Installing NVIDIA GPU software in ECS
After you add a host containing a NVIDIA GPU card in an Embedded Container Service (ECS) cluster, you must install the NVIDIA GPU software driver and its associated software. You can then test the GPU card in the Cloudera Machine Learning (CML) workspace.
Installing the NVIDIA driver and container runtime
-
Use the NVIDIA Driver Downloads page to determine the software driver version required for your NVIDIA GPU card. This example uses a NVIDIA A100 GPU card, which requires driver version
515.65.01.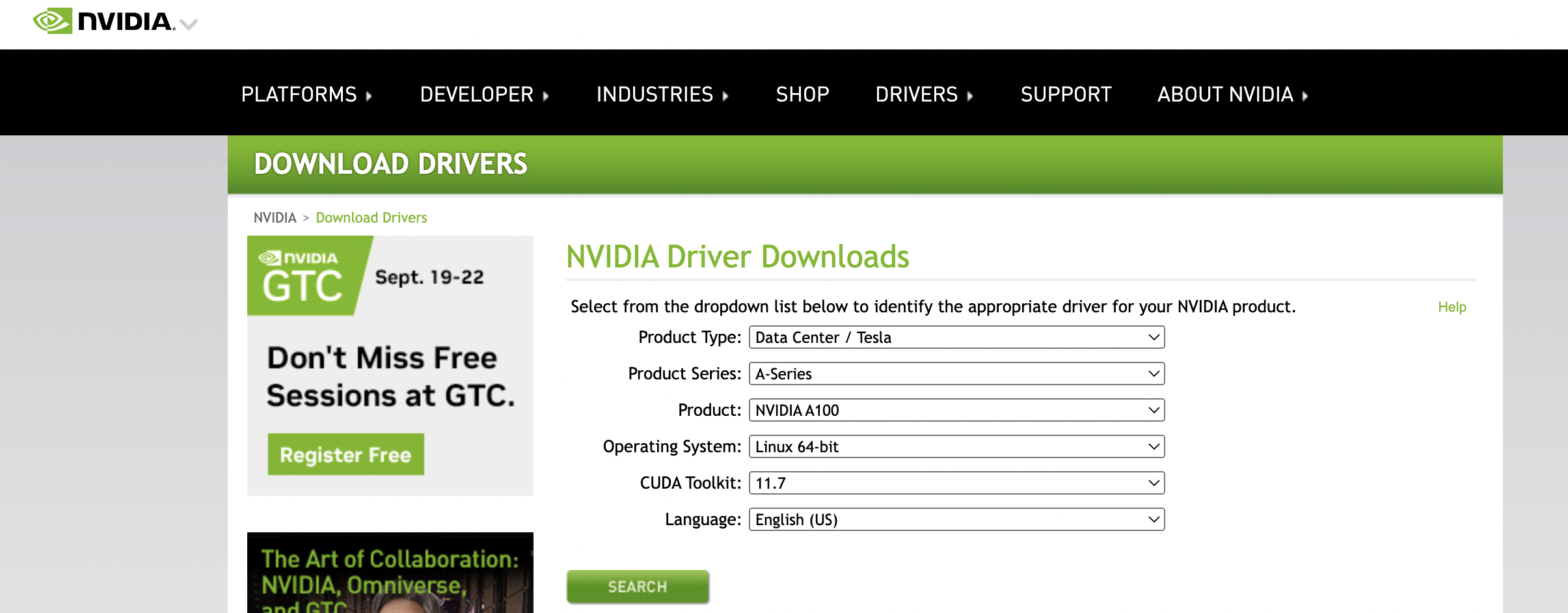
-
Run the following command to cordon the GPU worker node:
# kubectl cordon ecsgpu.cdpkvm.cldr node/ecsgpu.cdpkvm.cldr cordoned
- On the ECS host with the NVIDIA GPU card, install the required Operating System (OS)
software packages as shown below, and then reboot the node. In this example, the host OS
is Centos 7.9, and the host name of the node with the GPU card is
ecsgpu.cdpkvm.cldr.# yum update -y# yum install -y tar bzip2 make automake gcc gcc-c++ pciutils elfutils-libelf-devel libglvnd-devel vim bind-utils wget # yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # yum -y group install "Development Tools"# yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r) # reboot
