
Tuning Hive Virtual Warehouses on private clouds
This topic describes how to tune Hive Virtual Warehouses in Cloudera Data Warehouse (CDW) Private Cloud.
When you tune Hive Virtual Warehouses, you set the auto-suspend timeout, the minimum and maximum number of nodes for your virtual cluster, when your cluster should scale up, and when it should scale down.
-
In the Overview page under Virtual Warehouses, click

against the required virtual warehouse and select Edit. -
Click the SIZING AND SCALING tab to view the properties that you
can adjust to tune auto-scaling for your data warehouse:
-
Set the AutoSuspend Timeout property under Auto scale, which
determines how many seconds the warehouse cluster is idle before it suspends
itself:
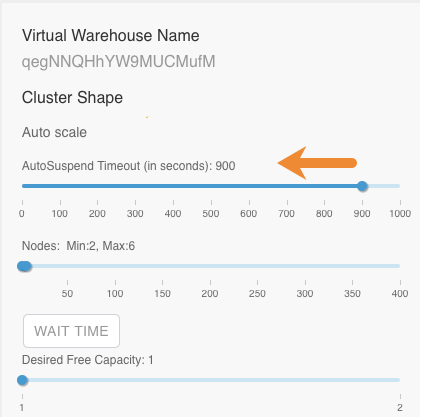
This setting helps to ensure performance is not impacted by having idle resources.
-
Set the minimum and maximum number of nodes that the cluster can contain:
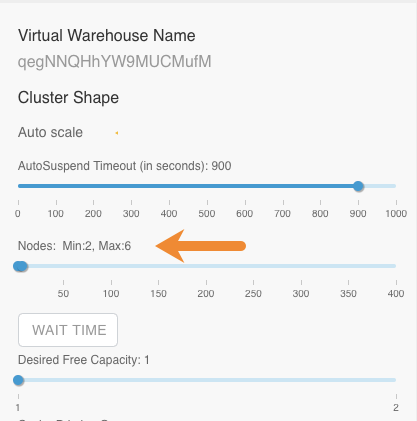
Use the minimum number of nodes setting to ensure that your workloads always have resources and use the maximum number of nodes setting to contain having too many idle resources. Decide the minimum and maximum number of nodes based on your workloads similarly to how you determine node counts for your on-premises clusters. Consider the number of concurrent queries, the complexity of queries, and the volume of queries in your workloads to determine the appropriate number of nodes to set on each Virtual Warehouse instance.
-
Set the AutoSuspend Timeout property under Auto scale, which
determines how many seconds the warehouse cluster is idle before it suspends
itself:
