
Learn about NiFi processors
Reviewing the list of available NiFi processors can help you better understand the capabilities of the out-of-the-box processors.
See what processors are available
To create an effective data flow, you must understand what types of processors are available and what they are suited for. NiFi contains many processors that are available out of the box. These provide capabilities to ingest data from different systems, route, transform, process, split, and aggregate data and also distribute data to many systems. The number of processors increases in almost every Apache NiFi release.
For the complete list of NiFi processors available in this release, see the list of Supported NiFi Processors.
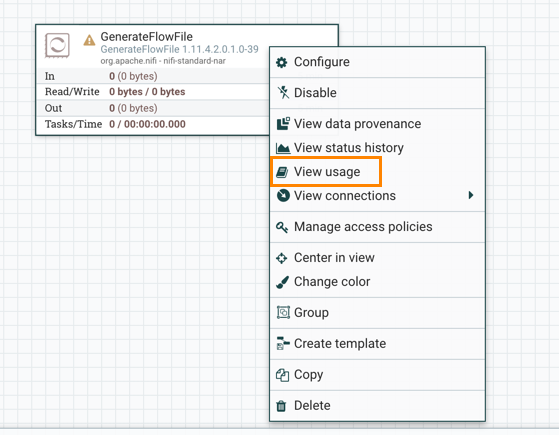
Get more information for a processor
Each processor has multiple properties and relationships, and it can be challenging to remember how all of the different pieces work for the processor. You can review a processor’s usage information by right-clicking the processor and choosing the View usage menu item.
Work with attributes
Each FlowFile is created with several attributes, and these attributes change over the life of the FlowFile. The concept of a FlowFile provides three primary benefits:
-
It enables you to make routing decisions in the flow so that FlowFiles that meet certain criteria can be handled differently than other FlowFiles. This is done using the RouteOnAttribute and similar processors.
-
Attributes are used to configure processors in such a way that the configuration of the processor is dependent on the data itself. For instance, the PutFile processor uses the attributes to know where to store each FlowFile, while the directory and filename attributes may be different for each FlowFile.
-
Attributes provide valuable context about the data. This is useful when reviewing the provenance data for a FlowFile. You can search for provenance data that match specific criteria, and it also enables you to view this context when inspecting the details of a Provenance Event. By doing this, you gain valuable insight as to why the data was processed one way or another, by glancing at this context that is carried along with the content.
Each FlowFile has a minimum set of attributes called Common Attributes:
filename- A filename that can be used to store the data to a local or remote file system.
path- The name of a directory that can be used to store the data to a local or remote file system.
uuid- A Universally Unique Identifier that distinguishes the FlowFile from other FlowFiles in the system.
entryDate- The date and time at which the FlowFile entered the system (that is, was created). The value of this attribute is a number that represents the number of milliseconds since midnight, Jan. 1, 1970 (UTC).
lineageStartDate- Any time that a FlowFile is cloned, merged, or split, this results in a 'child' FlowFile being created. As those children are then cloned, merged, or split, a chain of ancestors is built. This value represents the date and time at which the oldest ancestor entered the system. Another way to think about this is that this attribute represents the latency of the FlowFile through the system. The value is a number that represents the number of milliseconds since midnight, Jan. 1, 1970 (UTC).
fileSize- This attribute represents the number of bytes taken up by the FlowFile’s content.
To extract attributes, add user-defined attributes, route FlowFiles based on their attributes, or perform other complex tasks with the help of attributes, see Working With Attributes in the Apache NiFi Getting Started Guide for details.
