How To Back Up and Restore HDFS Data Using Cloudera Enterprise BDR
Cloudera Enterprise Backup and Disaster Recovery (BDR) uses replication schedules to copy data from one cluster to another, enabling the second cluster to provide a backup for the first. In case of any data loss, the second cluster—the backup—can be used to restore data to production.
This tutorial shows you how to create a replication schedule to copy HDFS data from one cluster to another for a backup, and how to create and test a replication schedule that you can use to restore data when needed in the future.
- A license for Cloudera Enterprise. Cloudera Enterprise BDR is available from the Backup menu of Cloudera Manager Admin Console when licensed for Enterprise.
- The BDR Administrator or Full Administrator role on the clusters involved (typically, a production cluster and a backup cluster).
This tutorial includes the following information:
Best Practices for Back Up and Restore
When configuring replication schedules for HDFS back up and restore, follow these guidelines:
- Make sure that the time-frames configured for replication schedules allow for the replication process to complete.
- Create a restore replication schedule in advance but leave it disabled, as shown in this tutorial.
- Test your replication schedules for both back up and restore before relying on them in a production environment.
- Enable only one replication schedule for the same dataset at the same time. That means you must first disable the backup replication schedule before enabling or creating a restore replication schedule for the same dataset, and vice versa.
- Enable snapshots on the HDFS file system. Snapshots ensure consistency if changes are still being made to data during the replication process. See Using Snapshots with Replication for details.
About the Example Clusters
This tutorial uses the two example clusters listed in the table. The nodes shown are the master nodes for the clusters.
| Production cluster | Backup cluster |
|---|---|
| cloudera-bdr-src-{1..4}.cloud.computers.com | cloudera-bdr-tgt-{1..4}.cloud.computers.com |
| http://cloudera-bdr-src-1.cloud.computers.com | http://cloudera-bdr-tgt-1.cloud.conputers.com |
| Source cluster for a backup replication schedule. | Destination cluster for a backup replication schedule. |
| Destination for a restore replication schedule. | Source for a restore replication schedule. |
| For restore, set peer relationship from this cluster. | For backup, set peer relationship from this cluster. To create an initial backup, set Schedule to Immediate. |
The example clusters are not configured to use Kerberos, nor do they use external accounts for cloud storage on Amazon Web Services (AWS).
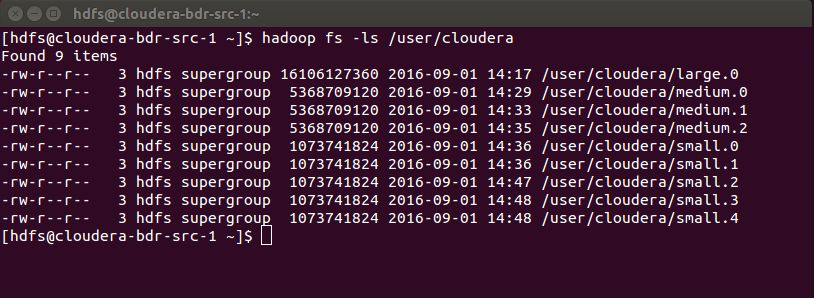
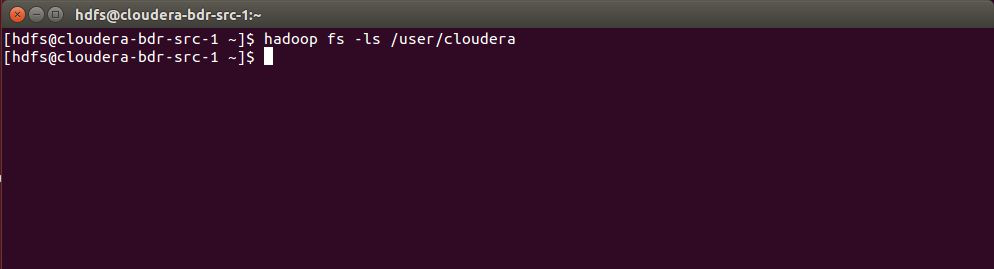
The example production cluster contains nine HDFS files in the /user/cloudera path:
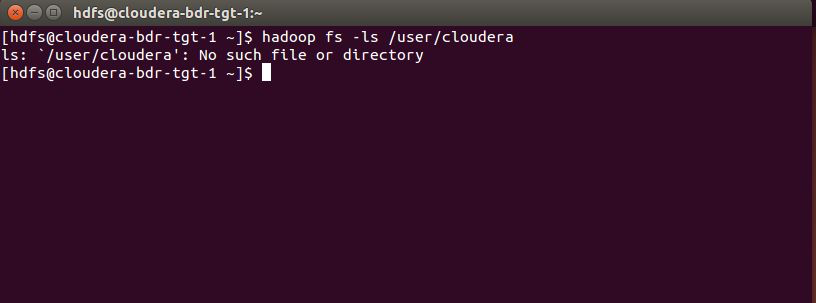
The example backup cluster has not been used as the destination of a replication schedule yet, so the HDFS file system has no /user/cloudera directory:
Backing Up and Restoring HDFS Data
This tutorial steps through the processes of creating and running a backup replication schedule, and creating a restore replication schedule designed for future use.
Preparing for disaster recovery includes these three major tasks:
- Backing Up HDFS Files
- Configuring a Restore Replication Schedule
- Recovering from Catastrophic Data Loss
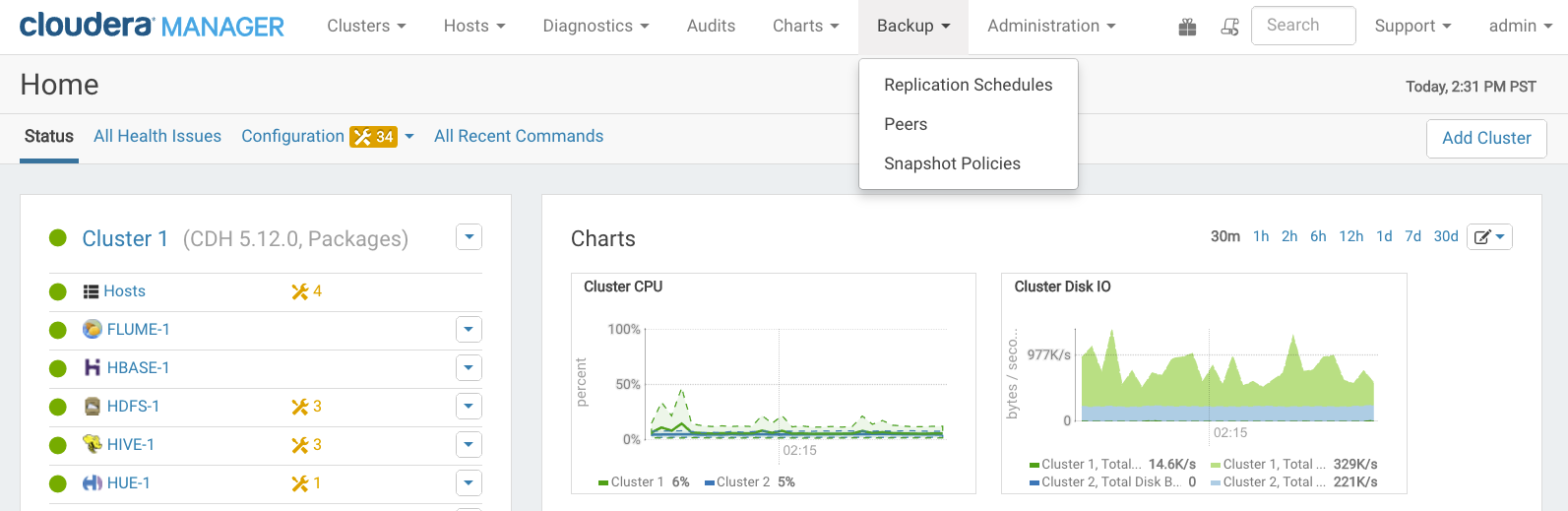
Backup and restore are both configured and managed using Replication Schedules, available from the Backup menu on Cloudera Manager Admin Console:
The backup and restore processes are configured, managed, and executed using replication schedules. Each replication schedule identifies a source and a destination for the given replication process. The replication process uses a pull model. When the replication process runs, the configured destination cluster accesses the given source cluster and transparently performs all tasks needed to copy the HDFS files to the destination cluster.
