
Configuring HWC in CDP Data Center
In CDP Data Center, HWC processes data through the Hive JDBC driver. You must configure processing based on your use case.
- cluster
- client
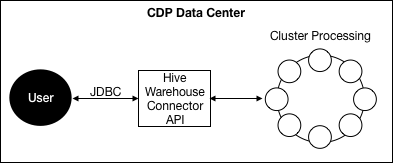
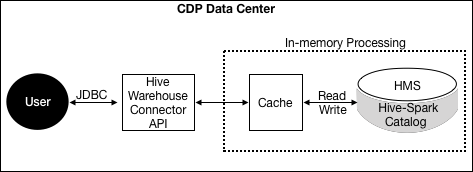
Configuring HWC mode reads
The following software and property settings are required for connecting Spark and Hive using the HiveWarehouseConnector library:
- Spark 2.4.x
- Hive JDBC database driver
Download the Hive JDBC database driver from the Cloudera Downloads page.
configuration/spark-defaults.conf. Alternatively, you can set the
properties using the spark-submit/spark-shell --conf option. -
spark.datasource.hive.warehouse.read.via.llap.Because LLAP is not supported in this release, you need to run HWC in JDBC mode. To run HWC in JDBC mode, set this property to false.
spark.datasource.hive.warehouse.read.jdbc.modeConfigures the JDBC mode. Values:
cluster(recommended) orclient(if the resultset will fit in memory)spark.sql.hive.hiveserver2.jdbc.urlThe Hive JDBC url in /etc/hive/conf/beeline-site.xml.
spark.datasource.hive.warehouse.metastoreUriURI of Hive metastore. In Cloudera Manager, click , search for
hive.metastore.uris, and use that value.spark.datasource.hive.warehouse.load.staging.dirTemporary staging location required by HWC.
Set the value to a file system location where the HWC user has write permission.
| Tasks | HWC Required | Recommended HWC Mode |
|---|---|---|
| Read Hive managed tables from Spark | Yes | JDBC mode=cluster |
| Write Hive managed tables from Spark | Yes | N/A |
| Read Hive external tables from Spark | Ok, but unnecessary | N/A |
| Write Hive external tables from Spark | Ok, but unnecessary | N/A |
Some configuration is required for enforcing Ranger ACLs. For more information, see Accessing Hive tables in HMS from Spark.
Authorization of read/writes of external tables from Spark
If you use HWC, HiveServer authorizes external table drops during query compilation. If you do not use the HWC, the Hive metastore (HMS) API, integrated with Ranger, authorizes external table access. HMS API-Ranger integration enforces the Ranger Hive ACL in this case.
For information about the authorization of external tables, see the section HMS Security (link below).
Spark on a Kerberized YARN cluster
For Spark applications on a kerberized Yarn cluster, set the following property:
spark.sql.hive.hiveserver2.jdbc.url.principal. This property must be
equal to hive.server2.authentication.kerberos.principal.
- Property:
spark.security.credentials.hiveserver2.enabled - Description: Use Spark ServiceCredentialProvider and set equal to a boolean, such as
true - Comment:
trueby default
