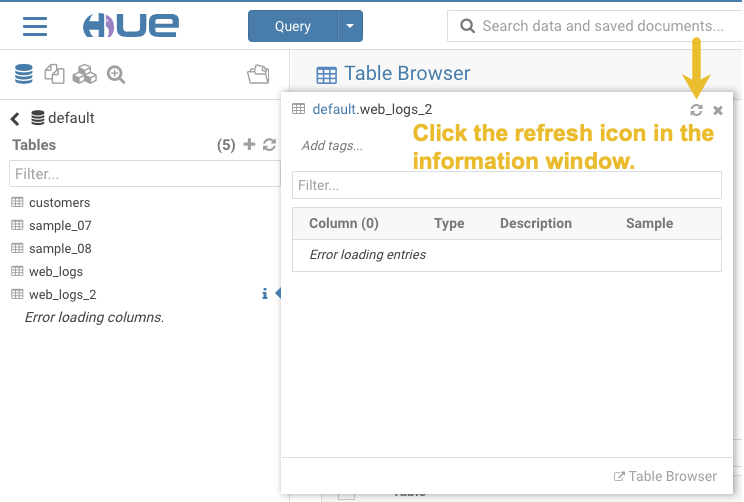
Using the refresh icon in the information window is the least expensive way to refresh the page so performance is not affected.
Affected Version(s): CDH 6.2.0
Cloudera Issue:CDH-77238
Hue does not support the Spark App
Hue does not currently support the Spark application.
Apache Impala Known Issues
The following sections describe known issues and workarounds in Impala, as of the current production release. This page summarizes the most serious or frequently encountered issues in the current release, to help you make planning decisions about installing and upgrading. Any workarounds are listed here. The bug links take you to the Impala issues site, where you can see the diagnosis and whether a fix is in the pipeline.
Continue reading:
- Impala Known Issues: Startup
- Impala Known Issues: Crashes and Hangs
- Impala Known Issues: Performance
- Impala Known Issues: Security
- Impala Known Issues: Resources
- Impala Known Issues: Correctness
- Impala Known Issues: Interoperability
- Impala Known Issues: Limitations
- Impala Known Issues: Miscellaneous / Older Issues
Impala Known Issues: Startup
These issues can prevent one or more Impala-related daemons from starting properly.
Impala requires FQDN from hostname command on kerberized clusters
The method Impala uses to retrieve the host name while constructing the Kerberos principal is the gethostname() system call. This function might not always return the fully qualified domain name, depending on the network configuration. If the daemons cannot determine the FQDN, Impala does not start on a kerberized cluster.
Workaround: Test if a host is affected by checking whether the output of the hostname command includes the FQDN. On hosts where hostname, only returns the short name, pass the command-line flag --hostname=fully_qualified_domain_name in the startup options of all Impala-related daemons.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-4978
Impala Known Issues: Crashes and Hangs
These issues can cause Impala to quit or become unresponsive.
Unable to view large catalog objects in catalogd Web UI
In catalogd Web UI, you can list metadata objects and view their details. These details are accessed via a link and printed to a string formatted using thrift's DebugProtocol. Printing large objects (> 1 GB) in Web UI can crash catalogd.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-6841
Impala Known Issues: Performance
These issues involve the performance of operations such as queries or DDL statements.
Metadata operations block read-only operations on unrelated tables
Metadata operations that change the state of a table, like COMPUTE STATS or ALTER RECOVER PARTITIONS, may delay metadata propagation of unrelated unloaded tables triggered by statements like DESCRIBE or SELECT queries.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-6671
Impala Known Issues: Security
These issues relate to security features, such as Kerberos authentication, Sentry authorization, encryption, auditing, and redaction.
Impala logs the session / operation secret on most RPCs at INFO level
Impala logs contain the session / operation secret. With this information a person who has access to the Impala logs might be able to hijack other users' sessions. This means the attacker is able to execute statements for which they do not have the necessary privileges otherwise. Impala deployments where Apache Sentry or Apache Ranger authorization is enabled may be vulnerable to privilege escalation. Impala deployments where audit logging is enabled may be vulnerable to incorrect audit logging.
Restricting access to the Impala logs that expose secrets will reduce the risk of an attack. Additionally, restricting access to trusted users for the Impala deployment will also reduce the risk of an attack. Log redaction techniques can be used to redact secrets from the logs. For more information, see the Cloudera Manager documentation.
For log redaction, users can create a rule with a search pattern: secret \(string\) [=:].*And the replacement could be for example: secret=LOG-REDACTED
This vulnerability is fixed upstream under IMPALA-10600
.
-
CDP Private Cloud Base
-
CDP Public Cloud
-
CDH
-
CDP Private Cloud Base 7.0.3, 7.1.1, 7.1.2, 7.1.3, 7.1.4, 7.1.5 and 7.1.6
- CDP Public Cloud 7.0.0, 7.0.1, 7.0.2, 7.1.0, 7.2.0, 7.2.1, 7.2.2, 7.2.6, 7.2.7, and 7.2.8
-
All CDH 6.3.4 and lower releases
Users affected: Impala users of the affected releases
Severity (Low/Medium/High): 7.5 (High) CVSS:3.1/AV:N/AC:H/PR:L/UI:N/S:U/C:H/I:H/A:H
Impact: Unauthorized access
CVE: CVE-2021-28131
Immediate action required:Upgrade to a CDP Private Cloud Base or CDP Public Cloud version containing the fix.
