Insert data in test_table through Spark
Learn how to insert data using Spark.
- Identify a host to start a spark-shell on the
Compute cluster, Compute 2. Open the Cloudera Manager Admin Console and
go to .
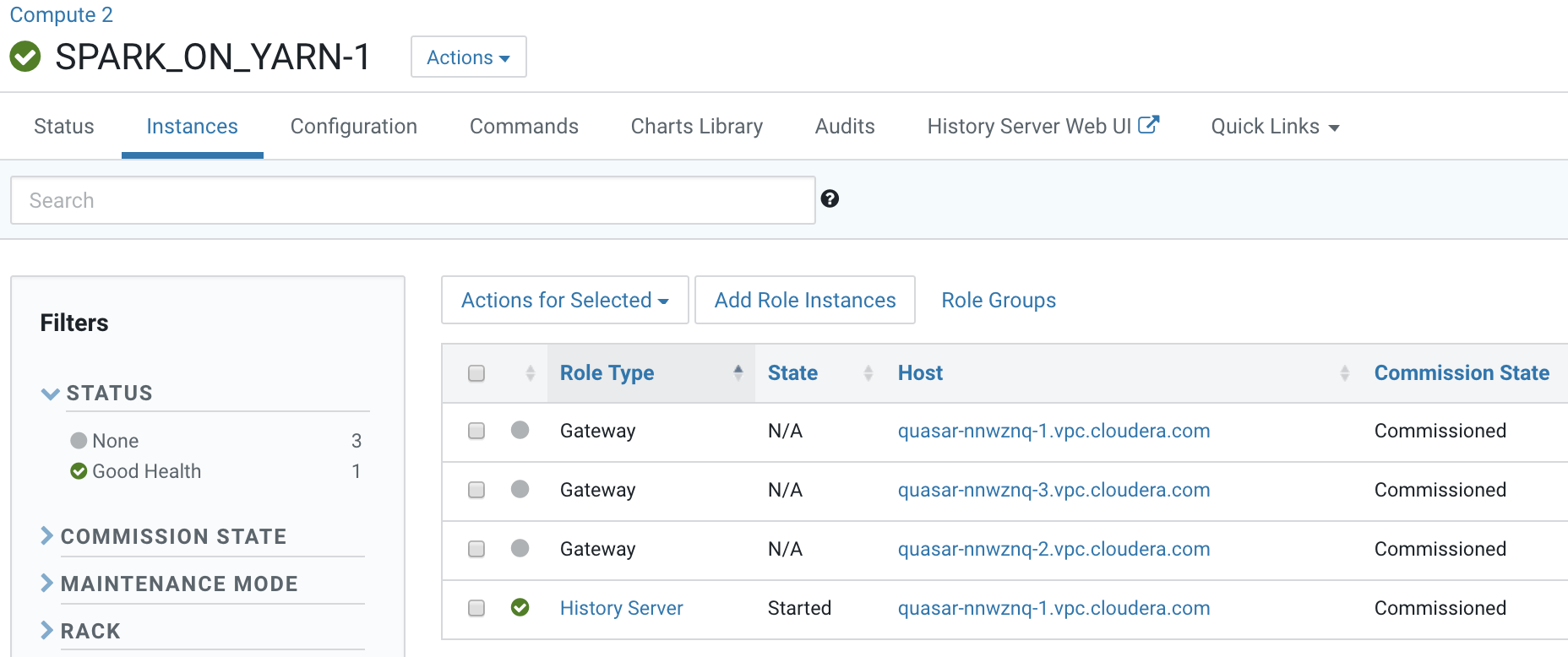
- Open a terminal session host <HiveServer2 Host URL>
- Verify access for the user:Assign the user starting spark-shell to a Linux group that has create/insert access configured in Sentry. .e. hive.
[root@vpc_host-nnwznq-1 ~]# usermod -aG hive systest
The user will also need to be created and added to the group on all the hosts of the Base cluster.
