Deploying the Cloudera AI Workbench model
Deploy a Cloudera AI Workbench model following the instructions.
-
Deploy a model by setting the following details.
File: launch_model.py
Function: api_wrapper
Example input:{ "prompt": "How are you?", "max_length": 64, "temperature": "0.7" }Figure 1. Deploy a model 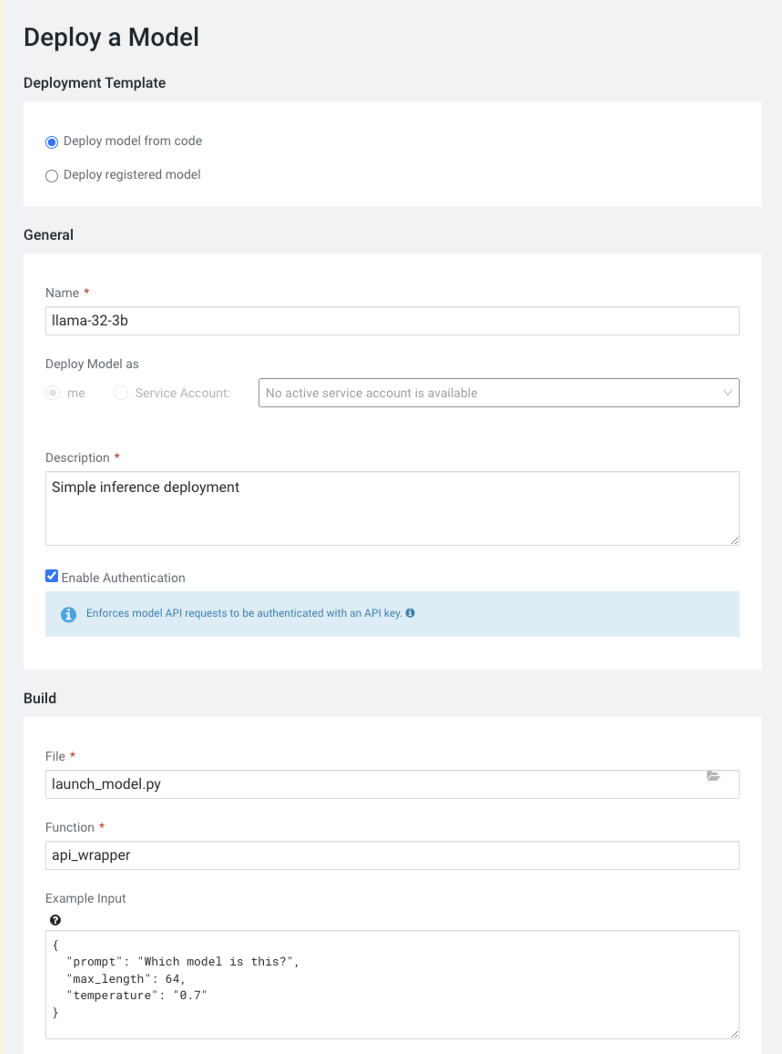
After successfully deploying the Cloudera AI Workbench model, you can find examples of how to access it and run a test inference on the Project Overview tab.