-
CDP Private Cloud Base 7.1.7
-
CDP Public Cloud 7.2.9 or higher versions
Impala does not support Heimdal Kerberos
Heimdal Kerberos is not supported in Impala.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-7072
System-wide auth-to-local mapping not applied correctly to Kudu service account
Due to system auth_to_local mapping, the principal may be mapped to some local name.
When running with Kerberos enabled, you may hit the following error message where <random-string> is some random string which doesn't match the primary in the Kerberos principal.
WARNINGS: TransmitData() to X.X.X.X:27000 failed: Remote error: Not authorized: {username='<random-string>', principal='impala/redacted'} is not allowed to access DataStreamService
Workaround: Start Impala with the --use_system_auth_to_local=false flag to ignore the system-wide auth_to_local mappings configured in /etc/krb5.conf.
Affected Versions: CDH 5.15, CDH 6.1 and higher
Apache Issue: KUDU-2198
Impala Known Issues: Resources
These issues involve memory or disk usage, including out-of-memory conditions, the spill-to-disk feature, and resource management features.
Handling large rows during upgrade to CDH 5.13 / Impala 2.10 or higher
After an upgrade to CDH 5.13 / Impala 2.10 or higher, users who process very large column values (long strings), or have increased the --read_size configuration setting from its default of 8 MB, might encounter capacity errors for some queries that previously worked.
Resolution: After the upgrade, follow the instructions in Handling Large Rows During Upgrade to CDH 5.13 / Impala 2.10 or Higher to check if your queries are affected by these changes and to modify your configuration settings if so.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-6028
Configuration to prevent crashes caused by thread resource limits
Impala could encounter a serious error due to resource usage under very high concurrency. The error message is similar to:
F0629 08:20:02.956413 29088 llvm-codegen.cc:111] LLVM hit fatal error: Unable to allocate section memory! terminate called after throwing an instance of 'boost::exception_detail::clone_impl<boost::exception_detail::error_info_injector<boost::thread_resource_error> >'
Workaround:
In CDH 6.0 and lower versions of CDH, configure each host running an impalad daemon with the following settings:
echo 2000000 > /proc/sys/kernel/threads-max echo 2000000 > /proc/sys/kernel/pid_max echo 8000000 > /proc/sys/vm/max_map_count
In CDH 6.1 and higher versions, it is unlikely that you will hit the thread resource limit. Configure each host running an impalad daemon with the following setting:
echo 8000000 > /proc/sys/vm/max_map_count
- Add the following line to /etc/sysctl.conf:
vm.max_map_count=8000000
- Run the following command:
sysctl -p
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-5605
Breakpad minidumps can be very large when the thread count is high
The size of the breakpad minidump files grows linearly with the number of threads. By default, each thread adds 8 KB to the minidump size. Minidump files could consume significant disk space when the daemons have a high number of threads.
Workaround: Add --minidump_size_limit_hint_kb=size to set a soft upper limit on the size of each minidump file. If the minidump file would exceed that limit, Impala reduces the amount of information for each thread from 8 KB to 2 KB. (Full thread information is captured for the first 20 threads, then 2 KB per thread after that.) The minidump file can still grow larger than the "hinted" size. For example, if you have 10,000 threads, the minidump file can be more than 20 MB.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-3509
Process mem limit does not account for the JVM's memory usage
Some memory allocated by the JVM used internally by Impala is not counted against the memory limit for the impalad daemon.
Workaround: To monitor overall memory usage, use the top command, or add the memory figures in the Impala web UI /memz tab to JVM memory usage shown on the /metrics tab.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-691
Impala Known Issues: Correctness
These issues can cause incorrect or unexpected results from queries. They typically only arise in very specific circumstances.
Incorrect result due to constant evaluation in query with outer join
explain SELECT 1 FROM alltypestiny a1 INNER JOIN alltypesagg a2 ON a1.smallint_col = a2.year AND false RIGHT JOIN alltypes a3 ON a1.year = a1.bigint_col; +---------------------------------------------------------+ | Explain String | +---------------------------------------------------------+ | Estimated Per-Host Requirements: Memory=1.00KB VCores=1 | | | | 00:EMPTYSET | +---------------------------------------------------------+
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-3094
% escaping does not work correctly in a LIKE clause
If the final character in the RHS argument of a LIKE operator is an escaped \% character, it does not match a % final character of the LHS argument.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-2422
Crash: impala::Coordinator::ValidateCollectionSlots
A query could encounter a serious error if includes multiple nested levels of INNER JOIN clauses involving subqueries.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-2603
Impala Known Issues: Interoperability
These issues affect the ability to interchange data between Impala and other systems. They cover areas such as data types and file formats.
Queries Stuck on Failed HDFS Calls and not Timing out
In CDH 6.2 / Impala 3.2 and higher, if the following error appears multiple times in a short duration while running a query, it would mean that the connection between the impalad and the HDFS NameNode is in a bad state and hence the impalad would have to be restarted:
"hdfsOpenFile() for <filename> at backend <hostname:port> failed to finish before the <hdfs_operation_timeout_sec> second timeout "
In CDH 6.1 / Impala 3.1 and lower, the same issue would cause Impala to wait for a long time or hang without showing the above error message.
Workaround: Restart the impalad in the bad state.