- kinit the
user:
[root@vpc_host-nnwznq-1 ~]# kinit -kt /cdep/keytabs/systest.keytab systest
- Start
spark-shell:
[root@vpc_host-nnwznq-1 ~]# sudo -u systest spark-shell
Setting default log level to "WARN". Spark context Web UI available at http://vpc_host-nnwznq-1.tut.myco.com:4043 Spark context available as 'sc' (master = yarn, app id = application_1552095496593_0007). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0-cdh6.2.0 /_/ scala> - Insert data into the
table:
scala> val insertData = sqlContext.sql("insert into test_data.test_table values (1998, 'France')")19/03/10 00:21:26 WARN shims.HdfsUtils: Unable to inherit permissions for file hdfs://ns1/user/hive/warehouse/test_data.db/test_table/part-00000-f0fc5e0d-daa3-4fe2-9ded-d62e1ef45ca9-c000 from file hdfs://ns1/user/hive/warehouse/test_data.db/test_table insertData: org.apache.spark.sql.DataFrame = []
scala> val tableTestData = sqlContext.sql("select * from test_data.test_table") tableTestData: org.apache.spark.sql.DataFrame = [year: int, winner: string] scala> tableTestData.show() +----+-------+ |year| winner| +----+-------+ |2002| Brazil| |2018| France| |2014|Germany| |2010| Spain| |2006| Italy| |1998| France| +----+-------+ - Verify and track the queries in the Yarn
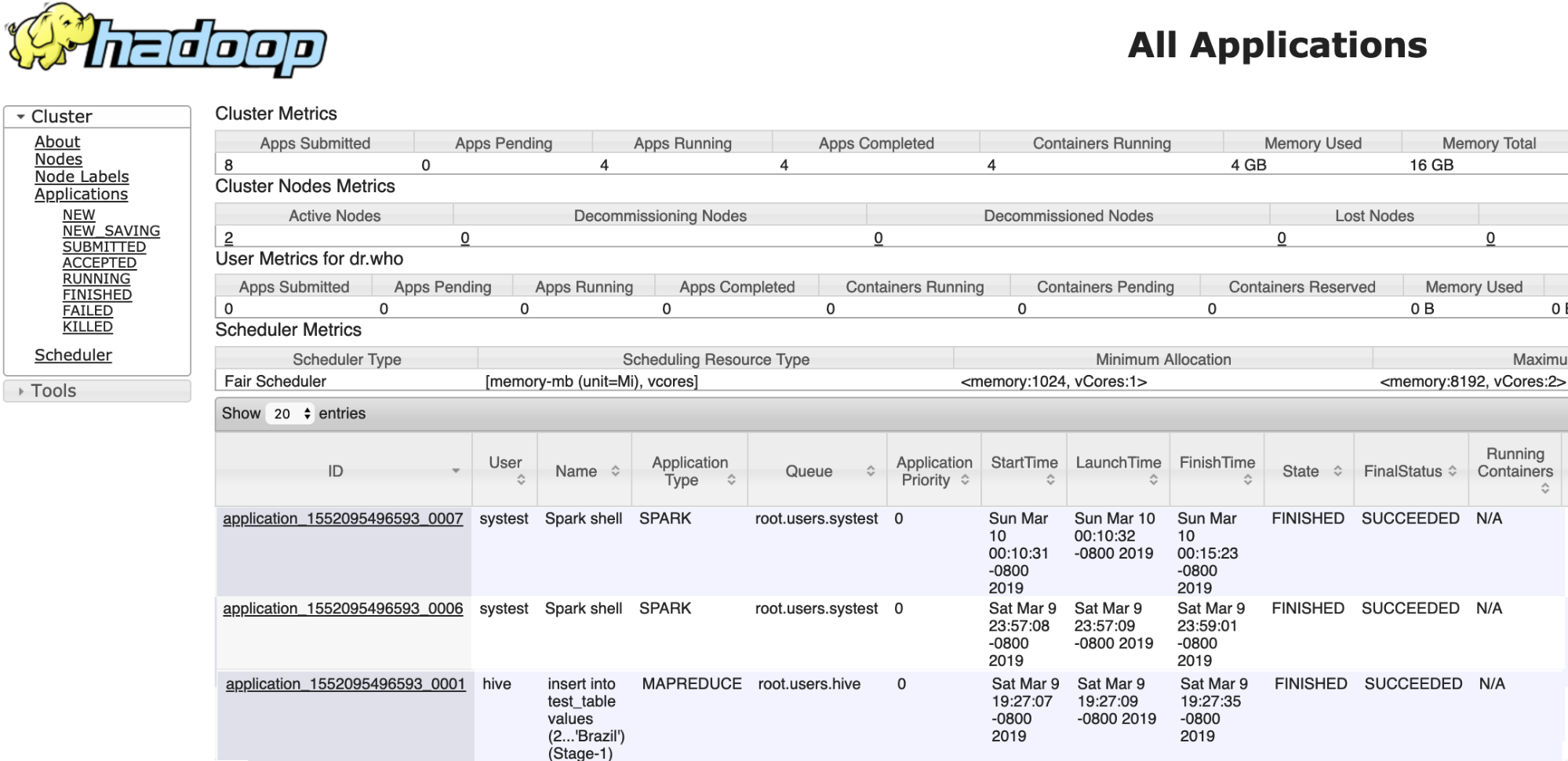
service application on the Compute cluster: