To query, analyze, and visualize data stored within the Hortonworks Data Platform
using drivers provided by Hortonworks, you connect Hive to Business Intelligence (BI)
tools.
How you connect to Hive depends on a number of factors: the location of Hive inside
or outside the cluster, the HiveServer deployment, the type of transport, transport-layer
security, and authentication. HiveServer is the server interface that enables remote
clients to execute queries against Hive and retrieve the results using a JDBC or ODBC
connection. The ODBC driver from Simba and the Apache Hive JDBC driver is available for
download as described in the next topic. HDP installs the Hive JDBC driver on one of the
edge nodes in your cluster.
-
Locate the Apache Hive JDBC driver or download the ODBC driver.
-
Depending on the type of driver you obtain, proceed as follows:
- If you use the Simba ODBC driver, follow instructions on the ODBC driver
download site, and skip the rest of the steps in this procedure.
- If you use a Apache Hive JDBC driver, specify the basic JDBC connection
string as described in the following steps.
-
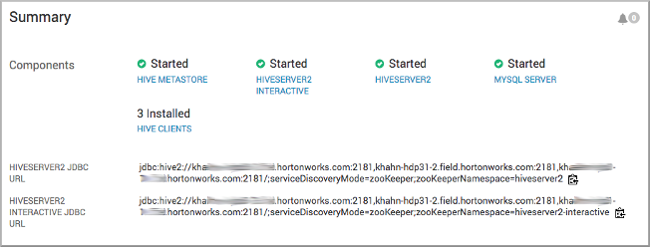
In Ambari, select .
-
Copy the JDBC URL for HiveServer: Click the clipboard icon.
-
Send the JDBC connection string to the BI tool, such as Tableau.