Affected Versions: All versions of Impala
Apache Issue: HADOOP-15720
Configuration needed for Flume to be compatible with Impala
For compatibility with Impala, the value for the Flume HDFS Sink hdfs.writeFormat must be set to Text, rather than its default value of Writable. The hdfs.writeFormat setting must be changed to Text before creating data files with Flume; otherwise, those files cannot be read by either Impala or Hive.
Resolution: This information has been requested to be added to the upstream Flume documentation.
Affected Versions: All CDH 6 versions
Cloudera Issue: CDH-13199
Avro Scanner fails to parse some schemas
The default value in Avro schema must match the first union type. For example, if the default value is null, then the first type in the UNION must be "null".
Workaround: Swap the order of the fields in the schema specification. For example, use ["null", "string"] instead of ["string", "null"]. Note that the files written with the problematic schema must be rewritten with the new schema because Avro files have embedded schemas.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-635
Impala BE cannot parse Avro schema that contains a trailing semi-colon
If an Avro table has a schema definition with a trailing semicolon, Impala encounters an error when the table is queried.
Workaround: Remove trailing semicolon from the Avro schema.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-1024
Incorrect results with basic predicate on CHAR typed column
When comparing a CHAR column value to a string literal, the literal value is not blank-padded and so the comparison might fail when it should match.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-1652
Impala Known Issues: Limitations
These issues are current limitations of Impala that require evaluation as you plan how to integrate Impala into your data management workflow.
Set limits on size of expression trees
Very deeply nested expressions within queries can exceed internal Impala limits, leading to excessive memory usage.
Workaround: Avoid queries with extremely large expression trees. Setting the query option disable_codegen=true may reduce the impact, at a cost of longer query runtime.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-4551
Impala does not support running on clusters with federated namespaces
Impala does not support running on clusters with federated namespaces. The impalad process will not start on a node running such a filesystem based on the org.apache.hadoop.fs.viewfs.ViewFs class.
Workaround: Use standard HDFS on all Impala nodes.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-77
Hue and BDR require separate parameters for Impala Load Balancer
Cloudera Manager supports a single parameter for specifying the Impala Daemon Load Balancer. However, because BDR and Hue need to use different ports when connecting to the load balancer, it is not possible to configure the load balancer value so that BDR and Hue will work correctly in the same cluster.
Workaround: To configure BDR with Impala, use the load balancer configuration either without a port specification or with the Beeswax port.
To configure Hue, use the Hue Server Advanced Configuration Snippet (Safety Valve) for impalad_flags to specify the load balancer address with the HiveServer2 port.
Affected Versions: CDH versions from 5.11 to 6.0.1
Cloudera Issue: OPSAPS-46641
Impala Known Issues: Miscellaneous / Older Issues
These issues do not fall into one of the above categories or have not been categorized yet.
Unable to Correctly Parse the Terabyte Unit
Impala does not support parsing strings that contain "TB" when used as a unit for terabytes. The flags related to memory limits may be affected, such as the flags for scratch space and data cache.
Workaround: Use other supported units to specify values, e.g. GB or MB.
Affected Versions: CDH 6.3.x and lower versions
Fixed Versions: CDH 6.4.0
Apache Issue: IMPALA-8829
A failed CTAS does not drop the table if the insert fails
If a CREATE TABLE AS SELECT operation successfully creates the target table but an error occurs while querying the source table or copying the data, the new table is left behind rather than being dropped.
Workaround: Drop the new table manually after a failed CREATE TABLE AS SELECT.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-2005
Casting scenarios with invalid/inconsistent results
Using a CAST function to convert large literal values to smaller types, or to convert special values such as NaN or Inf, produces values not consistent with other database systems. This could lead to unexpected results from queries.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-1821
Impala should tolerate bad locale settings
If the LC_* environment variables specify an unsupported locale, Impala does not start.
Workaround: Add LC_ALL="C" to the environment settings for both the Impala daemon and the Statestore daemon. See Modifying Impala Startup Options for details about modifying these environment settings.
Resolution: Fixing this issue would require an upgrade to Boost 1.47 in the Impala distribution.
Affected Versions: All CDH 6 versions
Apache Issue: IMPALA-532
EMC Isilon Known Issues
CDH 6.0 is not currently supported on EMC Isilon.
Affected Versions: All CDH 6 versions
Fixed Versions: CDH 6.3.1
Apache Kafka Known Issues
The following sections describe known issues and workarounds in Kafka, as of the current production release.
Topics Created with the "kafka-topics" Tool Might Not Be Secured
Topics that are created and deleted via Kafka are secured (for example, auto created topics). However, most topic creation and deletion is done via the kafka-topics tool, which talks directly to ZooKeeper or some other third-party tool that talks directly to ZooKeeper. Because security is the responsibility of ZooKeeper authorization and authentication, Kafka cannot prevent users from making ZooKeeper changes. Anyone with access to ZooKeeper can create and delete topics. They will not be able to describe, read, or write to the topics even if they can create them.
- kafka-topics.sh
- kafka-configs.sh
- kafka-preferred-replica-election.sh
- kafka-reassign-partitions.sh
"offsets.topic.replication.factor" Must Be Less Than or Equal to the Number of Live Brokers
The offsets.topic.replication.factor broker configuration is now enforced upon auto topic creation. Internal auto topic creation will fail with a GROUP_COORDINATOR_NOT_AVAILABLE error until the cluster size meets this replication factor requirement.
