
Configuring Replication of Hive/Impala Data
You must set up your clusters before you configure Hive/Impala replication job.
- Verify that your cluster conforms to one of the supported replication scenarios.
- If the source cluster is managed by a different Cloudera Manager server than the destination cluster, configure a peer relationship.
- From Cloudera Manager > Replication page,
click Create Replication Policy.
- Select Hive Replication Policy.
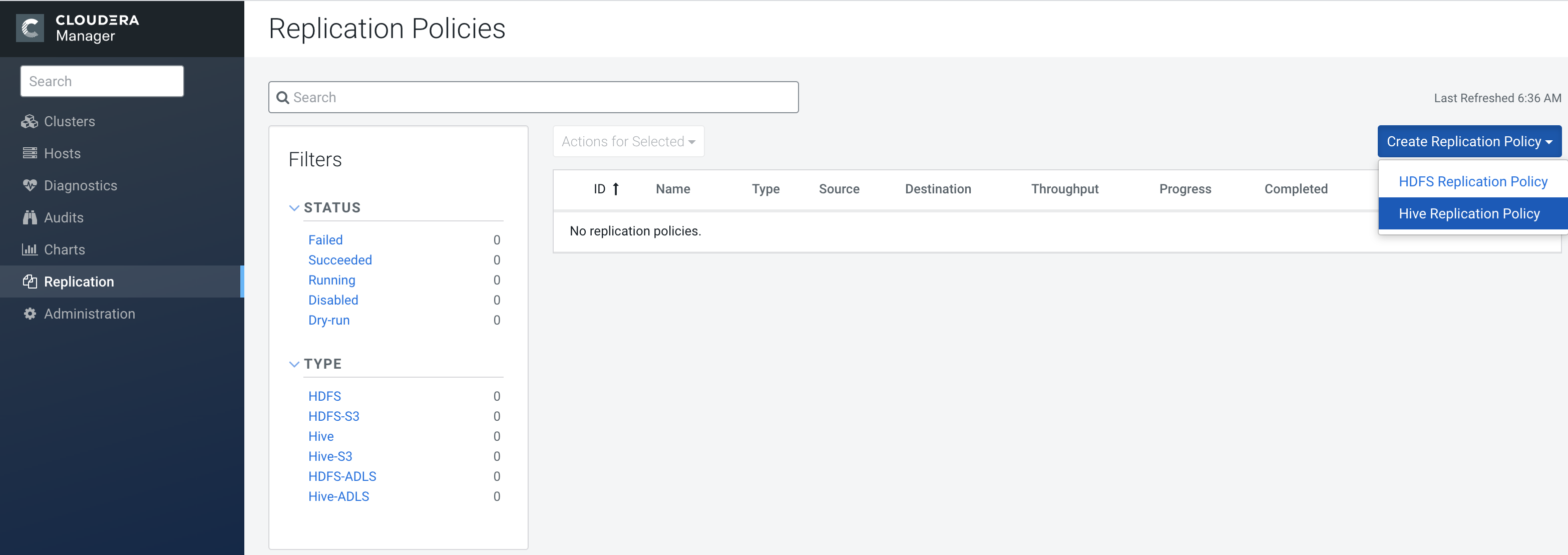
The Create Hive Replication Policy dialog box appears.
- Select the General tab to configure the following options:
- Use the Name field to provide a unique name for the replication policy.
- Use the Source drop-down list to select the cluster with the Hive service you want to replicate.
- Use the Destination drop-down list to select the destination for the replication. If there is only one Hive service managed by Cloudera Manager available as a destination, this is specified as the destination. If more than one Hive service is managed by this Cloudera Manager, select from among them.
- Based on the type of destination cluster you plan to use, select:
- Use HDFS Destination
- Select one of the following permissions:
- Do not import Sentry Permissions (Default)
- If Sentry permissions were exported from the CDH cluster, import both Hive object and URL permissions
- If Sentry permissions were exported from the CDH cluster, import only Hive object permissions
- Leave Replicate All checked to replicate all the Hive databases
from the source. To replicate only selected databases, uncheck this option and enter the
database name(s) and tables you want to replicate.
- You can specify multiple databases and tables using the plus symbol to add more rows to the specification.
- You can specify multiple databases on a single line by separating their names with
the pipe (|) character. For example:
mydbname1|mydbname2|mydbname3. - Regular expressions can be used in either database or table fields, as described
in the following table:
Regular Expression Result [\w].+
Any database or table name. (?!myname\b).+
Any database or table except the one named myname. db1|db2 [\w_]+
All tables of the db1 and db2 databases. db1 [\w_]+
Click the "+" button and then enter
db2 [\w_]+
All tables of the db1 and db2 databases (alternate method).
- To specify the user that should run the MapReduce job, use the Run As
Username option. By default, MapReduce jobs run as
hdfs. To run the MapReduce job as a different user, enter the user name. If you are using Kerberos, you must provide a user name here, and it must have an ID greater than 1000. - Specify the Run on peer as Username option if the peer cluster is configured with a different superuser. This is only applicable while working in a kerberized environment.
- Select the Resources tab to configure the following:
- Scheduler Pool – (Optional) Enter the name of a resource
pool in the field. The value you enter is used by the MapReduce
Service you specified when Cloudera Manager executes the MapReduce job for
the replication. The job specifies the value using one of these properties:
- MapReduce – Fair scheduler:
mapred.fairscheduler.pool - MapReduce – Capacity scheduler:
queue.name - YARN –
mapreduce.job.queuename
- MapReduce – Fair scheduler:
- Maximum Map Slots and Maximum Bandwidth – Limits for the number of map slots and for bandwidth per mapper. The default is 100 MB.
- Replication Strategy – Whether file replication should be static (the default) or dynamic. Static replication distributes file replication tasks among the mappers up front to achieve a uniform distribution based on file sizes. Dynamic replication distributes file replication tasks in small sets to the mappers, and as each mapper processes its tasks, it dynamically acquires and processes the next unallocated set of tasks.
- Scheduler Pool – (Optional) Enter the name of a resource
pool in the field. The value you enter is used by the MapReduce
Service you specified when Cloudera Manager executes the MapReduce job for
the replication. The job specifies the value using one of these properties:
- Select the Advanced tab to specify an export location, modify the
parameters of the MapReduce job that will perform the replication, and set other options.
You can select a MapReduce service (if there is more than one in your cluster) and change
the following parameters:
- Uncheck the Replicate HDFS Files checkbox to skip replicating the associated data files.
- If both the source and destination clusters use CDH 5.7.0 or later up to and including
5.11.x, select the Replicate Impala Metadata drop-down list and
select No to avoid redundant replication of Impala metadata.
(This option only displays when supported by both source and destination clusters.) You
can select the following options for Replicate Impala
Metadata:
- Yes – replicates the Impala metadata.
- No – does not replicate the Impala metadata.
- Auto – Cloudera Manager determines whether or not to replicate the Impala metadata based on the CDH version.
- The Force Overwrite option, if checked, forces overwriting data in the destination metastore if incompatible changes are detected. For example, if the destination metastore was modified, and a new partition was added to a table, this option forces deletion of that partition, overwriting the table with the version found on the source.
- By default, Hive metadata is exported to a default HDFS location
(
/user/${user.name}/.cm/hive) and then imported from this HDFS file to the destination Hive metastore. In this example,user.nameis the process user of the HDFS service on the destination cluster. To override the default HDFS location for this export file, specify a path in the Export Path field. - Number of concurrent HMS connections - The number of concurrent Hive Metastore
connections. These connections are used to concurrently import and export metadata from
Hive. Increasing the number of threads can improve Replication Manager performance. By
default, any new replication policies will use 5 connections.
If you set the value to 1 or more, Replication Manager uses multi-threading with the number of connections specified. If you set the value to 0 or fewer, Replication Manager uses single threading and a single connection.
Note that the source and destination clusters must run a Cloudera Manager version that supports concurrent HMS connections, Cloudera Manager 5.15.0 or higher and Cloudera Manager 6.1.0 or higher. - By default, Hive HDFS data files (for example,
/user/hive/warehouse/db1/t1) are replicated to a location relative to "/" (in this example, to/user/hive/warehouse/db1/t1). To override the default, enter a path in the HDFS Destination Path field. For example, if you enter/ReplicatedData, the data files would be replicated to/ReplicatedData/user/hive/warehouse/db1/t1. - Select the MapReduce Service to use for this replication (if there is more than one in your cluster).
- Log Path - An alternative path for the logs.
- Description - A description for the replication policy.
- Skip Checksum Checks - Whether to skip checksum checks, which are performed by default.
- Skip Listing Checksum Checks - Whether to skip checksum check when comparing two files to determine whether they are same or not. If skipped, the file size and last modified time are used to determine if files are the same or not. Skipping the check improves performance during the mapper phase. Note that if you select the Skip Checksum Checks option, this check is also skipped.
- Abort on Error - Whether to abort the job on an error. By selecting the check box, files copied up to that point remain on the destination, but no additional files will be copied. Abort on Error is off by default.
- Abort on Snapshot Diff Failures - If a snapshot diff fails during replication, Replication Manager uses a complete copy to replicate data. If you select this option, the Replication Manager aborts the replication when it encounters an error instead.
- Delete Policy - Whether files that were on the source should also be deleted from the destination directory. Options include:
- Preserve - Whether to preserve the Block Size, Replication Count, and Permissions as they exist on the source file system, or to use the settings as configured on the destination file system. By default, settings are preserved on the source.
- Alerts - Whether to generate alerts for various state changes in the replication workflow. You can alert On Failure, On Start, On Success, or On Abort (when the replication workflow is aborted).
- Click Save Policy.
The replication task appears as a row in the Replications Policies table.
To specify additional replication tasks, select .