-
Next, run the following commands to install the NVIDIA driver and
nvidia-container-runtimesoftware:# BASE_URL=https://us.download.nvidia.com/tesla# DRIVER_VERSION=515.65.01 # curl -fSsl -O $BASE_URL/$DRIVER_VERSION/NVIDIA-Linux-x86_64-$DRIVER_VERSION.run # sh NVIDIA-Linux-x86_64-$DRIVER_VERSION.run

-
After the installation is complete, run the
nvidia-smitool and ensure that the driver was successfully deployed. The output should look similar to the following example:[root@ecsgpu ~]# nvidia-smi Wed Aug 24 13:03:46 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA A100-PCI... Off | 00000000:08:00.0 Off | 0 | | N/A 32C P0 37W / 250W | 0MiB / 40960MiB | 3% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [root@ecsgpu ~]# lsmod | grep nvidia nvidia_drm 53212 0 nvidia_modeset 1142094 1 nvidia_drm nvidia 40761292 1 nvidia_modeset drm_kms_helper 186531 3 qxl,nouveau,nvidia_drm drm 468454 7 qxl,ttm,drm_kms_helper,nvidia,nouveau,nvidia_drm [root@ecsgpu ~]# dmesg | grep nvidia [ 123.588172] nvidia: loading out-of-tree module taints kernel. [ 123.588182] nvidia: module license 'NVIDIA' taints kernel. [ 123.704411] nvidia: module verification failed: signature and/or required key missing - tainting kernel [ 123.802826] nvidia-nvlink: Nvlink Core is being initialized, major device number 239 [ 123.925577] nvidia-uvm: Loaded the UVM driver, major device number 237. [ 123.934813] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 515.65.01 Wed Jul 20 13:43:59 UTC 2022 [ 123.940999] [drm] [nvidia-drm] [GPU ID 0x00000800] Loading driver [ 123.941018] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:08:00.0 on minor 1 [ 123.958317] [drm] [nvidia-drm] [GPU ID 0x00000800] Unloading driver [ 123.968642] nvidia-modeset: Unloading [ 123.978362] nvidia-uvm: Unloaded the UVM driver. [ 123.993831] nvidia-nvlink: Unregistered Nvlink Core, major device number 239 [ 137.450679] nvidia-nvlink: Nvlink Core is being initialized, major device number 240 [ 137.503657] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 515.65.01 Wed Jul 20 13:43:59 UTC 2022 [ 