Requests Fail When Sending to a Nonexistent Topic with "auto.create.topics.enable" Set to True
The first few produce requests fail when sending to a nonexistent topic with auto.create.topics.enable set to true.
Workaround: Increase the number of retries in the Producer configuration setting retries.
Custom Kerberos Principal Names Cannot Be Used for Kerberized ZooKeeper and Kafka instances
When using ZooKeeper authentication and a custom Kerberos principal, Kerberos-enabled Kafka does not start.
Workaround: None. You must disable ZooKeeper authentication for Kafka or use the default Kerberos principals for ZooKeeper and Kafka.
Performance Degradation When SSL Is Enabled
Significant performance degradation can occur when SSL is enabled. The impact varies depending on your CPU, JVM version, and message size. Consumers are typically more affected than producers.
Workaround: Configure brokers and clients with ssl.secure.random.implementation = SHA1PRNG. It often reduces this degradation drastically, but its effect is CPU and JVM dependent.
Affected Versions: CDK 2.x and later
Fixed Versions: None
Apache Issue: KAFKA-2561
Cloudera Issue: None
Kafka Garbage Collection Logs are Written to the Process Directory
MirrorMaker Does Not Start When Sentry is Enabled
When MirrorMaker is used in conjunction with Sentry, MirrorMaker reports an authorization issue and does not start. This is due to Sentry being unable to authorize the kafka_mirror_maker principal which is automatically created.
- Create the kafka_mirror_maker Linux user ID and the kafka_mirror_maker Linux group ID on the MirrorMaker hosts. Use the
following command:
useradd kafka_mirror_maker
- Create the necessary Sentry rules for the kafka_mirror_maker group.
Affected Versions: CDH 6.0.0 and later
Fixed Versions: N/A
Apache Issue: N/A
Cloudera Issue: CDH-53706
Apache Kudu Known Issues
The following sections describe known issues and workarounds in Kudu, as of the current production release.
Kudu tablet server might crash in certain workflows where a tablet is dropped right after ALTER TABLE statement
DDL and DML operations can accumulate in the Kudu tablet replica's write ahead log (WAL) during normal operation. Upon the shutdown of a tablet replica (for example, right before removing the replica), information on the accumulated operations (first 50) are printed into the tablet server's INFO log file.
A bug was introduced with the fix for KUDU-2690. The code contains a flipped if-condition that results in de-referencing of an invalid pointer while reporting on a pending ALTER TABLE operation in the tablet replica's WAL. The issue manifests itself in kudu-tserver processes crashing with SIGSEGV (segmentation fault).
The occurrence of the issue is limited to scenarios which result in accumulating at least one pending ALTER TABLE operation in the tablet replica's WAL at the time when the tablet replica is shut down. An example scenario is an ALTER TABLE request (for example, adding a column) immediately followed by a request to drop a tablet (for example, drop a range partition). Another example scenario is shutting down a tablet server while it's still processing an ALTER TABLE request for one of its tablet replicas. A slowness in file system operations increases the chances for the issue to manifest itself.
Apache issue: KUDU-2690
Component affected: Kudu
Products affected: CDH
- CDH 6.2.0, 6.2.1
- CDH 6.3.0, 6.3.1, 6.3.2, 6.3.3
Users affected: Kudu clusters with the impacted releases.
Impact:In the worst case, multiple kudu-tserver processes can crash in a Kudu cluster, making data unavailable until the affected tablet servers are started back.
Severity: High
- Workaround: Avoid dropping range partitions and tablets right after issuing ALTER TABLE request. Wait for the pending ALTER TABLE requests to complete before dropping tablets or shutting down tablet servers.
- Solution: Upgrade to CDH 6.3.4 or CDP
Knowledge article: For the latest update on this issue see the corresponding Knowledge article:
You get "The user 'kudu' is not part of group 'hive' on the following hosts: " warning by the Host Inspector
If you are using fine grained authorization for Kudu, and you are also using Kudu-HMS integration with HDFS-Sentry sync, then you may get the "The user 'kudu' is not part of group 'hive' on the following hosts: " warning while upgrading to CDH 6.3.
usermod -aG hive kudu
Affected Versions: CDH 6.3 / Kudu 1.10
Longer Startup Times with a Large Number of Tablets
If a tablet server has a very large number of tablets, it may take several minutes to start up. It is recommended to limit the number of tablets per server to 1000 or fewer. The maximum allowed number of tablets is 2000 per server. Consider this limitation when pre-splitting your tables. If you notice slow start-up times, you can monitor the number of tablets per server in the web UI.