The destination cluster handles configuration and running the schedule. Typically, creating a backup replication schedule takes place on the backup cluster and creating a restore replication schedule takes place on the production cluster. Thus, as shown in this tutorial, the example production cluster, cloudera-bdr-src-{1..4}.cloud.computers.com, is the source for the backup replication schedule and the destination for the restore replication schedule.
Backing Up HDFS Files
The backup process begins at the Cloudera Manager Admin Console on the cluster designated as the backup, and includes these steps:
Step 1: Establish a Peer Relationship to the Production Cluster
For a backup, the destination is the backup cluster, and the source is the production cluster.
The cluster establishing the peer relationship gains access to the source cluster and can run the export command, list HDFS files, and read files for copying them to the destination cluster. These are all the actions performed by the replication process whenever the defined schedule goes into action.
Defining the replication starts from the Cloudera Manager Admin Console on the backup cluster.
- Log in to Cloudera Manager Admin Console on the backup cluster.
- Click the Backup tab and select Peers from the menu.
- On the Peers page, click Add Peer:
- On the Add Peer page:
- Peer Name - Enter a meaningful name for the cluster that you want to back up. This peer name becomes available in the next step, to be selected as the source for the replication.
- Peer URL - Enter the URL for the Cloudera Manager Admin Console running on the master node of the cluster.
- Peer Admin Username - Enter the administrator user account for the production cluster.
- Peer Admin Password - Enter the password for the administrator account for the production cluster.
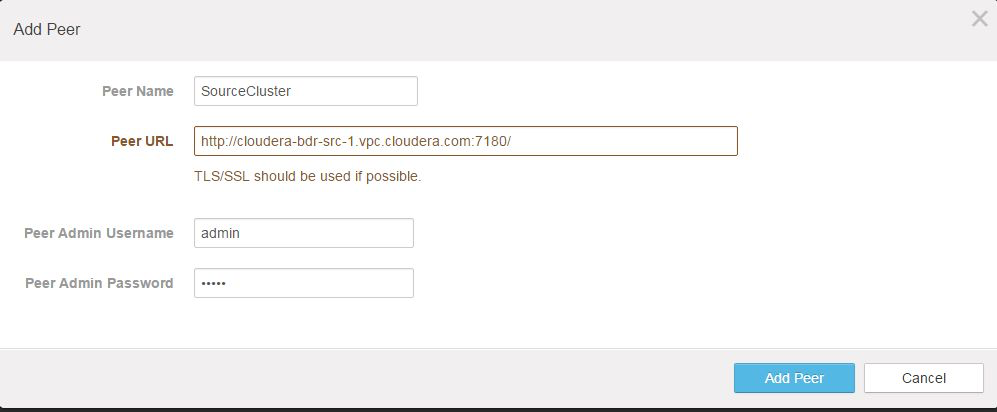
- Click Add Peer to save your settings, connect to the production cluster, and establish this peer relationship.
After the system establishes and verifies the connection to the peer, the Peers page re-displays, showing the Status column as Connected (note the green check-mark):

With the peer relationship established from destination to source, create a schedule to replicate HDFS files from the source (production cluster) to the destination (backup cluster).
Step 2: Configure the Replication Schedule for the Backup
From the Cloudera Manager Admin Console on the backup cluster:
- Click the Backup tab and select Replication Schedules from the menu.
- On the Replication Schedules page, select .
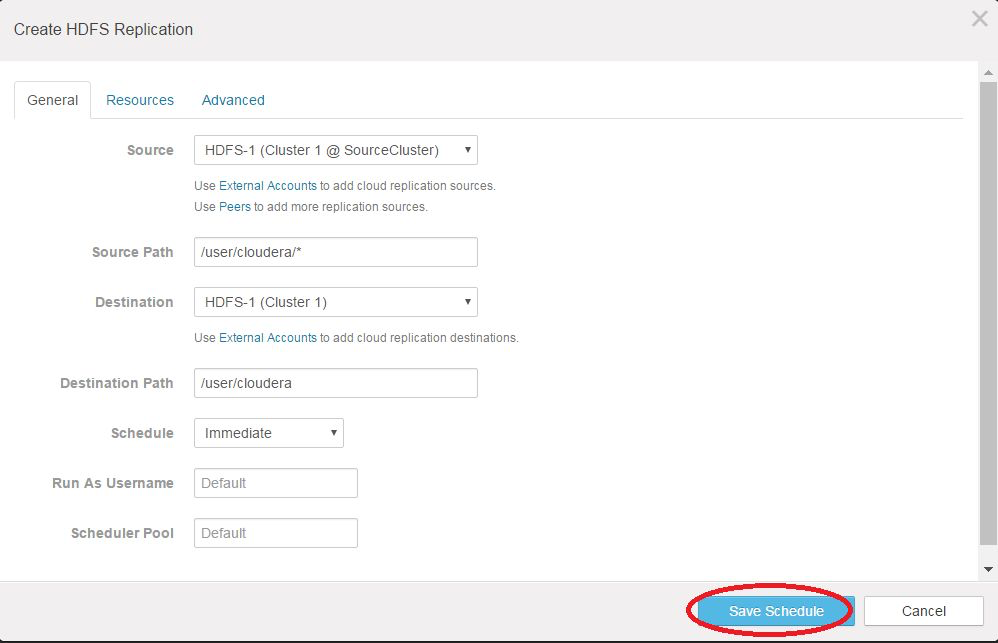
- On the Create HDFS Replication page, click the General tab to display the default schedule options:
- Source - Make sure the cluster node selected in the drop-down is the production cluster (the cluster to be backed up).
- Source Path - Specify the directory name on the production cluster holding the files to back up. Use an asterisk (*) on the directory name to specify that only the explicit directory and no others should be created on the destination. Without the asterisk, directories may be nested inside a containing directory on the destination.
- Destination - Select the cluster to use as the target of the replication process, typically, the cluster to which you have logged in and the cluster to which you want to backup HDFS data.
- Destination Path - Specify a directory name on the backup cluster.
- Schedule - Immediate.
- Run As Username - Leave as Default.
- Scheduler Pool - Leave as Default.
- Click Save Schedule.
The files are replicated from the source cluster to the backup cluster immediately.
When the process completes, the Replication Schedules page re-displays, showing a green check-mark and time-stamp in the Last Run column.
Step 3: Verify Successful Replication
Verify that the HDFS files are now on the backup cluster by using the HDFS File Browser or the hadoop fs -ls command (shown below):
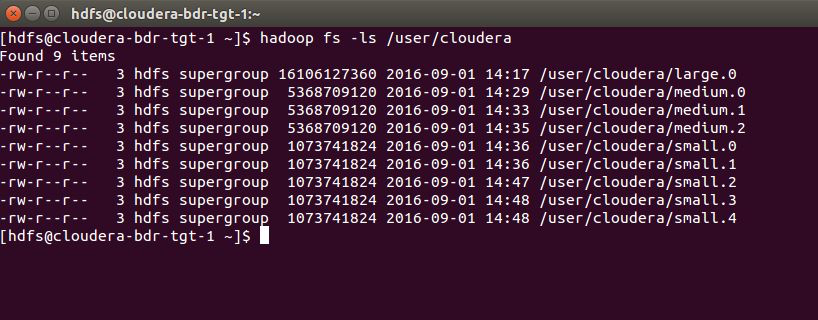
The HDFS files are now on both the production cluster and the backup cluster.
You can now use the backup as a source for a restore onto the production system when needed.
Configuring a Restore Replication Schedule
To restore data from a backup, configure a Restore Schedule on the cluster to which you want the data pulled. For this example, the replication schedule is created on the example production cluster and designed to pull HDFS files from the backup cluster to a different path on the production cluster, to enable testing the restore process in advance of any failure.
Setting up a schedule for a restore follows the same pattern as setting up the backup, but with all actions initiated using the Cloudera Manager Admin Console on the production cluster.
To set up and test a replication schedule to restore HDFS from an existing backup copy, follow these steps:
Step 1: Establish a Peer Relationship to the Backup Cluster
To restore HDFS files on the production cluster, establish a Peer relationship from the destination to the source for the restore.
Log in to the Cloudera Manager Admin Console on the production cluster.
- Click the Backup tab and select Peers from the menu.
- On the Peers page, click Add Peers.
- On the Add Peer page:
- Peer Name - Enter a meaningful name for the cluster that you want to restore data from, for example, BackupCluster.
