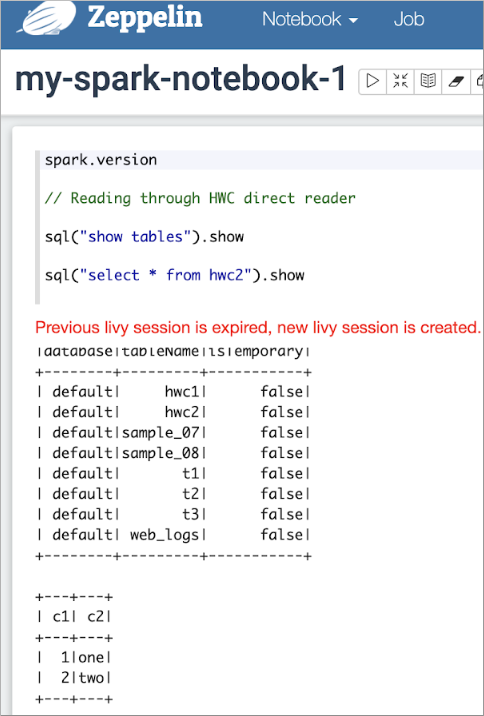
Reading and writing Hive tables in Zeppelin
You can read and write Hive ACID tables from a Spark application using Zeppelin, a browser-based GUI for interactive data exploration, modeling, and visualization.
-
In a Zeppelin notebook, read a Hive ACID table.
sql("show tables").show sql("select * from hwc2").show