Affected Versions: All CDH 6 versions
Descriptions for Kudu TLS/SSL Settings in Cloudera Manager
Use the descriptions in the following table to better understand the TLS/SSL settings in the Cloudera Manager Admin Console.
| Field | Usage Notes |
|---|---|
| Kerberos Principal | Set to the default principal, kudu. |
| Enable Secure Authentication And Encryption | Select this checkbox to enable authentication and RPC encryption between all Kudu clients and servers, as well as between individual servers. Only enable this property after you have configured Kerberos. |
| Master TLS/SSL Server Private Key File (PEM Format) | Set to the path containing the Kudu master host's private key (PEM-format). This is used to enable TLS/SSL encryption (over HTTPS) for browser-based connections to the Kudu master web UI. |
| Tablet Server TLS/SSL Server Private Key File (PEM Format) | Set to the path containing the Kudu tablet server host's private key (PEM-format). This is used to enable TLS/SSL encryption (over HTTPS) for browser-based connections to Kudu tablet server web UIs. |
| Master TLS/SSL Server Certificate File (PEM Format) | Set to the path containing the signed certificate (PEM-format) for the Kudu master host's private key (set in Master TLS/SSL Server Private Key File). The certificate file can be created by concatenating all the appropriate root and intermediate certificates required to verify trust. |
| Tablet Server TLS/SSL Server Certificate File (PEM Format) | Set to the path containing the signed certificate (PEM-format) for the Kudu tablet server host's private key (set in Tablet Server TLS/SSL Server Private Key File). The certificate file can be created by concatenating all the appropriate root and intermediate certificates required to verify trust. |
| Master TLS/SSL Server CA Certificate (PEM Format) | Disregard this field. |
| Tablet Server TLS/SSL Server CA Certificate (PEM Format) | Disregard this field. |
| Enable TLS/SSL for Master Server | Enables HTTPS encryption on the Kudu master web UI. |
| Enable TLS/SSL for Tablet Server | Enables HTTPS encryption on the Kudu tablet server web UIs. |
Affected Versions: All CDH 6 versions
Apache Oozie Known Issues
The following sections describe known issues and workarounds in Oozie, as of the current production release.
Oozie jobs fail (gracefully) on secure YARN clusters when JobHistory server is down
If the JobHistory server is down on a YARN (MRv2) cluster, Oozie attempts to submit a job, by default, three times. If the job fails, Oozie automatically puts the workflow in a SUSPEND state.
Workaround: When the JobHistory server is running again, use the resume command to tell Oozie to continue the workflow from the point at which it left off.
Affected Versions: CDH 5 and higher
Cloudera Issue: CDH-14623
Apache Parquet Known Issues
There are no known issues in this release.
Apache Pig Known Issues
There are no known issues in this release.
Cloudera Search Known Issues
The following sections describe known issues and limitations in Search, as of the current production release.
Splitshard of HDFS index checks local filesystem and fails
When performing a shard split on an index that is stored on HDFS, SplitShardCmd still evaluates free disk space on the local file system of the server where Solr is installed. This may cause the command to fail, perceiving that there is no adequate disk space to perform the shard split.
Workaround: None
Affected versions: All
Default Solr core names cannot be changed (limitation)
Although it is technically possible to give user-defined Solr core names during core creation, it is to be avoided in te context of Cloudera Search. Cloudera Manager expects core names in the default "collection_shardX_replicaY" format. Altering core names results in Cloudera Manager being unable to fetch Solr metrics for the given core and this, eventually, may corrupt data collection for co-located core, or even shard and server level charts.
Solr SQL, Graph, and Stream Handlers are Disabled if Collection Uses Document-Level Security
The Solr SQL, Graph, and Stream handlers do not support document-level security, and are disabled if document-level security is enabled on the collection. If necessary, these handlers can be re-enabled by setting the following Java system properties, but document-level security is not enforced for these handlers:
- SQL: solr.sentry.enableSqlQuery=true
- Graph: solr.sentry.enableGraphQuery=true
- Stream: solr.sentry.enableStreams=true
Workaround: None
Affected Versions: All CDH 6 releases
Cloudera Issue: CDH-66345
Collection Creation No Longer Supports Automatically Selecting A Configuration If Only One Exists
Before CDH 5.5.0, a collection could be created without specifying a configuration. If no -c value was specified, then:
- If there was only one configuration, that configuration was chosen.
- If the collection name matched a configuration name, that configuration was chosen.
Search for CDH 5.5.0 includes multiple built-in configurations. As a result, there is no longer a case in which only one configuration can be chosen by default.
Workaround: Explicitly specify the collection configuration to use by passing -c <configName> to solrctl collection --create.
Affected Versions: CDH 5.5.0 and higher
Cloudera Issue: CDH-34050
CrunchIndexerTool which includes Spark indexer requires specific input file format specifications
If the --input-file-format option is specified with CrunchIndexerTool, then its argument must be text, avro, or avroParquet, rather than a fully qualified class name.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-22190
The quickstart.sh file does not validate ZooKeeper and the NameNode on some operating systems
The quickstart.sh file uses the timeout function to determine if ZooKeeper and the NameNode are available. To ensure this check can be complete as intended, the quickstart.sh determines if the operating system on which the script is running supports timeout. If the script detects that the operating system does not support timeout, the script continues without checking if the NameNode and ZooKeeper are available. If your environment is configured properly or you are using an operating system that supports timeout, this issue does not apply.
Workaround: This issue only occurs in some operating systems. If timeout is not available, the quickstart continues and final validation is always done by the MapReduce jobs and Solr commands that are run by the quickstart.
Affected Versions: All
Cloudera Issue: CDH-19923
Field value class guessing and Automatic schema field addition are not supported with the MapReduceIndexerTool nor the HBaseMapReduceIndexerTool
The MapReduceIndexerTool and the HBaseMapReduceIndexerTool can be used with a Managed Schema created via NRT indexing of documents or via the Solr Schema API. However, neither tool supports adding fields automatically to the schema during ingest.
