
Configuring sampling sink
The sample.sink.parameters configuration allows you to configure the sink used to retrieve sample results of a SQL query.
The parameter introduces key/value pairs which the system can use to configure the sink.
The current implementation uses a Kafka sink as the physical medium for storing the sample results, which means that you can use the configuration parameters of Kafka producers to configure the sink. You can configure any Kafka producer parameter based on your requirements.
For more information about Kafka producer configurations, see the Apache Kafka documentation.
As an example, the following parameters are configured for the sampling sink:
max.request.sizerequest.timeout.ms
The sample sink configuration in the example can be used when there is a need to increase the amount of data allowed to be sent with the producer to the Kafka sink. For example, the default configuration of the amount of data is set to 1M (1048576), which needs to be increased as more result records are expected. In this case, you need to set the sample sink configuration to a bigger amount in Cloudera Manager, for example 2M (2097152), as shown in the following image:
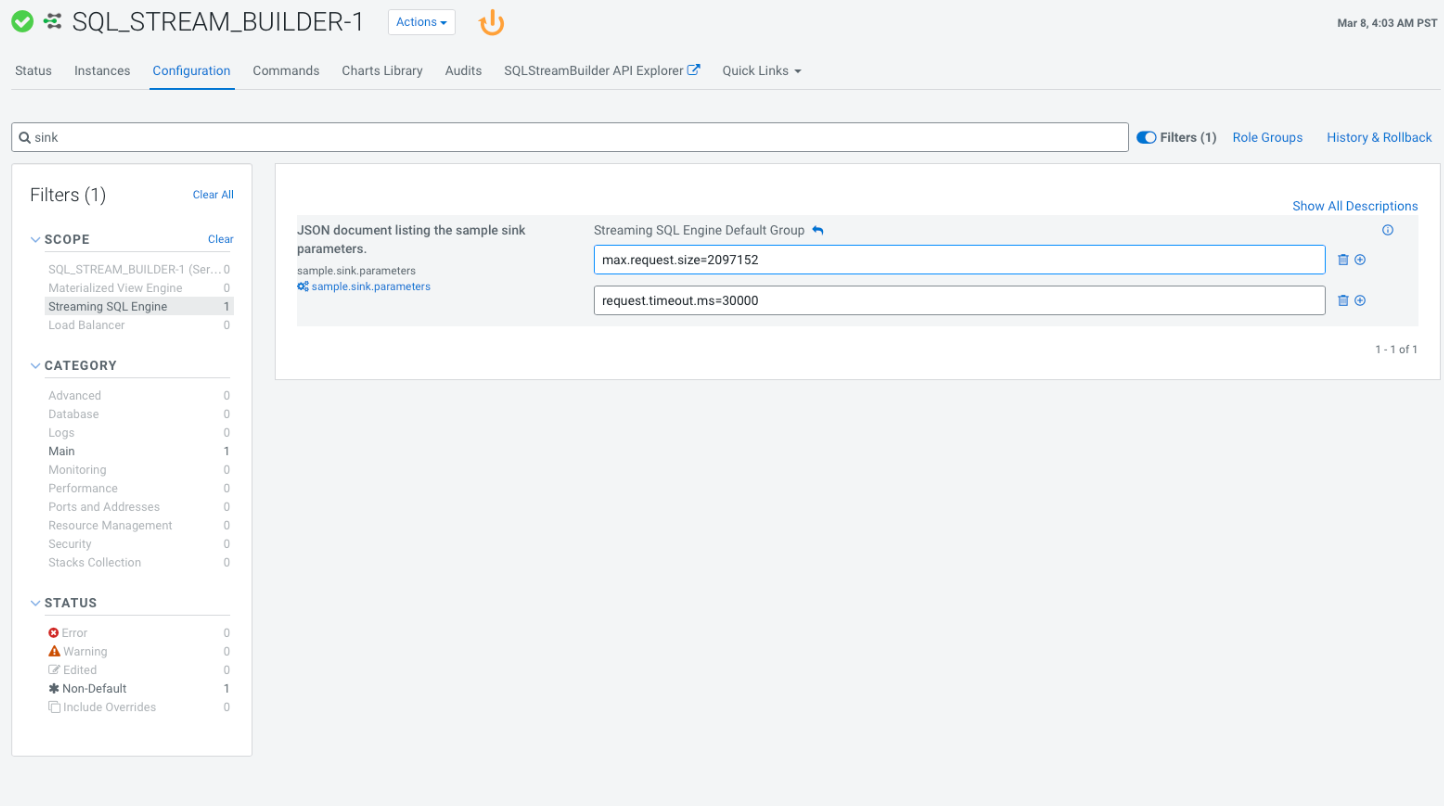
Configuring sampling parameter in Cloudera Manager
- Go to your cluster in Cloudera Manager.
- Select SQL Stream Builder from the list of services.
- Select Configuration.
- Search for sink using the search bar.
The sample.sink.parameters configuration is listed.
- Click the plus icon to add the Producer configuration.
- Add parameters to the sampling configuration.
For example,
max.request.sizeandrequest.timeout.msparameter. - Set the value based on your requirements.
- Click Save.
Sample sink configuration per job
When you configure the sample.sink.parameters in Cloudera Manager for SQL Stream Builder (SSB), the configuration is implemented on every sampling job no matter which user submits the SQL query. However, you can choose to configure the session to contain the specific sample.sink.parameter that only applies to the jobs submitted within the session.
sample.sink” prefix before the parameters to indicate that the setting
is applicable only for the sample sink. For example to increase the size of records to the
Producer of the Kafka sample sink, you need to add the Kafka parameter name after the
“sample.sink” prefix and add a needed
value:SET sample.sink.max.request.size=2097152This means that the command sets the
max.request.size parameter to 2097152
for the current session only.