137.508187] [drm] [nvidia-drm] [GPU ID 0x00000800] Loading driver [ 137.508190] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:08:00.0 on minor 1 [ 149.717193] nvidia 0000:08:00.0: irq 48 for MSI/MSI-X [ 149.717222] nvidia 0000:08:00.0: irq 49 for MSI/MSI-X [ 149.717248] nvidia 0000:08:00.0: irq 50 for MSI/MSI-X [ 149.717275] nvidia 0000:08:00.0: irq 51 for MSI/MSI-X [ 149.717301] nvidia 0000:08:00.0: irq 52 for MSI/MSI-X [ 149.717330] nvidia 0000:08:00.0: irq 53 for MSI/MSI-X -
Install the
nvidia-container-runtimesoftware package, and then reboot the server:# curl -s -L https://nvidia.github.io/nvidia-container-runtime/$(. /etc/os-release;echo $ID$VERSION_ID)/nvidia-container-runtime.repo | sudo tee /etc/yum.repos.d/nvidia-container-runtime.repo# yum -y install nvidia-container-runtime# rpm -qa | grep nvidia libnvidia-container-tools-1.11.0-1.x86_64 libnvidia-container1-1.11.0-1.x86_64 nvidia-container-toolkit-base-1.11.0-1.x86_64 nvidia-container-runtime-3.11.0-1.noarch nvidia-container-toolkit-1.11.0-1.x86_64 # nvidia-container-toolkit -version NVIDIA Container Runtime Hook version 1.11.0 commit: d9de4a0 # reboot -