Workaround: Define the schema before running the MapReduceIndexerTool or HBaseMapReduceIndexerTool. In non-schemaless mode, define in the schema using the schema.xml file. In schemaless mode, either define the schema using the Solr Schema API or index sample documents using NRT indexing before invoking the tools. In either case, Cloudera recommends that you verify that the schema is what you expect using the List Fields API command.
Affected Versions: All
Cloudera Issue: CDH-26856
The Browse and Spell Request Handlers are not enabled in schemaless mode
The Browse and Spell Request Handlers require certain fields be present in the schema. Since those fields cannot be guaranteed to exist in a Schemaless setup, the Browse and Spell Request Handlers are not enabled by default.
Workaround: If you require the “Browse” and “Spell” Request Handlers, add them to the solrconfig.xml configuration file. Generate a non-schemaless configuration to see the usual settings and modify the required fields to fit your schema.
Affected Versions: All
Cloudera Issue: CDH-19407
Enabling blockcache writing may result in unusable indexes
It is possible to create indexes with solr.hdfs.blockcache.write.enabled set to true. Such indexes may appear corrupt to readers, and reading these indexes may irrecoverably corrupt indexes. Blockcache writing is disabled by default.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-17978
Users with insufficient Solr permissions may receive a "Page Loading" message from the Solr Web Admin UI
Users who are not authorized to use the Solr Admin UI are not given page explaining that access is denied, and instead receive a web page that never finishes loading.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-58276
Using MapReduceIndexerTool or HBaseMapReduceIndexerTool multiple times may produce duplicate entries in a collection.
Repeatedly running the MapReduceIndexerTool on the same set of input files can result in duplicate entries in the Solr collection. This occurs because the tool can only insert documents and cannot update or delete existing Solr documents. This issue does not apply to the HBaseMapReduceIndexerTool unless it is run with more than zero reducers.
Workaround: To avoid this issue, use HBaseMapReduceIndexerTool with zero reducers. This must be done without Kerberos.
Affected Versions: All
Cloudera Issue: CDH-15441
Deleting collections might fail if hosts are unavailable
It is possible to delete a collection when hosts that host some of the collection are unavailable. After such a deletion, if the previously unavailable hosts are brought back online, the deleted collection may be restored.
Workaround: Ensure all hosts are online before deleting collections.
Affected Versions: All
Cloudera Issue: CDH-58694
Saving search results is not supported
Cloudera Search does not support the ability to save search results.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-21162
HDFS Federation is not supported
Cloudera Search does not support HDFS Federation.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-11357
Solr contrib modules are not supported
Solr contrib modules are not supported (Morphlines, Spark Crunch indexer, MapReduce and Lily HBase indexers are part of the Cloudera Search product itself, therefore they are supported).
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-72658
Using the Sentry Service with Cloudera Search may introduce latency
Using the Sentry Service with Cloudera Search may introduce latency because authorization requests must be sent to the Sentry Service.
Workaround: You can alleviate this latency by enabling caching for the Sentry Service. For instructions, see: Enabling Caching for the Sentry Service.
Affected Versions: All
Cloudera Issue: CDH-73407
Solr Sentry integration limitation where two Solr deployments depend on the same Sentry service
If multiple Solr instances are configured to depend on the same Sentry service, it is not possible to create unique Solr Sentry privileges per Solr deployment. Since privileges are enforced in all Solr instances simultaneously, you cannot add distinct privileges that apply to one Solr cluster, but not to another.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-72676
Collection state goes down after Solr SSL
If you enable TLS/SSL on a Solr instance with existing collections, the collections will break and become unavailable. Collections created after enabling TLS/SSL are not affected by this issue.
Workaround: Recreate the collection after enabling TLS. For more information, see How to update existing collections in Non-SSL to SSL in Solr.
Affected Versions: All
Cloudera Issue: CDPD-4139
Apache Sentry Known Issues
The following sections describe known issues and workarounds in Sentry, as of the current production release.
Sentry does not support Kafka topic name with more than 64 characters
A Kafka topic name can have 249 characters, but Sentry only supports topic names up to 64 characters.
Workaround: Keep Kafka topic names to 64 charcters or less.
Affected Versions: All CDH 5.x and 6.x versions
Cloudera Issue: CDH-64317
SHOW ROLE GRANT GROUP raises exception for a group that was never granted a role
If you run the command SHOW ROLE GRANT GROUP for a group that has never been granted a role, beeline raises an exception. However, if you run the same command for a group that does not have any roles, but has at one time been granted a role, you do not get an exception, but instead get an empty list of roles granted to the group.
Workaround: Adding a role will prevent the exception.
Affected Versions:
- CDH 5.16.0
- CDH 6.0.0
Cloudera Issue: CDH-71694
GRANT/REVOKE operations could fail if there are too many concurrent requests
Under a significant workload, Grant/Revoke operations can have issues.
Workaround: If you need to make many privilege changes, plan them at a time when you do not need to do too many at once.
Affected Versions: CDH 5.13.0 and above
Apache Issue: SENTRY-1855
Cloudera Issue: CDH-56553
Creating large set of Sentry roles results in performance problems
Using more than a thousand roles/permissions might cause significant performance problems.
Workaround: Plan your roles so that groups have as few roles as possible and roles have as few permissions as possible.