- Peer URL - Enter the URL for the Cloudera Manager Admin Console running on the master node of the cluster.
- Peer Admin Username - Enter the administrator user name for the peer cluster.
- Peer Admin Password - Enter the password for the administrator user account.
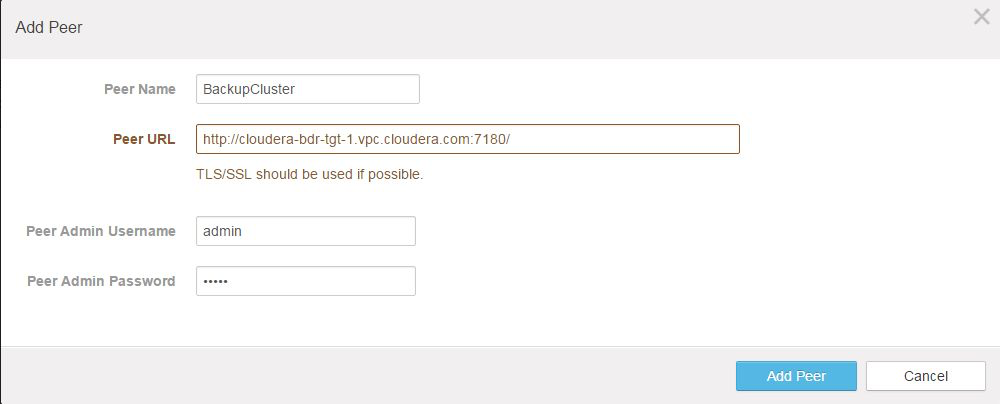
- Click Add Peer to save the settings, connect to the backup cluster, and establish the peer relationship.
Once the system connects and tests the peer relationship, the Peers page lists its name, URL, and Status (Connected):

The backup cluster is now available as a peer, for use in a Replication Schedule.
Step 2: Configure Replication Schedule to Test the Restore
The goal in these steps is to create a replication schedule that can be used when needed, in the future, but to leave it in a disabled state. However, because Replication Schedules cannot be created in a disabled state, you initially set the date far into the future and then disable the schedule in a subsequent step.
From the Cloudera Manager Admin Console on the production cluster:
- Click the Backup tab and select Replication Schedules from the menu.
- On the Replication Schedules page, select .
- On the General settings tab of the Create HDFS Replication page:
- Source - Make sure the cluster node selected in the drop-down is the backup cluster.
- Source Path - Specify the directory name that you want to back up. Use an asterisk (*) on the directory name to specify that only the explicit directory and no others should be created on the destination.
- Destination - Select the cluster to use as the target for the replication process.
- Destination Path - Specify a directory name on the backup cluster.
- Schedule - Set to a time far in the future, so that the schedule does not run as soon as it is saved.
- Run As Username - Leave as Default.
- Scheduler Pool - Leave as Default.
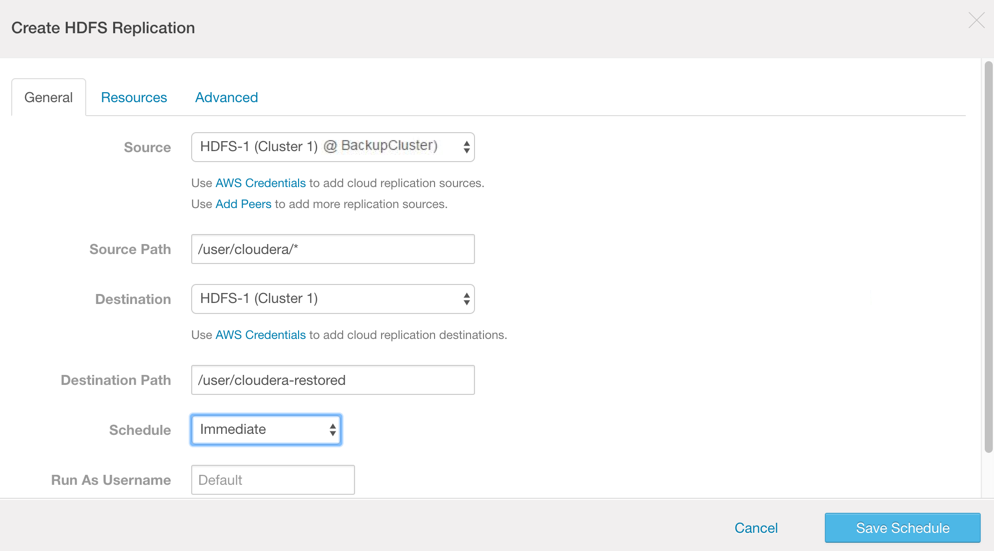
- Click Save Schedule.