Uncordon the GPU worker node:
# kubectl uncordon ecsgpu.cdpkvm.cldr node/ecsgpu.cdpkvm.cldr cordoned
Testing the NVIDIA GPU card in CML
-
SSH into the ECS master node in the CDP Private Cloud Data Services cluster and run the following command to ensure that the
ecsgpu.cdpkvm.cldrhost has thenvidia.com/gpu:field in the node specification. Hostecsgpu.cdpkvm.cldris a typical ECS worker node with the NVIDIA GPU card installed.[root@ecsmaster1 ~]# kubectl describe node ecsgpu.cdpkvm.cldr | grep-A15 Capacity: Capacity: cpu: 16 ephemeral-storage: 209703916Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263975200Ki nvidia.com/gpu: 1 pods: 110 Allocatable: cpu: 16 ephemeral-storage: 203999969325 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263975200Ki nvidia.com/gpu: 1 pods: 110 [root@ecsmaster1 ~]# kubectl describe node ecsworker1.cdpkvm.cldr | grep-A13 Capacity: Capacity: cpu: 16 ephemeral-storage: 103797740Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263974872Ki pods: 110 Allocatable: cpu: 16 ephemeral-storage: 100974441393 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263974872Ki pods: 110 -
In the CDP Private Cloud Data Services CML workspace, select Site Administration > Runtime/Engine. Specify a number for Maximum GPUs per Session/Job. This procedure effectively allows the CML session to consume the GPU card.
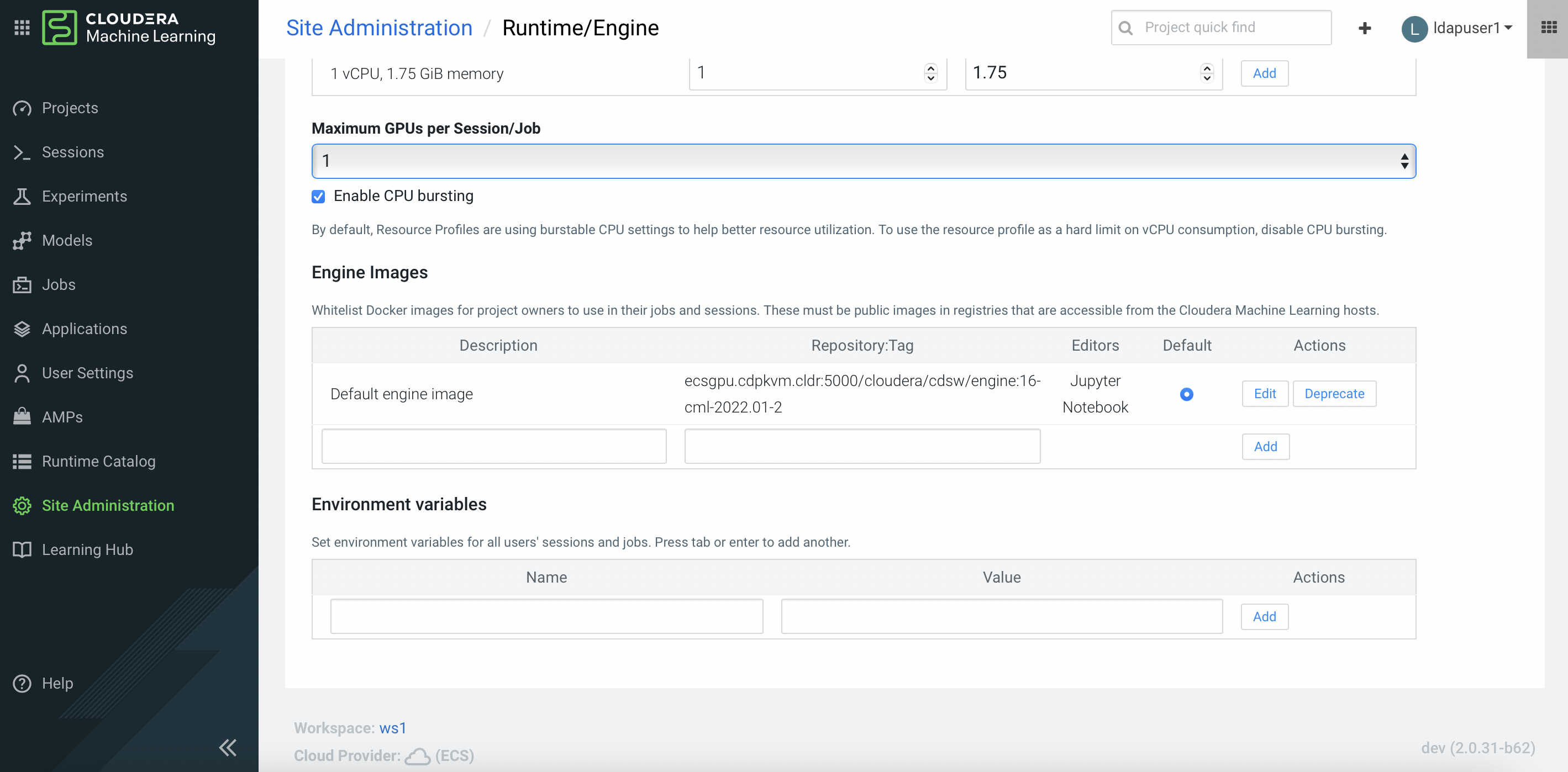
-
Create a CML project and start a new session by selecting the Workbench editor with a Python kernel and a NVIDIA GPU edition. Specify the number of GPUs to use – in this example, 1 GPU is specified.
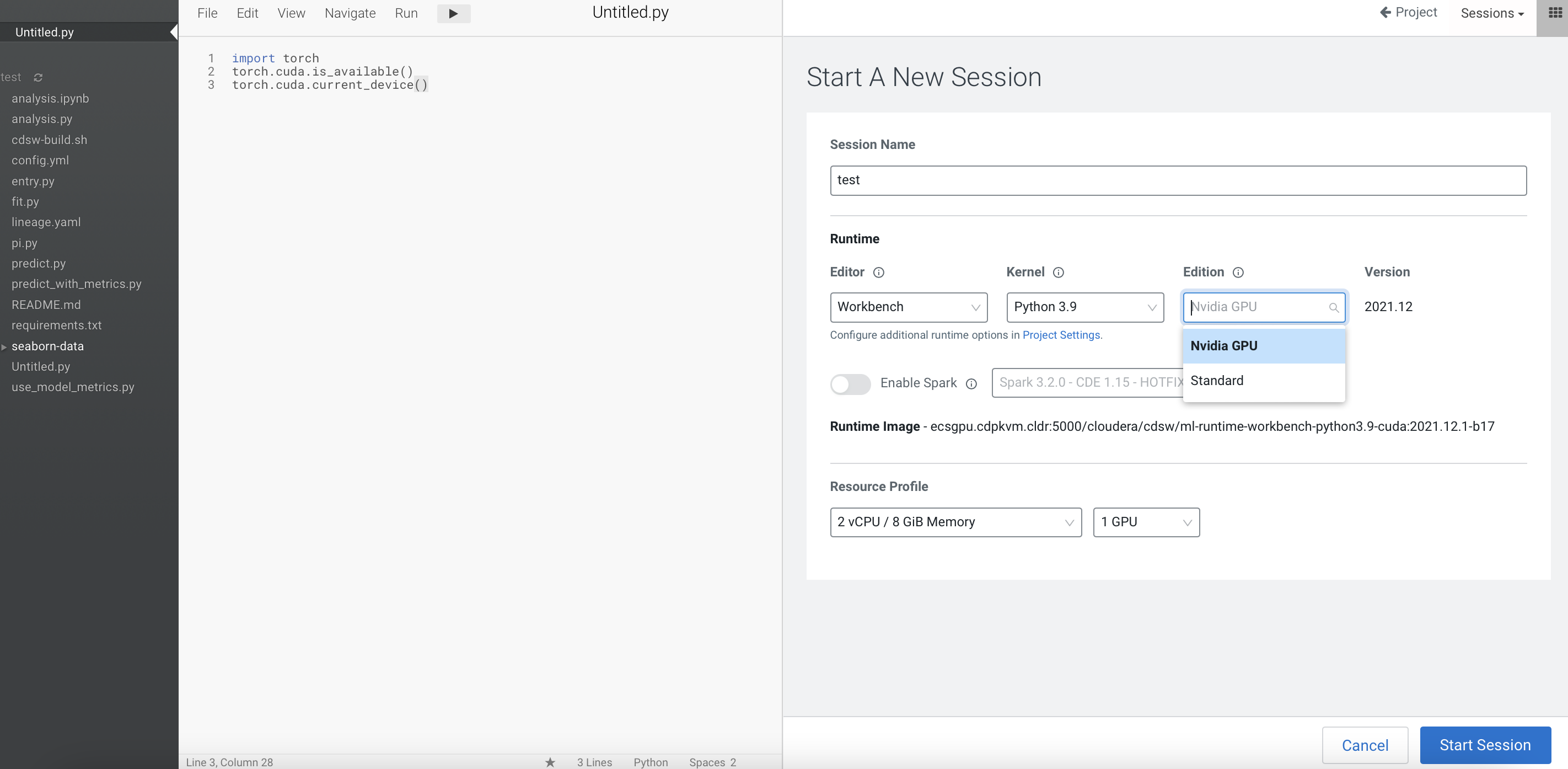
-
Create a new Python file and run the following script. Also, open the terminal session and run the
nvidia-smitool. Note that the output shows the NVIDIA GPU card details.!pip3install torchimport torchtorch.cuda.is_available()torch.cuda.device_count()torch.cuda.get_device_name(0)
-
Navigate to the CML Projects page and confirm that the User Resources dashboard displays the GPU card availability.
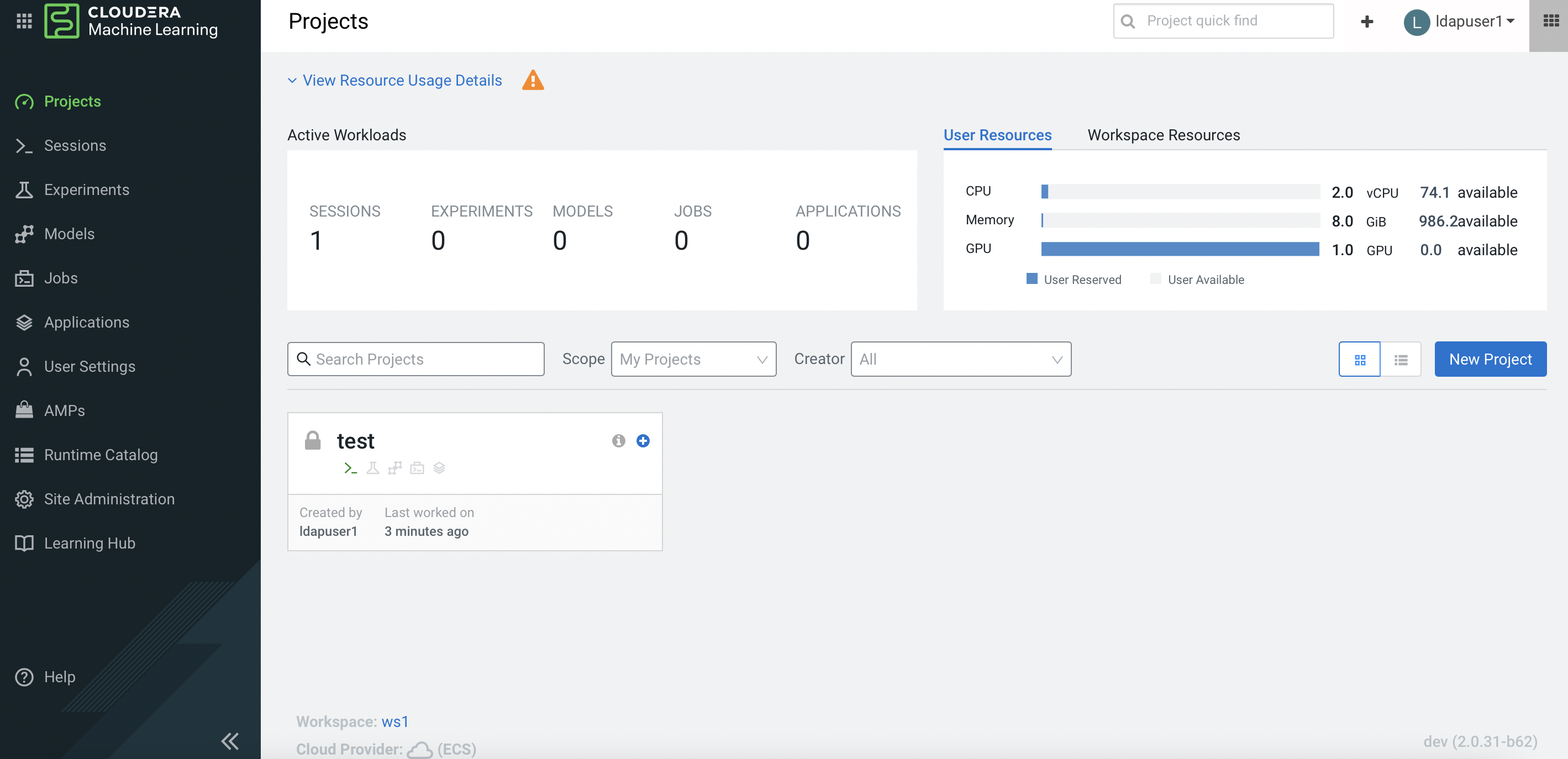

-
SSH into the ECS master node and run the following command to verify that the node that hosting the above CML project session pod is
