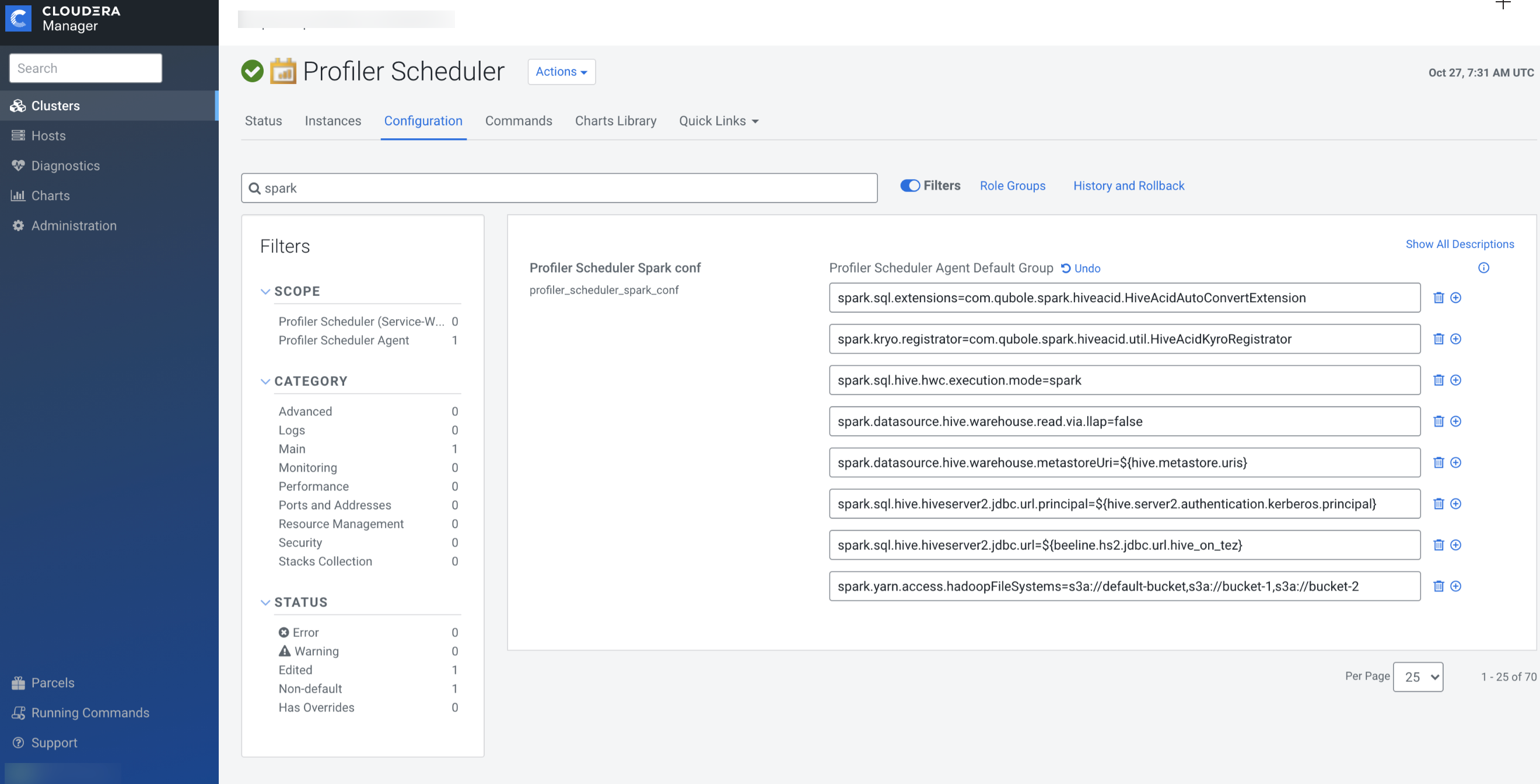
Profiling table data in non-default buckets
In VM-based environments, you must configure a parameter in Profiler Scheduler in your instance to profile table data in non-default buckets.
-
Add
spark.yarn.access.hadoopFileSystems=s3a://default-bucket,s3a://bucket-1,s3a://bucket-2to Profiler Scheduler Spark conf to enable profiling for bucket-1 and bucket-2 non-default buckets.