The Replication Schedule is saved and displays in the Replication Schedules list, with the future date listed in the Next Run column.
Before continuing, immediately disable this newly created Replication Schedule.
Step 3: Disable the Replication Schedule
- On the Replication Schedules page, select the replication schedule.
- From the Actions drop-down menu, select Disable. When the page refreshes, Disabled displays in the Next Run column:
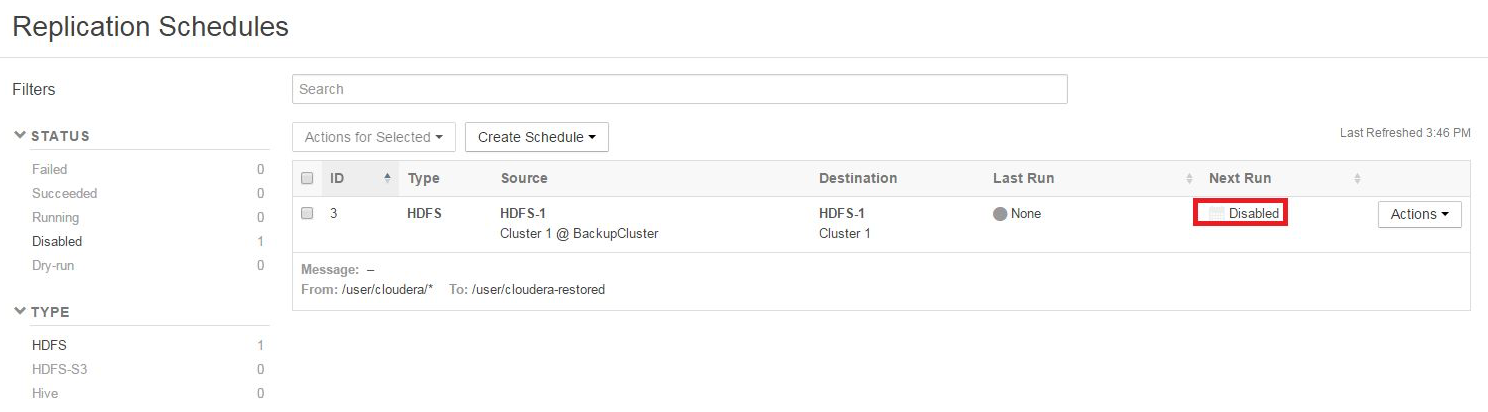
You can leave restore Replication Schedules pre-configured and disabled in this way so they are ready to use in the event of a catastrophic data loss. Before relying on this approach, test the schedule.
Step 4: Test the Restore Replication Schedule
The Replication Schedule defined in the example restores data to a specific directory path identified for the purpose of restoration (/user/cloudera-restored) rather than targeting the original source directory path.
From the Cloudera Manager Admin Console on the production cluster, with Replication Schedules page displayed:
- On the Replication Schedules page, select the disabled replication schedule.
- Select .
