New Features in Cloudera Navigator 6.2.0
The following sections describe what's new and what has changed in the data management components of Cloudera Navigator 6.2.0:
Virtual Private Cluster Support
Navigator continues to support audit and metadata extraction from services on the base cluster in an environment running both base and compute clusters. However, no audit events or metadata are extracted from services running on compute clusters. You can expect the following behavior for services included in a data context:
- HDFS, S3, ADLS. HDFS audits and metadata changes that affect file system directories and files are collected in Navigator. Operations and operation executions that are performed on the compute cluster against HDFS entities are not collected. This means Navigator will show the HDFS entities, but if operations are performed against them from the compute cluster, Navigator will not include metadata for the operation execution or lineage from the HDFS entity to any input or output.
- Hive. HMS audits and metadata changes that describe Hive databases, tables, views, partitions, and columns are collected in Navigator. Operations and operation executions performed by HiveServer2, Impala, and SparkSQL on the compute cluster against Hive entities are not collected. For example, if a user runs a SELECT against a table from the compute cluster, a SELECT event is not collected; if a user creates a table and loads data into it on the compute cluster, Navigator will create an entity for the table when extracting metadata from HMS on the base cluster. It will not include metadata for the create operation or create lineage to indicate the source of data for the table.
- Sentry. Services that check user access against Sentry policies have the same behavior on the compute cluster as on the base cluster. However, Navigator will not collect audits for when services on the compute cluster check Sentry policies for data access. For example, when a user performs a SELECT against a table from the compute cluster and the user does not have access to the table or one or more columns, the denied access event would be created by the service on the compute cluster and is therefore not collected. If the same actions occur on the base cluster, the Navigator audits will include the events.
To summarize, Navigator does collect audit events and extract metadata from shared services in the data context. Navigator does not collect audits from services running on compute clusters. Navigator does not extract metadata for services running on compute clusters. For more information, see Virtual Private Clusters and Cloudera SDX.
Deterministic Metadata Purge Operation
In this release, the metadata purge operation has a high priority relative to other Navigator Metadata Server tasks. When a purge operation runs, it first stops any other Navigator Metadata Server tasks. After the purge completes (or reaches the time limit for when it can run), it reschedules the extraction tasks that were stopped. This behavior applies to metadata clean up jobs scheduled in the Navigator console () or through the Navigator API and to jobs to clear deleted managed metadata properties (). Note that policy tasks interrupted by a purge operation are not restarted.
For more information, see Best Practices for Clearing Metadata using Purge.
Bulk Metadata Update API
This release provides a bulk interface for updating Navigator entity metadata. Use the PUT /entities/bulk/ API to update metadata for many entities in the same call. This API is faster than the single PUT API because it uses a single HTTP request to apply the metadata rather than an HTTP request for each entity.
For more information see the interactive API documentation available from the Help menu in the Navigator console or Updating Metadata for Entities in Bulk: PUT /entities/bulk.
File size reporting support
This release includes Navigator support for file size reporting with the goal of identifying potential performance problems stemming from data stored inefficiently. Navigator collects file size metadata and saves it in HDFS. Telemetry Publisher gets the metadata from HDFS and sends it to Cloudera Workload Experience Manager (WXM).
Not supported for secure clusters.
Enable this feature in Cloudera Manager with Cloudera Management Service properties for "Small Files Reporting:"
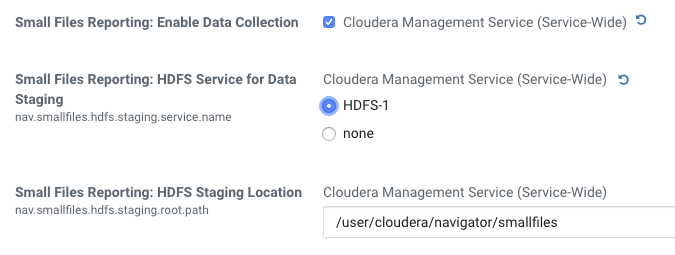
Restart Navigator Metadata Server after enabling data collection for small files reporting.
For more information, see File Size Reporting in the Workload Experience Manager documentation.
Metadata for Hive columns now includes the column number
The technical metadata for Hive table columns now includes the ordinal position for the columns as "Field Index", the index starting at zero. You can include "Field Index" as a search facet for Hive columns or specify "fieldIndex" in a metadata search query. In addition, columns are ordered by their field index when listed in the table metadata.
For new installations, this additional metadata appears as metadata for Hive assets are extracted. For upgraded installations, the additional metadata must be re-extracted from Hive assets that are already in Navigator; you may not see the field index values immediately after the upgrade.
