
Direct Reader mode introduction
Direct Reader mode is a transparent connection that Hive Warehouse Connector (HWC) makes to Apache Hive metastore (HMS) to get transaction information. You use this mode if you do not need production-level Ranger authorization. Direct Reader mode does not support Ranger authorization. Direct Reader does support Spark-consistent timestamps in this release and later.
In Direct Reader mode, Spark reads the data directly from the managed table location using the transaction snapshot.
Requirements and recommendations
Spark Direct Reader mode requires a connection to Hive metastore. A HiveServer (HS2) connection is not needed.
Spark Direct Reader for reading Hive ACID, transactional tables from Spark is supported for production use. Use Spark Direct Reader mode if your ETL jobs do not require authorization and run as super user.
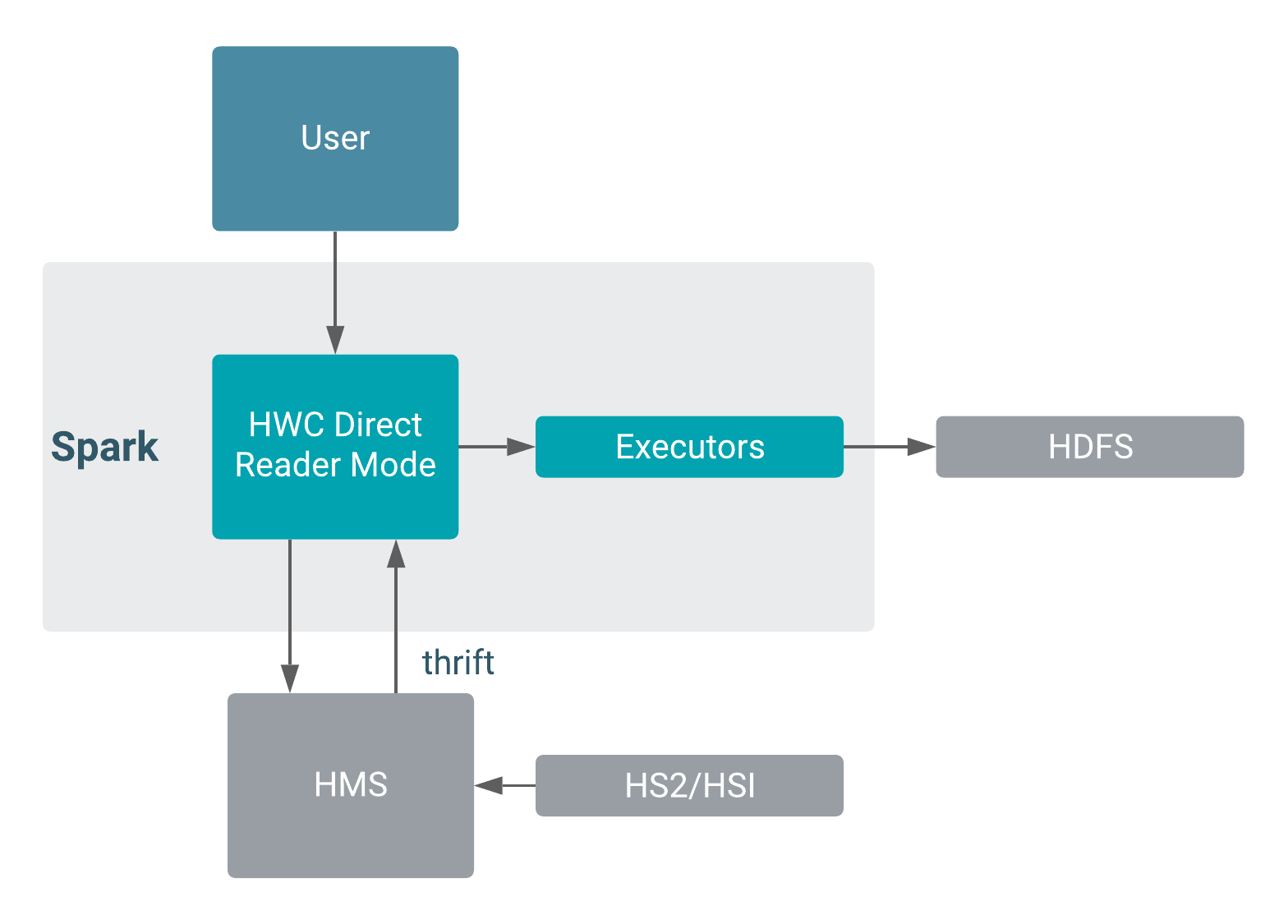
Component interaction
The following diagram shows component interaction ifor Direct Reader reads.
Using the timestamp type
When reading tables with Direct Reader, the behavior of the timestamp type is consistent with Spark. If you use the same storage format to store a timestamp value in an external table and a managed, transactional table, you see exactly the same value using the native Spark reader as you see using Direct Reader.
When querying a Hive table using Beeline, the behavior of the timestamp type is also
consistent with Spark, assuming the Spark JVA and session time zones are consistent with the
following exception: tables stored in Parquet format. Spark timestamp values differ depending on
the value of spark.sql.hive.convertMetastoreParquet even for the external
tables. Direct Reader reads of tables stored in Parquet format yields results as if
spark.sql.hive.convertMetastoreParquet is false.
This design ensures that the timestamp values remain consistent across all the formats when read by Direct Reader. In the following section, examples show how Spark and Direct Reader behave with timestamps. The examples query external and transactional tables in different formats. All the tables were created using Hive beeline. A timestamp value “1989-01-05 00:00:00” was inserted. The Spark native reader reads external tables. Direct Reader reads transactional tables. A union of all the dataframes make the result more presentable and comparable.
With spark.sql.hive.convertMetastoreParquet = true (default in spark)
+-------------------------+-------------------+ |type |timestamp | +-------------------------+-------------------+ |External parquet |1989-01-04 16:00:00| |Transactional parquet |1989-01-05 00:00:00| |External orc |1989-01-05 00:00:00| |Transactional orc |1989-01-05 00:00:00| |External avro |1989-01-05 00:00:00| |Transactional avro |1989-01-05 00:00:00| |External text |1989-01-05 00:00:00| |Transactional text |1989-01-05 00:00:00| +-------------------------+-------------------+
With spark.sql.hive.convertMetastoreParquet = false
+-------------------------+-------------------+ |type |timestamp | +-------------------------+-------------------+ |External parquet |1989-01-05 00:00:00| |Transactional parquet |1989-01-05 00:00:00| |External orc |1989-01-05 00:00:00| |Transactional orc |1989-01-05 00:00:00| |External avro |1989-01-05 00:00:00| |Transactional avro |1989-01-05 00:00:00| |External text |1989-01-05 00:00:00| |Transactional text |1989-01-05 00:00:00| +-------------------------+-------------------+
Direct Reader is aligned to Spark for all the storage formats, including convertMetastoreParquet.