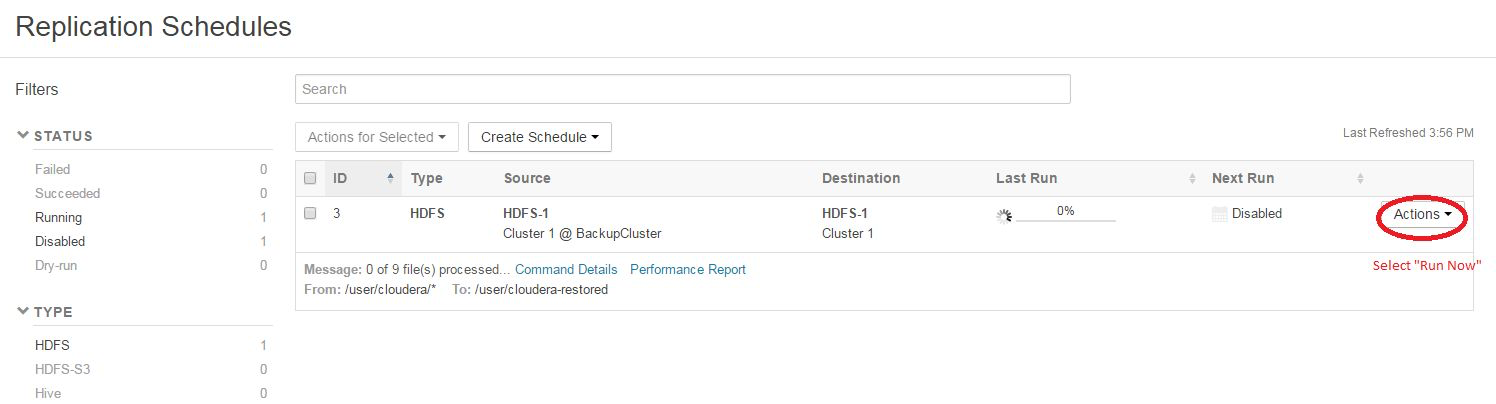
When the replication process completes, disable the Replication Schedule once again:
- On the Replication Schedules page, select the replication schedule.
- Select .
You can now verify that the files have been replicated to the destination directory path.
Step 5: Verify Successful Data Restoration
To manually verify that your data has been restored to the source cluster, you can use the HDFS File Browser or the hadoop command-line, as shown here:
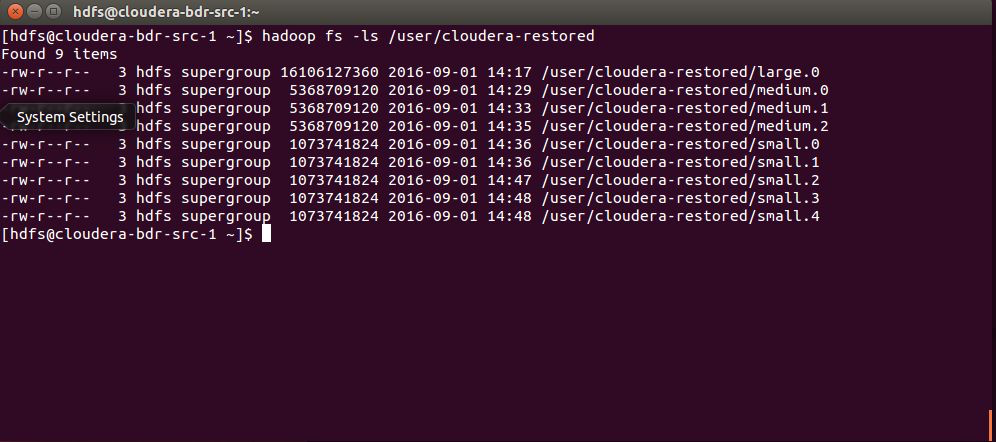
Compare the restored data in /user/cloudera-restored to the data in /user/cloudera to validate that the restore schedule operates as expected.
At this point, until you need to actually restore production HDFS data files, you can leave the Replication Schedule disabled.
Recovering from Catastrophic Data Loss
With backup and restore Replication Schedules set up and validated, you can restore data when production data has been erroneously deleted, as shown in this screenshot:
In the event of an actual data loss on a production cluster, you should first disable any existing replication schedules for the affected datasets before activating a replication schedule for the restore, to avoid overwriting existing replicas on the backup cluster with defective files.
Step 1: Disable the Backup Replication Schedule
Disabling any existing replication schedule for HDFS backups can help prevent the replication of lost or corrupted data files over existing backups.
At the Cloudera Manager Admin Console on the backup cluster:
- Select .
- On the Replication Schedules page, select the schedule.
- From the Actions drop-down menu, select Disable:
When the Replication Schedules pages refreshes, you see Disabled in the Next Run column for the schedule.
Step 2: Edit the Existing Replication Schedule
With the replication schedule disabled, you can edit the replication schedule verified previously (Step 4: Test the Restore Replication Schedule) and restore the data to the production cluster.
From the Cloudera Manager Admin Console on the production cluster:
- Click the Backup tab and select Replication Schedules from the menu.
- On the Replication Schedules page, select .
