Determining the cause of slow and failed queries
You can identify the cause of slow query run times and queries that fail to complete using Cloudera Observability.
Steps with examples from a Virtual Cluster's Spark engine are used to explain how to further investigate and troubleshoot the cause of slow query run times.
-
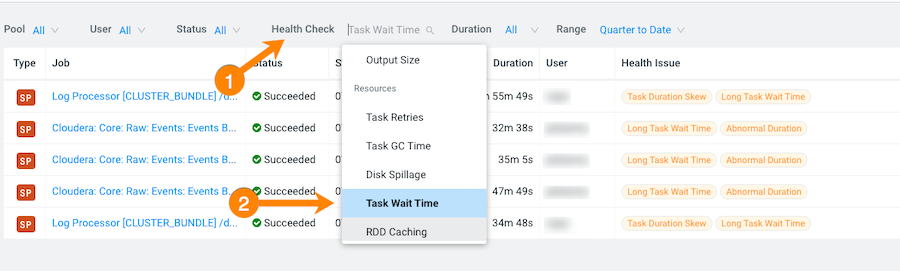
From the Health Check filter's list, select
Task Wait Time, which filters and displays a list of
jobs with longer than average wait times before the process was executed.
-
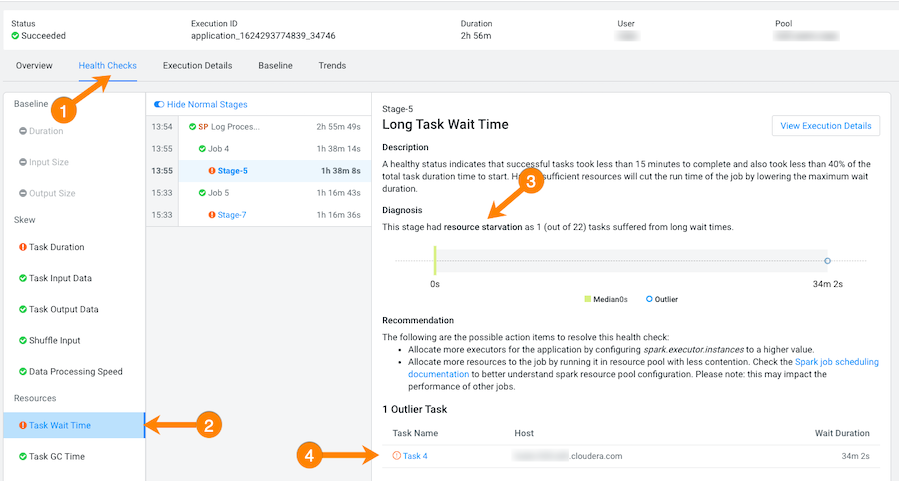
From the Health Checks panel on the left, click the
Task Wait Time health check, which opens a panel that
describes the health check, displays information about the possible causes, and
lists recommended solutions.
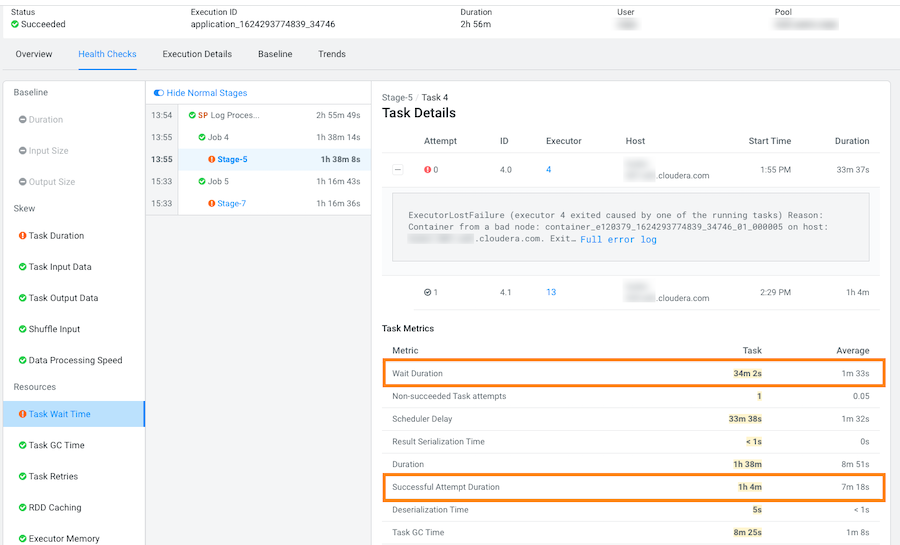
In the following example, the long wait time occurred in Stage-5 of the job process due to insufficient resources. The Recommendation section lists items for you to complete that may resolve the problem and the specific outlier tasks that produced the unusual results:
-
To display more details about why this job is experiencing longer than average
wait times, click one of the tasks listed under Outlier
Tasks.
In the following example, the Task Metrics section shows higher than average criteria measurement results and the Task Details reveal an ExecutorLostFailure error. This indicates a probable memory issue, where the container is exceeding the memory limits. In this case, more details may be found by clicking Full error log and reviewing the log: