
Governance overview
Concepts for collecting, creating, and using metadata.
What is Apache Atlas?
Atlas is a metadata management and governance system designed to help you find, organize, and manage data assets. Atlas creates “entities” or metadata representations of objects and operations in your data lake. You can add business labels to these entities so you can use business vocabulary to make it easier to search for specific data.
Apache Atlas uses metadata to create lineage relationships
Atlas reads the content of the metadata it collects to build relationships among data assets. When Atlas receives query information, it notes the input and output of the query and generates a lineage map that traces how data is used and transformed over time. This visualization of data transformations allows governance teams to quickly identify the source of data and to understand the impact of data changes.
Your tags enhance your metadata, make it easier to search
Atlas manages labels, or “classifications,” that you associate with entities in your data lake. You can create and organize labels to use for anything from identifying data cleansing stages to recording user comments and insights on specific data assets. When you use classifications, the Atlas Dashboard makes it easy to search, group, report, and further annotate the entities you label. Classifications themselves can be organized into hierarchies to make them easier to manage.
Atlas also provides an infrastructure to create and maintain business ontologies to label your data assets. Atlas’ “glossaries” include “terms” so you can build agreed-upon lists for department- or organization-wide vocabulary to identify and manage data. Adding a term gives you a single-click report of entities identified by that term.
Apache Atlas architecture
Atlas runs as an independent service in a Hadoop environment. Many Hadoop data processing and storage services include Atlas add-ons that publish metadata for the services’ activities to a Kafka message topic. Atlas reads the messages and stores them in JanusGraph to model the relationships among entities. The datastore behind JanusGraph is HBase, though it can be configured with Cassandra. Atlas stores a search index in Solr to take advantage of Solr’s search functionality.
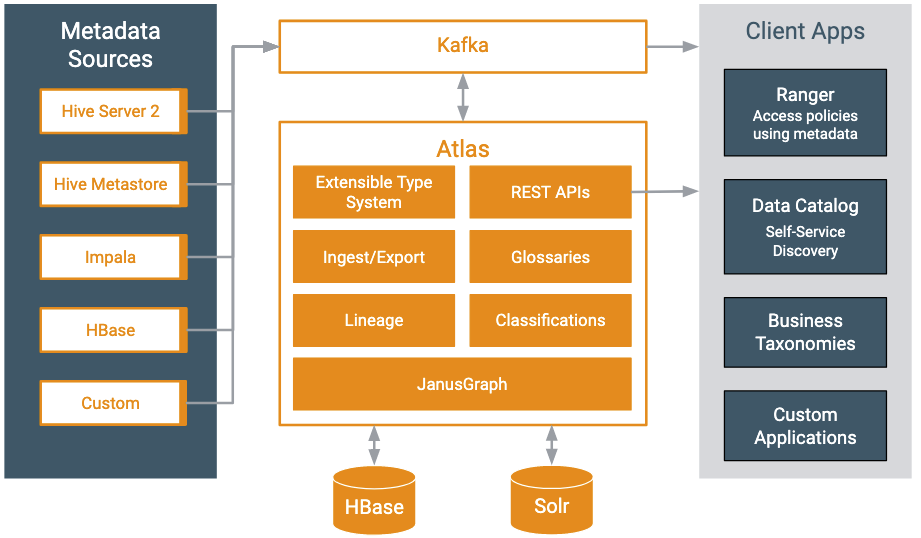
Many Hadoop services include addons or “hooks” that pass metadata to Atlas as the service performs actions against data. The Atlas hooks push metadata to a Kafka topic; the Atlas service reads these messages from the queue and creates the entities. Pre-defined hooks exist for Hive, Impala, HBase, Kafka, Spark, and Sqoop.
Atlas also provides “bridges” that import metadata for all of the existing data assets in a given source. For example, if you start Atlas after you’ve already created databases and tables in Hive, you can import metadata for the existing data assets using the Hive bridge. Bridges use the Atlas API to import the metadata.
If you need a hook or bridge to automate collecting metadata from another source, use the Atlas Java API to create one.