Affected Versions: CDH 5.13.0 and above
Cloudera Issue: CDH-59010
Users can't track jobs with Hive and Sentry
As a prerequisite of enabling Sentry, Hive impersonation is turned off, which means all YARN jobs are submitted to the Hive job queue, and are run as the hive user. This is an issue because the YARN History Server now has to block users from accessing logs for their own jobs, since their own usernames are not associated with the jobs. As a result, end users cannot access any job logs unless they can get sudo access to the cluster as the hdfs, hive or other admin users.
In CDH 5.8 (and higher), Hive overrides the default configuration, mapred.job.queuename, and places incoming jobs into the connected user's job queue, even though the submitting user remains hive. Hive obtains the relevant queue/username information for each job by using YARN's fair-scheduler.xml file.
Affected Versions: CDH 5.2.0 and above
Cloudera Issue: CDH-22890
Column-level privileges are not supported on Hive Metastore views
GRANT and REVOKE for column level privileges is not supported on Hive Metastore views.
Affected Versions: All CDH versions
Apache Issue: SENTRY-754
SELECT privilege on all columns does not equate to SELECT privilege on table
Users who have been explicitly granted the SELECT privilege on all columns of a table, will not have the permission to perform table-level operations. For example, operations such as SELECT COUNT (1) or SELECT COUNT (*) will not work even if you have the SELECT privilege on all columns.
There is one exception to this. The SELECT * FROM TABLE command will work even if you do not have explicit table-level access.
Affected Versions: All CDH versions
Apache Issue: SENTRY-838
The EXPLAIN SELECT operation works without table or column-level privileges
Users are able to run the EXPLAIN SELECT operation, exposing metadata for all columns, even for tables/columns to which they weren't explicitly granted access.
Affected Versions: All CDH versions
Apache Issue: SENTRY-849
Object types Server and URI are not supported in SHOW GRANT ROLE roleName on OBJECT objectName
Workaround:Use SHOW GRANT ROLE roleNameto list all privileges granted to the role.
Affected Versions: All CDH versions
Apache Issue: N/A
Cloudera Issue: CDH-19430
Relative URI paths not supported by Sentry
Sentry supports only absolute (not relative) URI paths in permission grants. Although some early releases (for example, CDH 5.7.0) might not have raised explicit errors when relative paths were set, upgrading a system that uses relative paths causes the system to lose Sentry permissions.
Resolution: Revoke privileges that have been set using relative paths, and grant permissions using absolute paths before upgrading.
Affected Versions: All versions. Relative paths are not supported in Sentry for permission grants.
| Absolute (Use this form) | Relative (Do not use this form) |
|---|---|
| hdfs://absolute/path/ | hdfs://relative/path |
| s3a://bucketname/ | s3a://bucketname |
Apache Spark Known Issues
The following sections describe the current known issues and limitations in Apache Spark 2.x as distributed with CDH 6.3.x. In some cases, a feature from the upstream Apache Spark project is currently not considered reliable enough to be supported by Cloudera.
Continue reading:
- RDD.repartition() has different failure handling in Spark 2.4 and may cause job failures
- Structured Streaming exactly-once fault tolerance constraints
- Spark SQL does not respect size limit for the varchar type
- Spark SQL does not prevent you from writing key types not supported by Avro tables
- Spark SQL does not support timestamp in Avro tables
- Dynamic allocation and Spark Streaming
- Limitation with Region Pruning for HBase Tables
- Running spark-submit with --principal and --keytab arguments does not work in client mode
- The --proxy-user argument does not work in client mode
- History link in ResourceManager web UI broken for killed Spark applications
RDD.repartition() has different failure handling in Spark 2.4 and may cause job failures
The RDD.repartition() transformation, which reshuffles data in the RDD randomly to create either more or fewer partitions and then balances it across the partitions, was using a round-robin method to distribute data that caused incorrect answers to be returned for RDD jobs. This issue has been corrected, but it introduced a behavior change in RDD job failure handling. Now, Spark actively fails a job if there is a fetch failure that was caused by a node failure after repartitioning.
Workaround: Use the RDD.checkpoint() method to save the intermediate RDD data to HDFS. First, call SparkContext.setCheckpointDir(directory: String) to set the checkpoint directory where the intermediate data will be saved. Note that the directory must be an HDFS path. Then mark the RDD for checkpointing by calling RDD.checkpoint() when you use the RDD.repartition() transformation.
Apache Issue: SPARK-23243
Cloudera Issue: CDH-76413
Structured Streaming exactly-once fault tolerance constraints
In Spark Structured Streaming, the exactly-once fault tolerance for file sink is valid only for files that are in the manifest. These files are located in the _spark_metadata subdirectory of the file sink output directory. Only process files that have file names starting with digits. Other temporary files can also appear in this directory, but they should not be processed. Typically, these temporary file file names start with a period (".").
You can list the valid manifest files, excluding the temporary files, by using a command like the following, which assumes your output directory is located at /tmp/output. As the appropriate user, run the following command to list the valid manifest files:
hadoop fs -ls /tmp/output/_spark_metadata/[0-9]*
Workaround: None
Affected Versions: CDH 6.1.0 and higher
Cloudera Issue: CDH-75191
Spark SQL does not respect size limit for the varchar type
Spark SQL treats varchar as a string (that is, there no size limit). The observed behavior is that Spark reads and writes these columns as regular strings; if inserted values exceed the size limit, no error will occur. The data will be truncated when read from Hive, but not when read from Spark.
