Heterogeneous GPU clusters
When using heterogeneous GPU clusters to run sessions and jobs, the available GPU accelerator labels need to be selected during the creation of the workload.
Selecting GPUs for a workload
The workload configuration displays a dropdown menu for the possible GPU accelerator labels, available on the Kubernetes cluster.
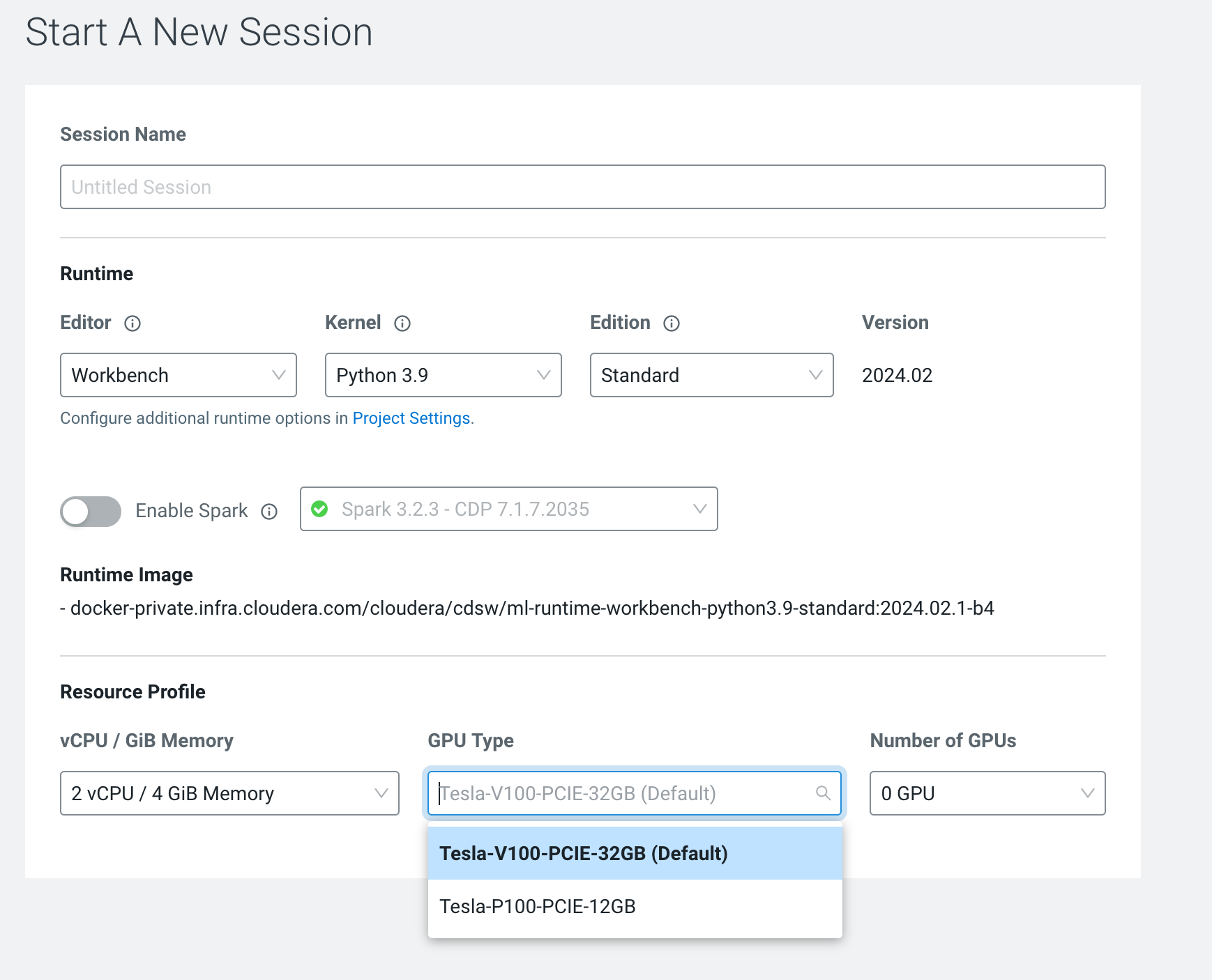
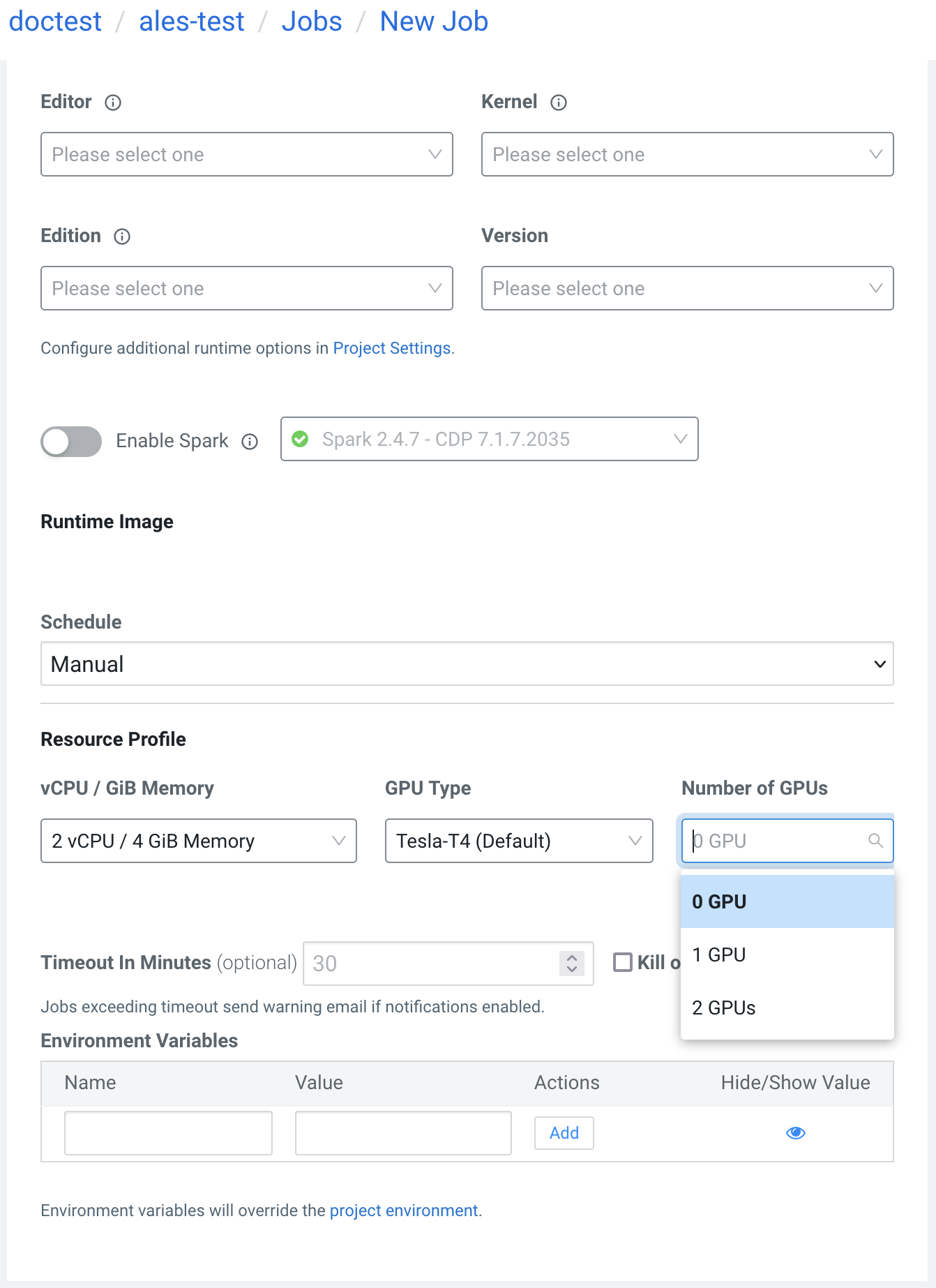
If you are unsure about which GPU accelerator label to use, you can use the default value set by the Cloudera AI Workbench administrator.
APIv2 GPU workloads
APIv2 GPU workloads can also target a specific GPU.
The following code example presents details on identifying the GPU accelerator label:
# Instantiate the cml api client
import cmlapi
client = cmlapi.default_client()
# List the available gpu accelerator labels
client.list_all_accelerator_node_labels()
# Use the gpu accelerator label in the request body of the workload
job_body = cmlapi.CreateJobRequest(
project_id="some_project_id",
name="job_with_gpu_accelerator",
script="some_job_script.py",
kernel="some_runtime_kernel",
runtime_identifier="some_runtime",
nvidia_gpu = 1,
accelerator_label_id = 2
)
apiv2client.create_job(
project_id="some_project_id", body=job_body)
Existing APIv2 calls which do not specify a GPU accelerator ID can be launched using the default GPU accelerator, set by the Cloudera AI Administrator.
A Cloudera AI workload is backed by a Kubernetes Pod, which can only reserve as many resources as there are available on a single node.