ecsgpu.cdpkvm.cldr.[root@ecsmaster1 ~]# oc -n workspace1-user-1 describe pod wifz6t8mvxv5ghwy | grep Node: Node: ecsgpu.cdpkvm.cldr/10.15.4.185 [root@ecsmaster1 ~]# oc -n workspace1-user-1 describe pod wifz6t8mvxv5ghwy | grep-B2-i nvidia Limits: memory: 7714196Ki nvidia.com/gpu: 1 -- cpu: 1960m memory: 7714196Ki nvidia.com/gpu: 1 -- -
When a process is consuming the NVIDIA GPU, the output of the
nvidia-smitool shows the PID of that process (in this case, the CML session pod).[root@ecsgpu ~]# nvidia-smi Thu Aug 25 13:58:40 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA A100-PCI... Off | 00000000:08:00.0 Off | 0 | | N/A 29C P0 35W / 250W | 39185MiB / 40960MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 29990 C /usr/local/bin/python3.9 39183MiB | +-----------------------------------------------------------------------------+ -
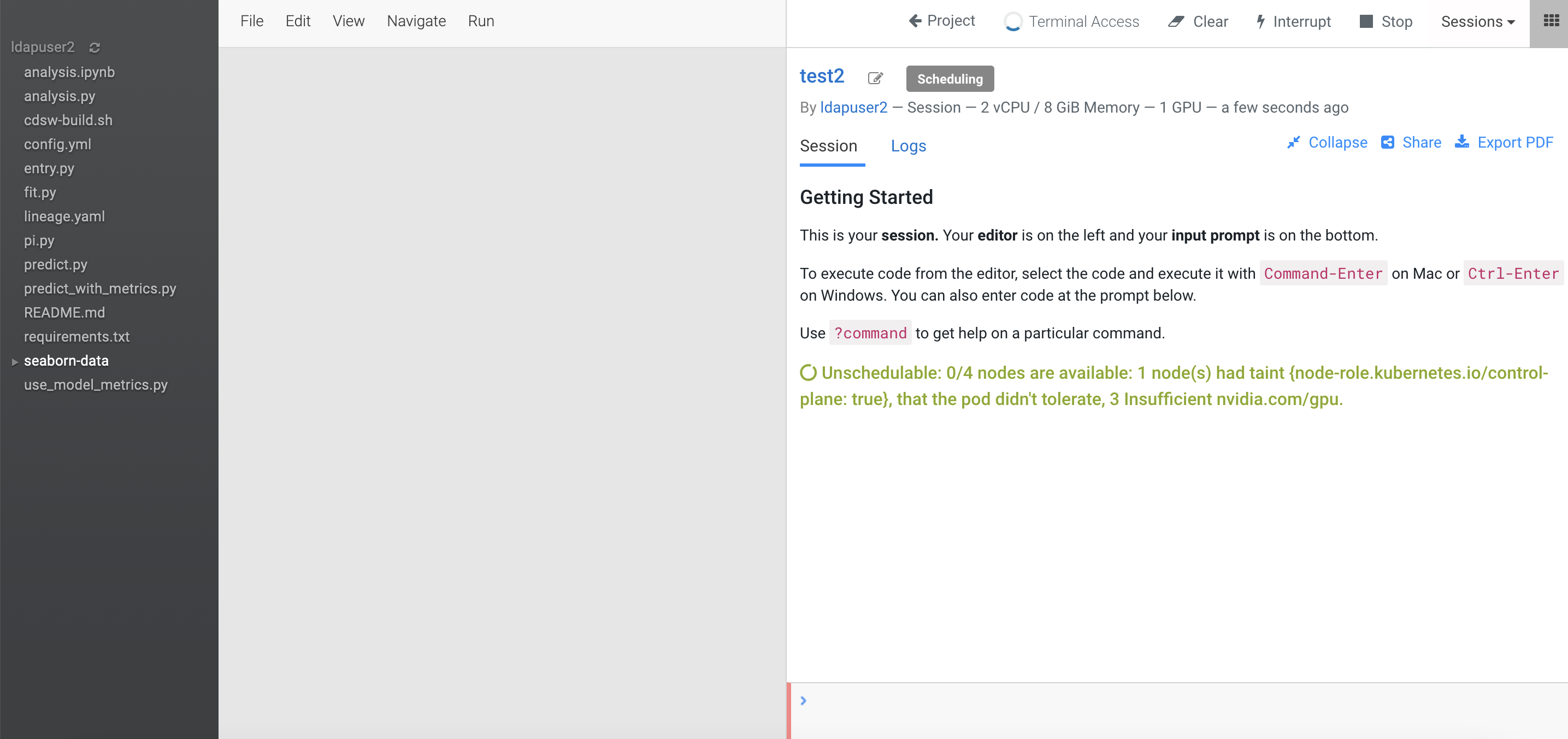
In the event that the ECS platform has no available worker node with a GPU card, provisioning a session with GPU will result in a
Pendingstate as the system is looking for a worker node installed with at least one NVIDIA GPU card.