
Creating tables with Flink DDL
You can use Flink DDL to create tables or views by adding the CREATE statement to the Flink DDL window or filling out the Available templates.
When using Flink DDL, you have the option to either define your CREAT
TABLE statement using SQL in the Flink DDL window, or use the available
Flink DDL templates. The Flink DDL templates are predefined examples of CREATE
TABLE statements which you can fill out with your job specific values.
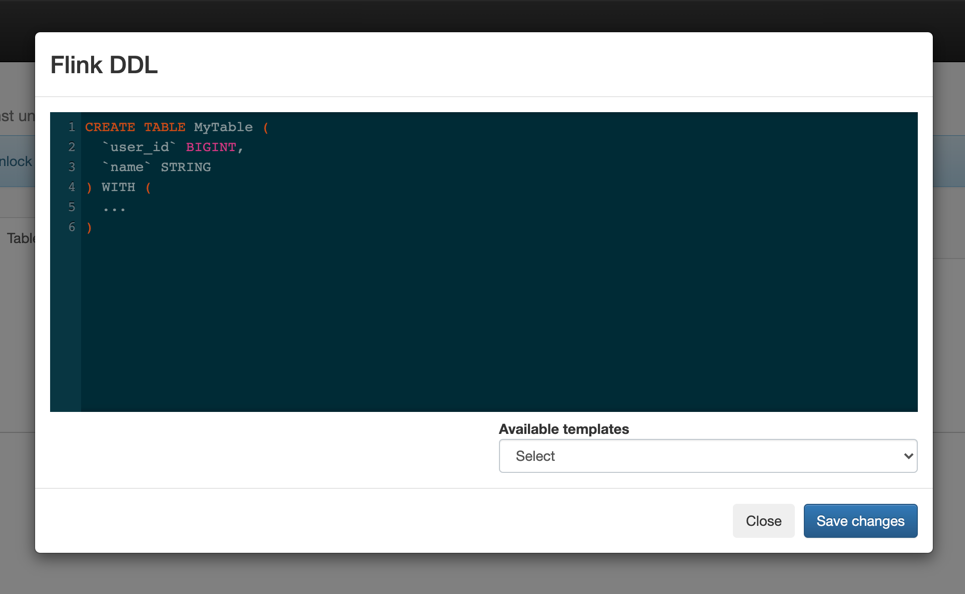
You can choose from the following templates:
CREATE TABLE like_table_sample (
-- new_time_col AS to_timestamp(time_col),
-- WATERMARK FOR new_time_col AS new_time_col - INTERVAL '5' SECOND
) WITH (
-- 'scan.startup.mode' = 'latest-offset'
)
LIKE kafka_table (
INCLUDING ALL
OVERWRITING OPTIONS
EXCLUDING GENERATED
)For full reference on the Flink SQL DDL functionality, see the official Apache Flink documentation.