- On the General settings tab of the Create HDFS Replication page:
- Source - Name of the backup cluster from which to pull the data. For this example, the source is the backup cluster.
- Source Path - The path on the backup cluster that contains the data you want to restore. Use the asterisk (*) at the end of the directory name to prevent extraneous sub-directories being created on the destination.
- Destination - The name of the cluster on which to restore the data, in which case, the example production cluster.
- Destination Path - Directory in which to restore the HDFS data files, in this case, the directory on the example production system.
- Schedule - Once.
- Start Time - Leave set to the future date and time that you originally defined in Step 2: Configure Replication Schedule to Test the Restore.
- Run as Username - Leave set as Default.
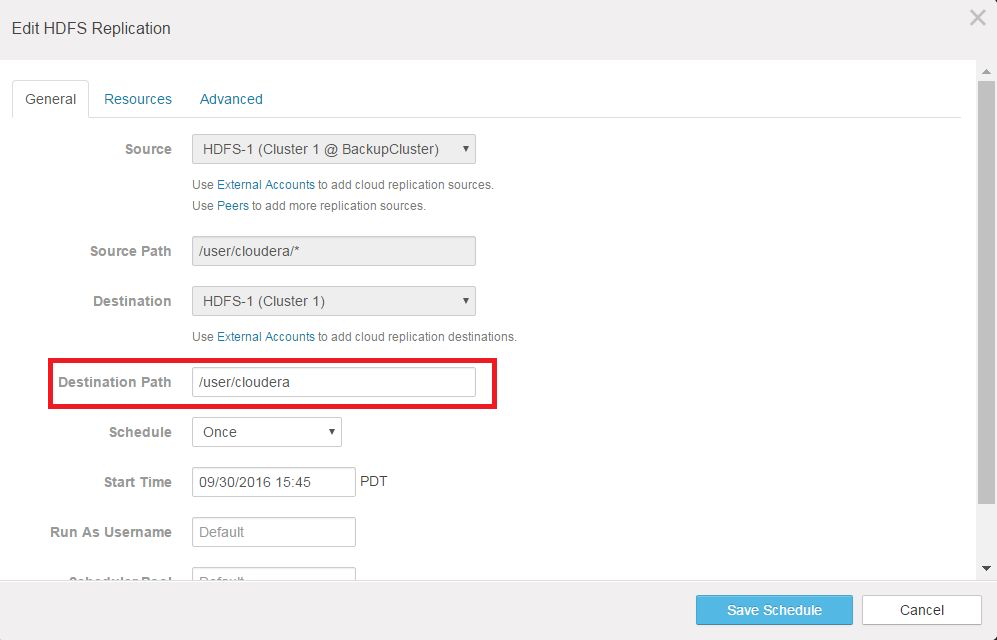
- Click Save Schedule.
The settings for the Replication Schedule are saved, and the page refreshes. Because this replication schedule is currently disabled, you must actively run the schedule to restore the data.
Step 4: Return the Restore Replication Schedule to a Disabled State
You can now disable the schedule, and after verifying that HDFS data has been successfully restored to the production cluster, you can re-enable the backup schedule. While still displaying the Replication Schedules page on the production cluster:
- Select the replication schedule used for the restore.
- Edit its configuration again, to point to a non-production directory.
- Select .
After confirming that the schedule has been disabled—you see Disabled in the Next Run column for this schedule—but before re-enabling the backup schedule, verify that the HDFS files have been restored to the production cluster.
Step 5: Re-enable the Backup Replication Schedule
With data restored to the production cluster and the replication schedule on the production cluster disabled, you can re-enable the replication schedule on the backup cluster.
- At the backup cluster, log in to the Cloudera Manager Admin Console.
- Select .
- On the Replication Schedules page, select the appropriate replication schedule to back up the production cluster.
- From the Actions drop-down menu, select Enable.
This concludes the tutorial. In an actual production environment, you should configure replication schedules to regularly backup production systems. For restoring files from any backup, you can create and test a replication schedules in advance, as shown in this tutorial.
Alternatively, you can create a replication schedule to restore data specifically when needed. See How To Back Up and Restore Apache Hive Data Using Cloudera Enterprise BDR for details.
See Backup and Disaster Recovery and BDR Tutorials for more information about Cloudera Enterprise BDR.