Workaround: None
Affected Versions: CDH 5.5.0 and higher
Apache Issue: SPARK-5918
Cloudera Issue: CDH-33642
Spark SQL does not prevent you from writing key types not supported by Avro tables
Spark allows you to declare DataFrames with any key type. Avro supports only string keys and trying to write any other key type to an Avro table will fail.
Workaround: None
Affected Versions: CDH 5.5.0 and higher
Cloudera Issue: CDH-33648
Spark SQL does not support timestamp in Avro tables
Workaround: None
Affected Versions: CDH 5.5.0 and higher
Cloudera Issue: CDH-33649
Dynamic allocation and Spark Streaming
If you are using Spark Streaming, Cloudera recommends that you disable dynamic allocation by setting spark.dynamicAllocation.enabled to false when running streaming applications.
Limitation with Region Pruning for HBase Tables
When SparkSQL accesses an HBase table through the HiveContext, region pruning is not performed. This limitation can result in slower performance for some SparkSQL queries against tables that use the HBase SerDes than when the same table is accessed through Impala or Hive.
Workaround: None
Affected Versions: All
Cloudera Issue: CDH-56330
Running spark-submit with --principal and --keytab arguments does not work in client mode
The spark-submit script's --principal and --keytab arguments do not work with Spark-on-YARN's client mode.
Workaround: Use cluster mode instead.
Affected Versions: All
The --proxy-user argument does not work in client mode
Using the --proxy-user argument in client mode does not work and is not supported.
Workaround: Use cluster mode instead.
Affected Versions: All
History link in ResourceManager web UI broken for killed Spark applications
When a Spark application is killed, the history link in the ResourceManager web UI does not work.
Workaround: To view the history for a killed Spark application, see the Spark HistoryServer web UI instead.
Affected Versions: All CDH versions
Apache Issue: None
Cloudera Issue: CDH-49165
ORC file format is not supported
Currently, Cloudera does not support reading and writing Hive tables containing data files in the Apache ORC (Optimized Row Columnar) format from Spark applications. Cloudera recommends using Apache Parquet format for columnar data. That file format can be used with Spark, Hive, and Impala.
Apache Sqoop Known Issues
Column names cannot start with a number when importing data with the --as-parquetfile option.
Currently, Sqoop is using an Avro schema when writing data as a parquet file. The Avro schema requires that column names do not start with numbers, therefore Sqoop is renaming the columns in this case, prepending them with an underscore character. This can lead to issues when one wants to reuse the data in other tools, such as Impala.
Workaround: Rename the columns to comply with Avro limitations (start with letters or underscore, as specified in the Avro documentation).
Cloudera Issue: None
MySQL JDBC driver shipped with CentOS 6 systems does not work with Sqoop
CentOS 6 systems currently ship with version 5.1.17 of the MySQL JDBC driver. This version does not work correctly with Sqoop.
Workaround: Install version 5.1.31 of the JDBC driver as detailed in Installing the JDBC Drivers for Sqoop 1.
Affected Versions: MySQL JDBC 5.1.17, 5.1.4, 5.3.0
Cloudera Issue: CDH-23180
MS SQL Server "integratedSecurity" option unavailable in Sqoop
The integratedSecurity option is not available in the Sqoop CLI.
Workaround: None
Cloudera Issue: None
Sqoop1 (doc import + --as-parquetfile) limitation with KMS/KTS Encryption at Rest
sqoop import --connect jdbc:db2://djaxludb1001:61035/DDBAT003 --username=dh810202 --P --target-dir /data/hive_scratch/ASDISBURSEMENT --delete-target-dir -m1 --query "select disbursementnumber,disbursementdate,xmldata FROM DB2dba.ASDISBURSEMENT where DISBURSEMENTNUMBER = 2011113210000115311 AND \$CONDITIONS" -hive-import --hive-database adminserver -hive-table asdisbursement_dave --map-column-java XMLDATA=String --as-parquetfile 16/12/05 12:23:46 INFO mapreduce.Job: map 100% reduce 0% 16/12/05 12:23:46 INFO mapreduce.Job: Job job_1480530522947_0096 failed with state FAILED due to: Job commit failed: org.kitesdk.data.DatasetIOException: Could not move contents of hdfs://AJAX01-ns/tmp/adminserver/.temp/job_1480530522947_0096/mr/job_1480530522947_0096 to hdfs://AJAX01-ns/data/RetiredApps/INS/AdminServer/asdisbursement_dave <SNIP> Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException): /tmp/adminserver/.temp/job_1480530522947_0096/mr/job_1480530522947_0096/5ddcac42-5d69-4e46-88c2-17bbedac4858.parquet can't be moved into an encryption zone.
Workaround: If you use the Parquet Hadoop API based implementation for importing into Parquet, specify a --target-dir which is the same encryption zone as the Hive warehouse directory.
If you use the Kite Dataset API based implementation, use an alternate data file type, for example text or avro.
Apache Issue: SQOOP-2943
Cloudera Issue: CDH-40826
Doc import as Parquet files may result in out-of-memory errors
- With many very large rows (multiple megabytes per row) before initial-page-run check (ColumnWriter)
- When rows vary significantly by size so that the next-page-size check is based on small rows and is set very high followed by many large rows
Workaround: None, other than restructuring the data.
Apache Issue: PARQUET-99
Apache ZooKeeper Known Issues
There are no known issues in this release.
