Understanding Indexing
The indexing topology is a topology dedicated to taking the data from a topology that has been enriched and storing the data in one or more supported indices. More specifically, the enriched data is ingested into Kafka, written in an indexing batch or bolt with a specified size, and sent to one or more specified indices. The configuration is intended to configure the indexing used for a given sensor type (for example, snort).
The following figure illustrates how the raw topology data is ingested, parsed, enriched, and finally delivered to a specified index:
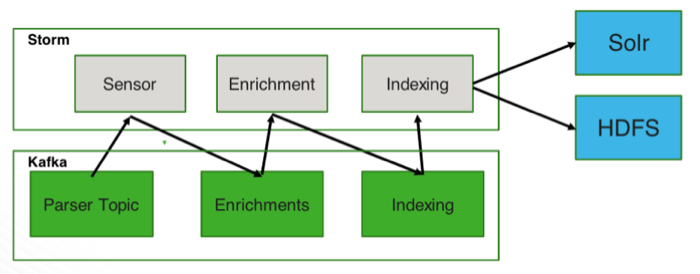
Currently, Cloudera Cybersecurity Platform (CCP) supports the following indices:
-
Solr
-
Elasticsearch
-
HDFS under
/apps/metron/enrichment/indexed
Depending on how you configure the indexing topology, it can have HDFS and either Elasticsearch or Solr writers running.
If you would like to view the sensor output in the Alerts user interface, you must configure the sensor for either Solr or Elasticsearch.
The Indexing Configuration file is a JSON file stored in Apache
ZooKeeper and on disk at $METRON_HOME/config/zookeeper/indexing.
Errors during indexing are sent to a Kafka queue called
index_errors.
Within the sensor-specific configuration, you can configure the individual writers. The following parameters are currently supported:
-
index -
The name of the index to write to (defaulted is the name of the sensor).
-
batchSize -
The size of the batch allowed to be written to the indices at once (defaulted is 1).
-
enabled -
Whether the index or writer is enabled (default is
true).