Configuring external IDE Spark Connect sessions
Learn about how to configure a Spark Connect Session with Cloudera Data Engineering.
Before you create a Spark Connect Session, perform the following steps:
- Create a Cloudera Data Engineering Service.
- Create a Cloudera Data Engineering Virtual cluster. You must select All Purpose (Tier 2) in the Virtual Cluster option and Spark 3.4.1 as the Spark version.
- Initialize the virtual cluster.
- Initialize users in virtual clusters.
- If you are using an OpenShift cluster, then run the following
command:
$ oc -n openshift-ingress-operator annotate ingresscontrollers/default ingress.operator.openshift.io/default-enable-http2=true
-
Create a Spark Connect Session using one of the following methods:
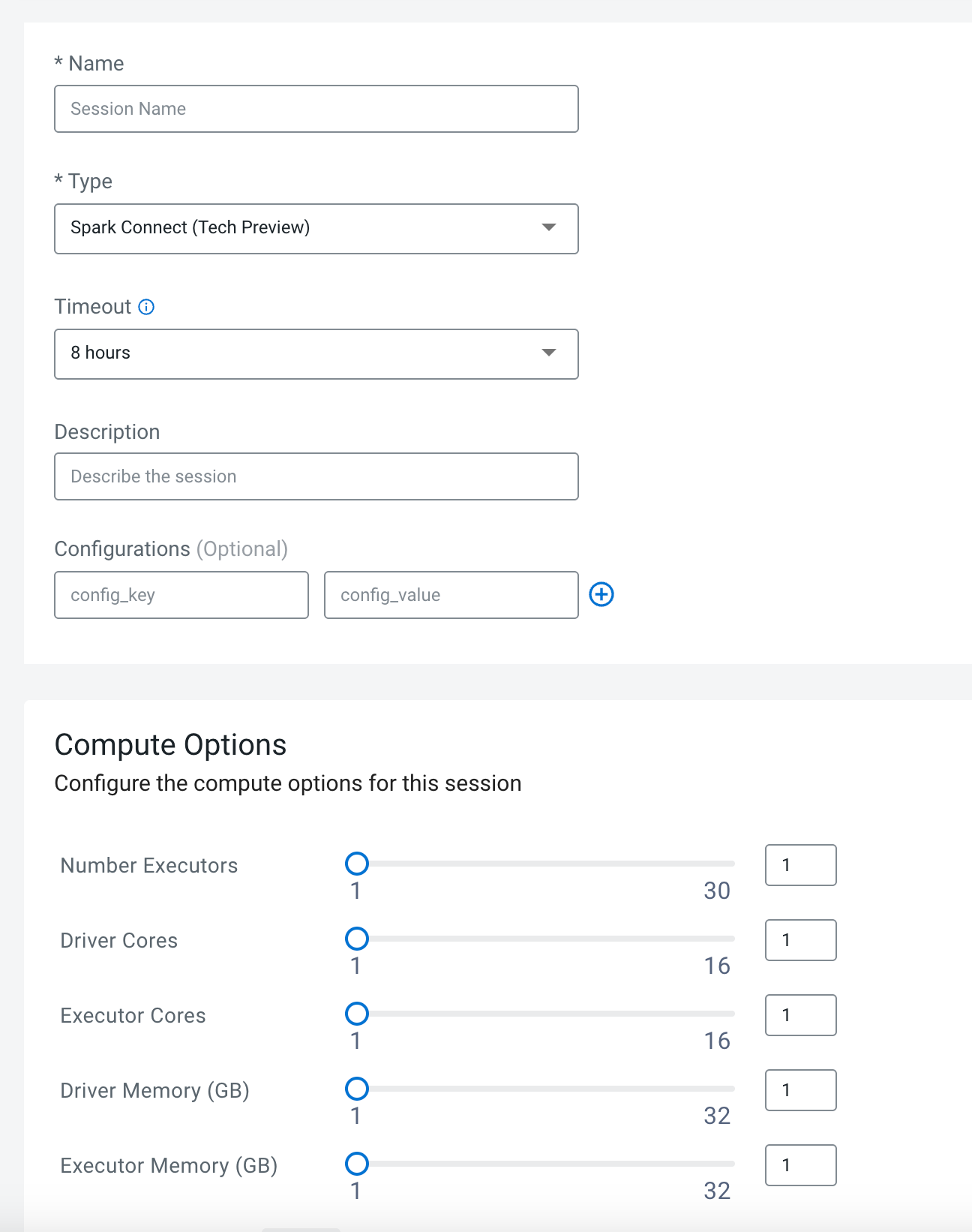
- Using the UI: Create a new session as per Creating Sessions
in Cloudera Data Engineering but when you select the session
type, select Spark Connect (Tech Preview) from the
Type drop-down list.
- Using the CLI: Create a Spark
Connect Session by running the following
command:
cde session create --name [***SPARK-SESSION-NAME***] --type spark-connect
- Using the UI: Create a new session as per Creating Sessions
in Cloudera Data Engineering but when you select the session
type, select Spark Connect (Tech Preview) from the
Type drop-down list.
-
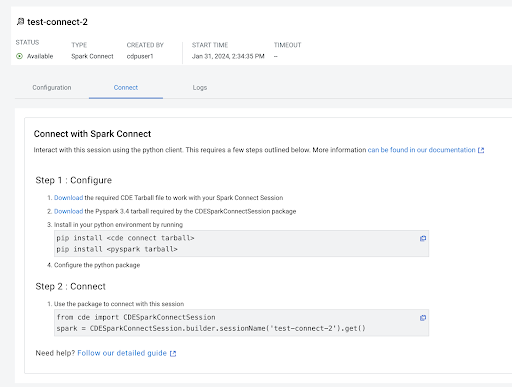
Go to the Connect tab and download the required Cloudera Data Engineering TAR
file and PySpark 3.4 TAR file as displayed on the
screen.