Known Issues in Hue
Learn about the known issues in Hue, the impact or changes to the functionality, and the workaround.
Known issues in 7.2.17
- CDPD-56888: Renaming a folder with special characters results in a duplicate folder with a new name on AWS S3.
- On AWS S3, if you try to rename a folder with special characters in its name, a new folder is created as a copy of the original folder with its contents. Also, you may not be able to delete the folder containing special characters.
- CDPD-48146: Error while browsing S3 buckets or ADLS containers from the left-assist panel
- You may see the following error while trying to access the S3 buckets or ADLS containers from the left-assist panel in Hue: Failed to retrieve buckets: :1:0: syntax error.
- CDPD-54376: Clicking the home button on the File Browser page redirects to HDFS user directory
- When you are previewing a file on any supported filesystem, such as S3 or ABFS, and you click on the Home button, you are redirected to the HDFS user home directory instead of the user home directory on the said filesystem.
Technical Service Bulletins
- TSB 2023-704: File corruption when downloading files larger than 1 MB from ABFS with Hue File Browser
- An issue within the upstream Apache Hue (Hue) application results in file corruption when downloading files larger than 1MB files from Azure Blob Filesystem (ABFS) using the Hue File Browser. Only the downloaded files are affected by this issue, the source files remain intact.
- Knowledge article
- For the latest update on this issue, see the corresponding Knowledge article: TSB 2023-704: File corruption when downloading files larger than 1 MB from ABFS with Hue File Browser
- TSB 2023-703: Risk of Data Loss when using Hue S3 File Browser
- There is a risk of losing data when moving one or more files or folders in Amazon S3
storage with the Hue File Browser. When the user selects the destination folder in the
modal window the following scenarios can occur:
- If the user selects the same destination folder as the source folder, and clicks the Move button, the selected files will be permanently deleted.
- If the user selects a different destination folder from the source
folder and clicks the Move button before the User Interface
(UI) has completely loaded (the loading is indicated by a spinner), the action could
lead to the following outcomes:
- If the previously visible destination folder was the same as the source folder, the file will be permanently deleted.
- If the previously visible destination folder was different from the source folder, the file(s) will be moved to the previously visible destination folder and not to the intended destination folder.
- Knowledge article
- For the latest update on this issue, see the corresponding Knowledge article: TSB 2023-703: Risk of Data Loss when using Hue S3 File Browser
- TSB 2024-723: Hue RAZ is using logger role to Read and Upload/Delete (write) files
- When using Cloudera Data Hub for Public Cloud (Data Hub) on
Amazon Web Services (AWS), users can use the Hue File Browser feature to access the
filesystem, and if permitted, read and write directly to the related S3 buckets. As
AWS does not provide fine-grained access control, Cloudera Data Platform
administrators can use the Ranger Authorization Service (RAZ) capability to take the
S3 filesystem, and overlay it with user and group specific permissions, making it
easier to allow certain users to have limited permissions, without having to grant
those users permissions to the entire S3 bucket.
This bulletin describes an issue when using RAZ with Data Hub, and attempting to use fine-grained access control to allow certain users write permissions.
Through RAZ, an administrator may, for a particular user, specify permissions more limited than what AWS provides for an S3 bucket, allowing the user to have read/write (or other similar fine grained access) permissions on only a subset of the files and directories within that bucket. However, under specific conditions, it is possible for such user to be able to read and write to the entire S3 bucket through Hue, due to Hue using the logger role (which will have full read/write to the S3 bucket) when using Data Hub with a RAZ enabled cluster. This problem also can affect the Hue service itself, by affecting proper access to home directories causing the service role to not start.
The root cause of this issue is, when accessing Amazon cloud resources, Hue uses the AWS Boto SDK library. This AWS Boto library has a bug that restricts permissions in certain AWS regions in such a way that it provides access to users who should not have it, regardless of RAZ settings. This issue only affects users in specific AWS regions, listed below, and it does not affect all AWS customers.
- Knowledge article
-
For the latest update on this issue see the corresponding Knowledge Article: TSB 2024-723: Hue Raz is using logger role to Read and Upload/Delete (write) files.
Known issues in 7.2.16
- CDPD-54714: SSO does not work while logging in from the Hue UI
- Due to a missing configuration in Cloudera Manager, SSO does not work when you have enabled Knox as an authentication backend and when Hue is in HA mode.
- CDPD-41136: Importing files from the local workstation is disabled by default
- Cloudera has disabled the functionality to import files from your local workstation into Hue because it may cause errors. You may not see the Local File option in the Type drop-down menu on the Importer page by default.
- CDPD-42619: Unable to import a large CSV file from the local workstation
- You may see an error message while importing a CSV file into Hue from your workstation, stating that you cannot import files of size more than 200 KB.
- CDPD-43293: Unable to import Impala table using Importer
- Creating Impala tables using the Hue Importer may fail.
Known issues before 7.2.16
- CDPD-58978: Batch query execution using Hue fails with Kerberos error
- When you run Impala queries in a batch mode, you enounter failures with a Kerberos error even if the keytab is configured correctly. This is because submitting Impala, Sqoop, Pig, or pyspark queries in a batch mode launches a shell script Oozie job from Hue and this is not supported on a secure cluster.
- Hue Importer is not supported in the Data Engineering template
- When you create a Data Hub cluster using the Data Engineering
template, the Importer application is not supported in Hue.
Figure 1. Hue web UI showing Importer icon on the left assist panel 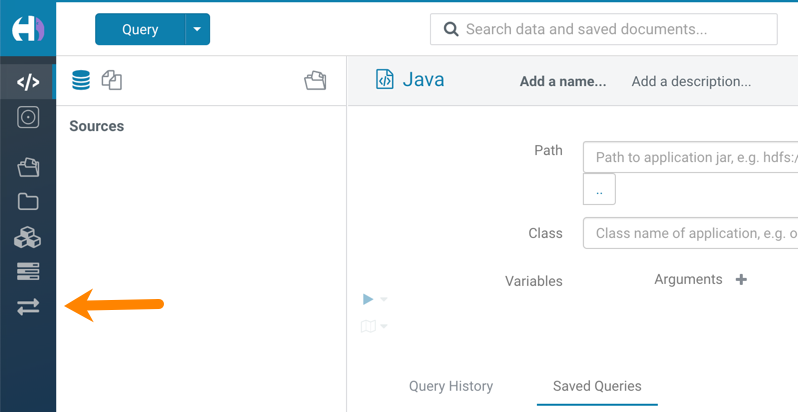
Unsupported features
- CDPD-59595: Spark SQL does not work with all Livy servers that are configured for High Availability
- SparkSQL support in Hue with Livy servers in HA mode is not
supported. Hue does not automatically connect to one of the Livy servers. You must
specify the Livy server in the Hue Advanced Configuration Snippet as
follows:
Moreover, you may see the following error in Hue when you submit a SparkSQL query: Expecting value: line 2 column 1 (char 1). This happens when the Livy server does not respond to the request from Hue.[desktop] [spark] livy_server_url=http(s)://[***LIVY-FOR-SPARK3-SERVER-HOST***]:[***LIVY-FOR-SPARK3-SERVER-PORT***] - Importing and exporting Oozie workflows across clusters and between different CDH versions is not supported
-
You can export Oozie workflows, schedules, and bundles from Hue and import them only within the same cluster if the cluster is unchanged. You can migrate bundle and coordinator jobs with their workflows only if their arguments have not changed between the old and the new cluster. For example, hostnames, NameNode, Resource Manager names, YARN queue names, and all the other parameters defined in the
workflow.xmlandjob.propertiesfiles.Using the import-export feature to migrate data between clusters is not recommended. To migrate data between different versions of CDH, for example, from CDH 5 to CDP 7, you must take the dump of the Hue database on the old cluster, restore it on the new cluster, and set up the database in the new environment. Also, the authentication method on the old and the new cluster should be the same because the Oozie workflows are tied to a user ID, and the exact user ID needs to be present in the new environment so that when a user logs into Hue, they can access their respective workflows.
- INSIGHT-3707: Query history displays "Result Expired" message
- You see the "Result Expired" message under the Query History column on the Queries tab for queries which were run back to back. This is a known behaviour.