Using the Spark shell
Using Spark, you can create an Iceberg table followed by schema evolution, partition specification, and partition evolution.
Run the following command in your Spark shell to create a new Iceberg table
-
Navigate accordingly in the Atlas UI to view the changes.
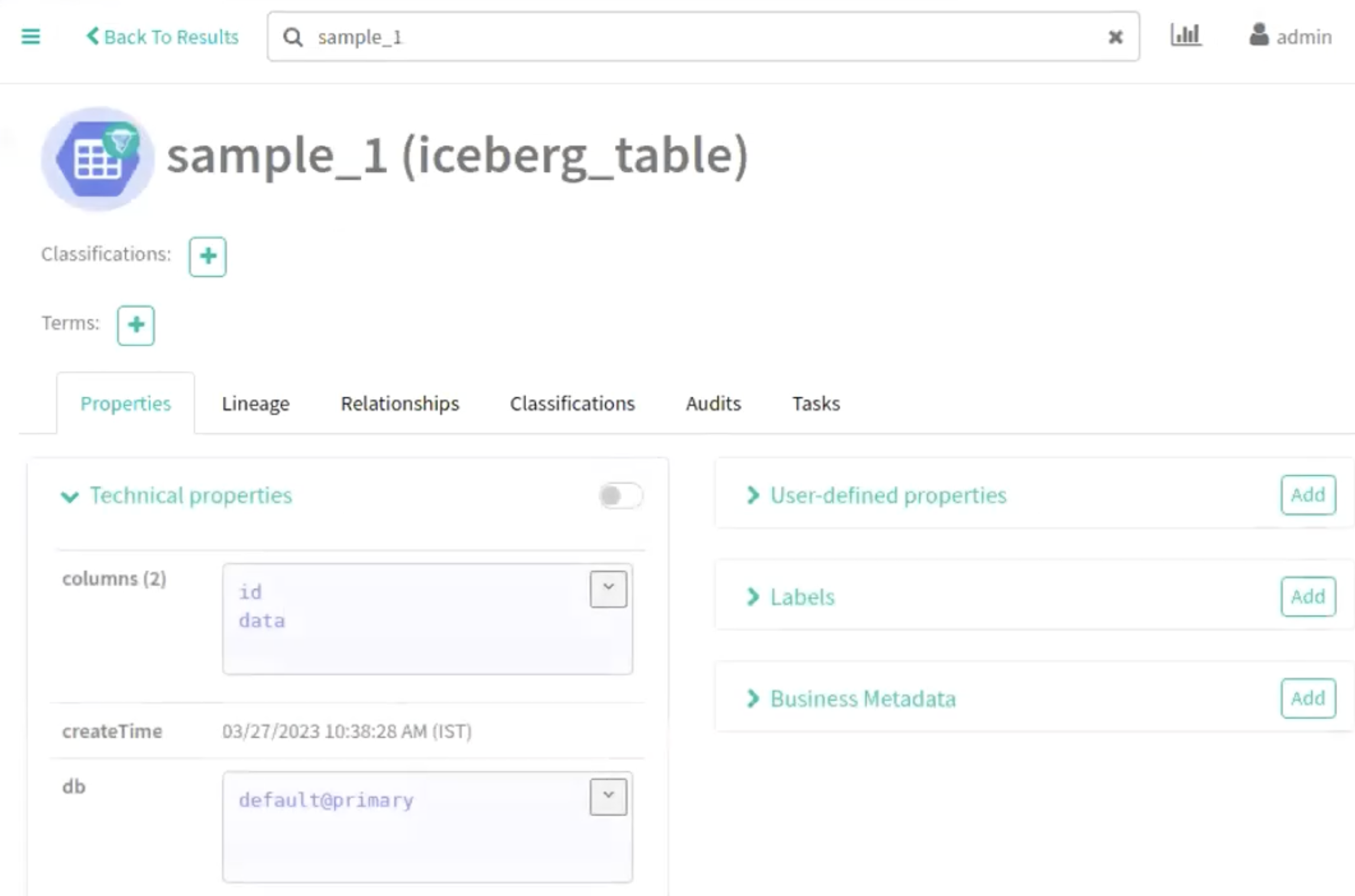
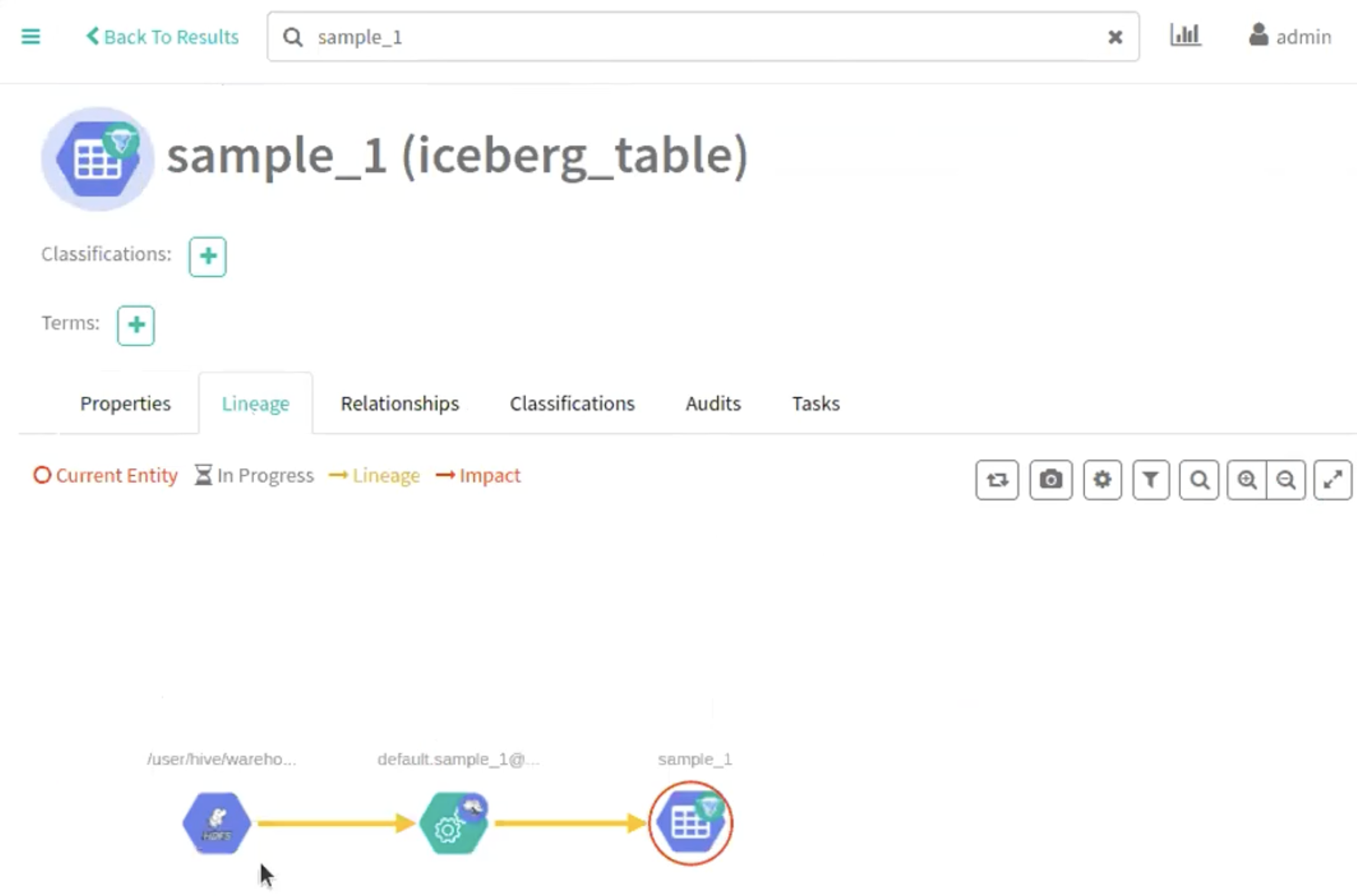
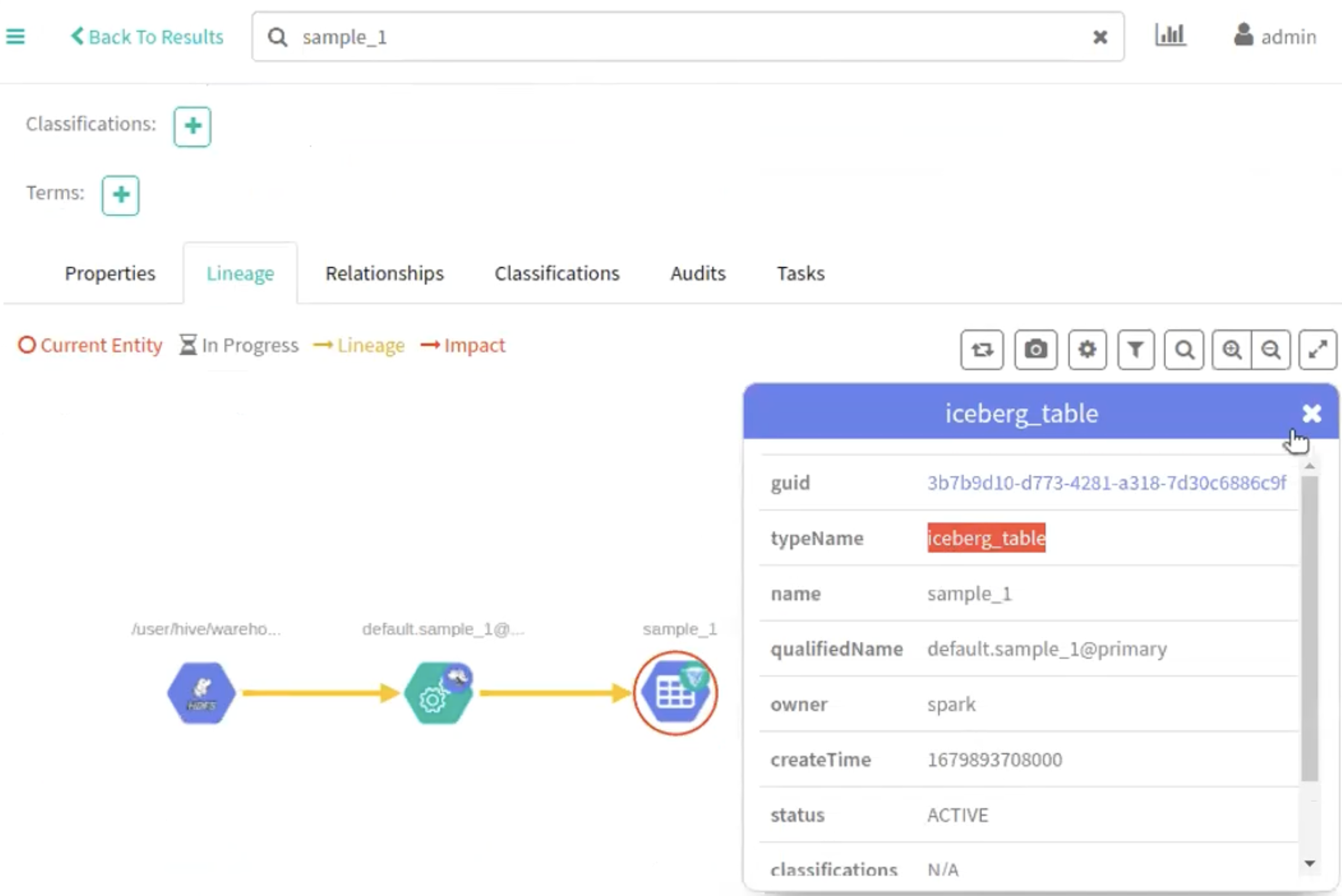
The following images provide information about Iceberg table creation process.
Run the following command in your Spark shell to create a Schema Evolution in a new table. For example - sample_2.
-
Navigate accordingly in the Atlas UI to view the changes.
The following image provide information about Iceberg schema evolution process.
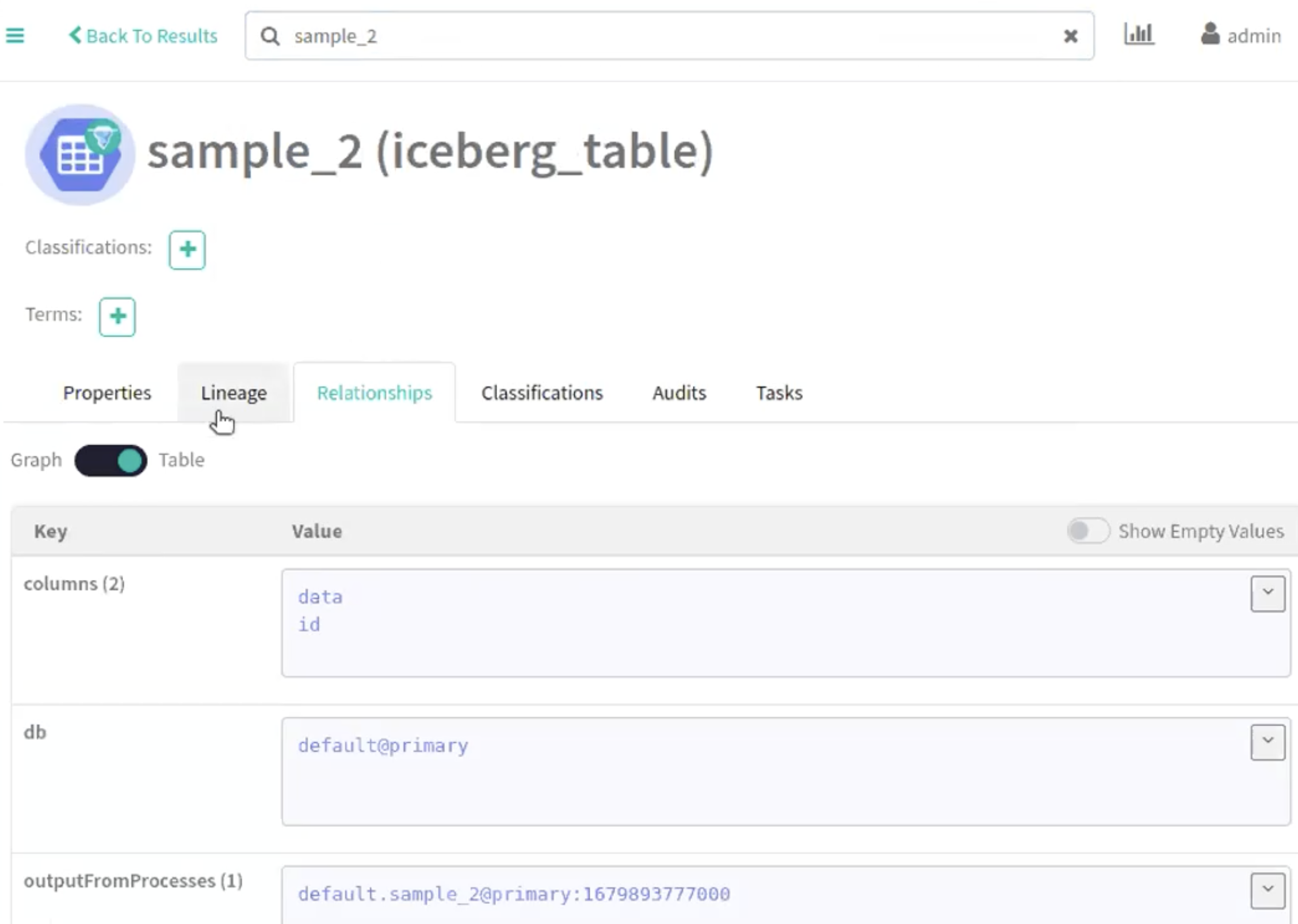
Run the following command in your Spark shell to include a column:
-
Navigate accordingly in the Atlas UI to view the changes.
The following images provide information about Iceberg schema creation process.
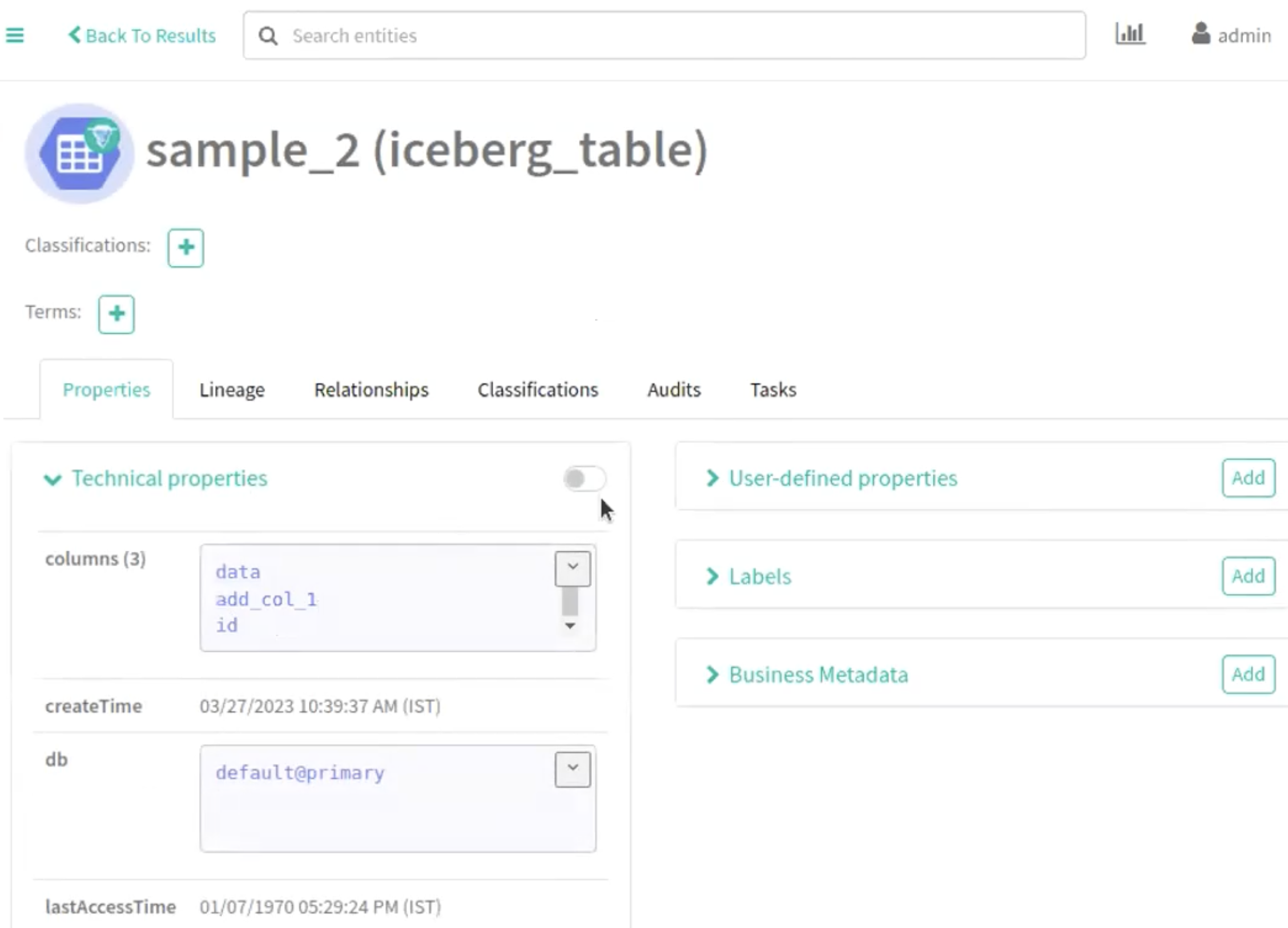
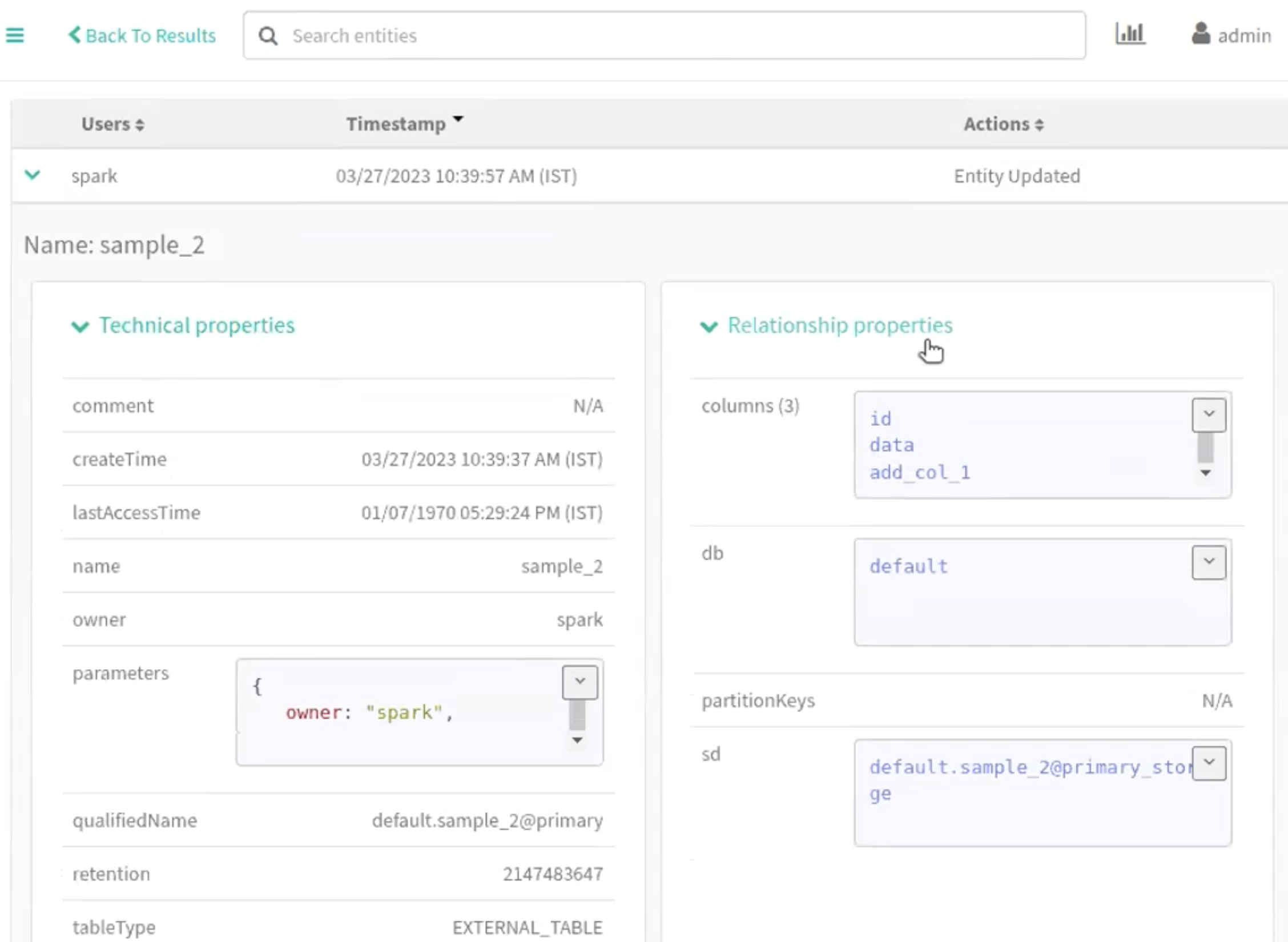
Run the following command in your Spark shell to include the second column:
-
Navigate accordingly in the Atlas UI to view the changes.
The following image provide information about Iceberg schema creation process.
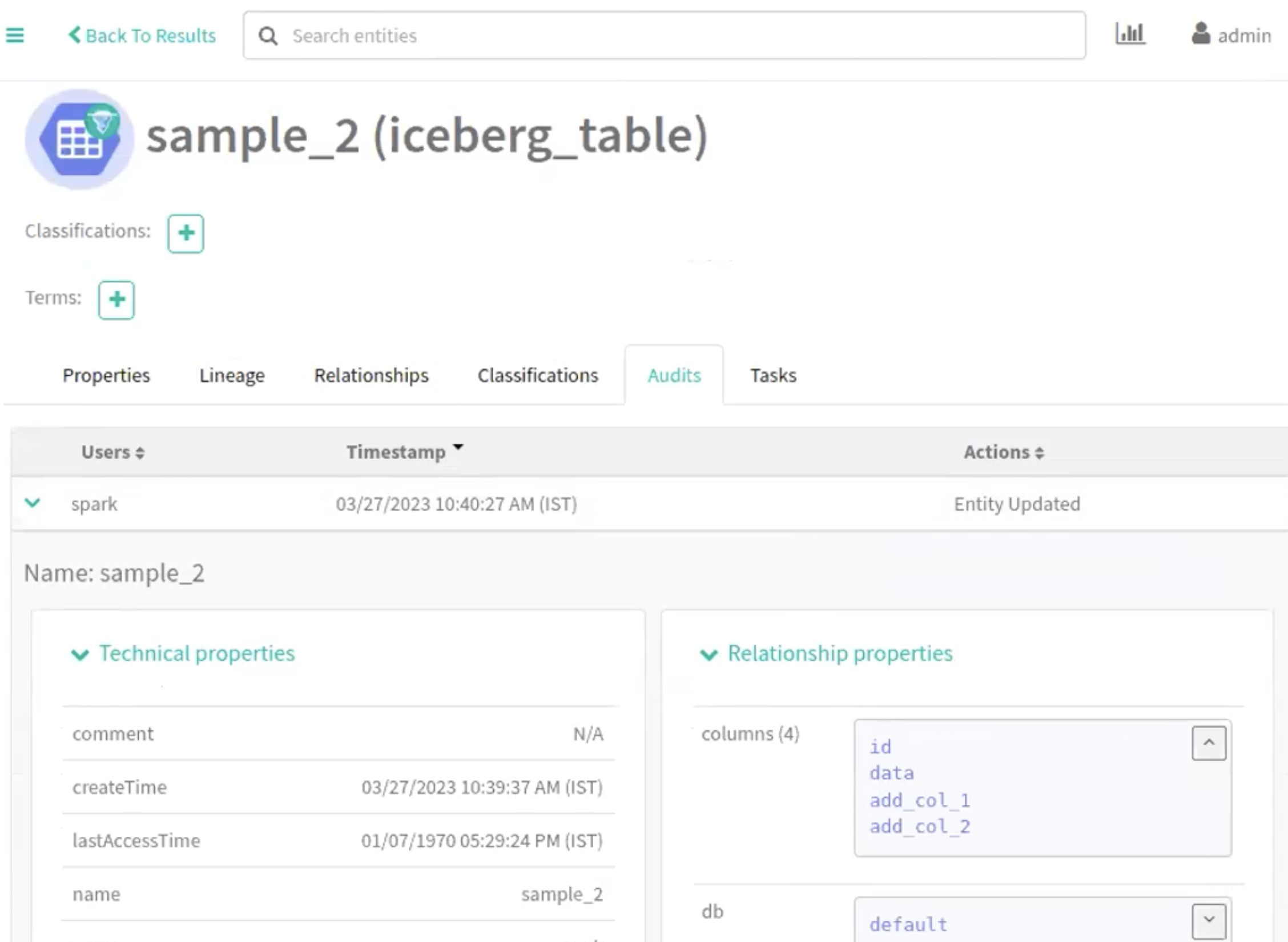
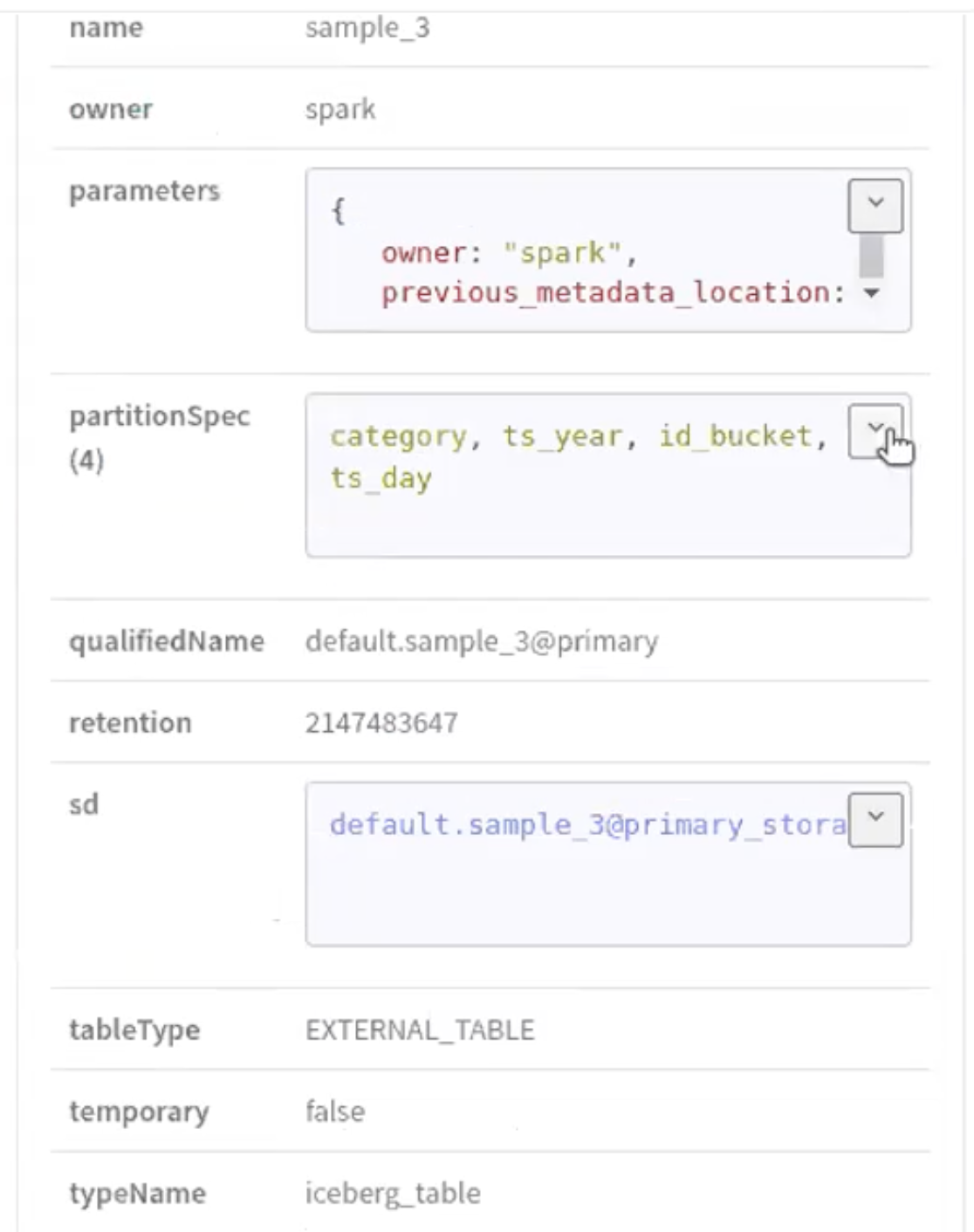
Run the following command in your Spark shell to create a Partition Specification in a new table (sample_3):
-
Navigate accordingly in the Atlas UI to view the changes.
The following images provide information about Iceberg partition specification process.
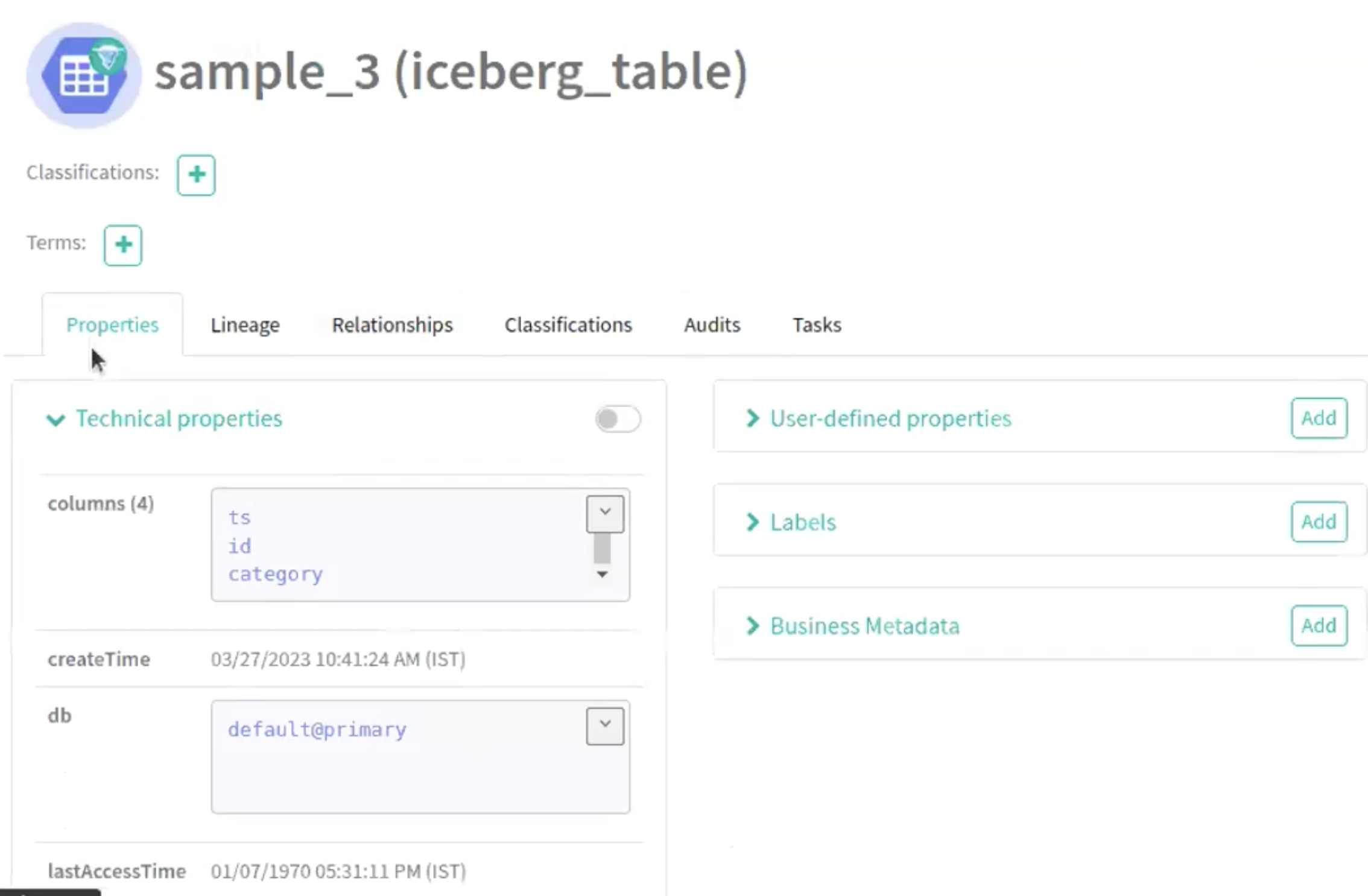
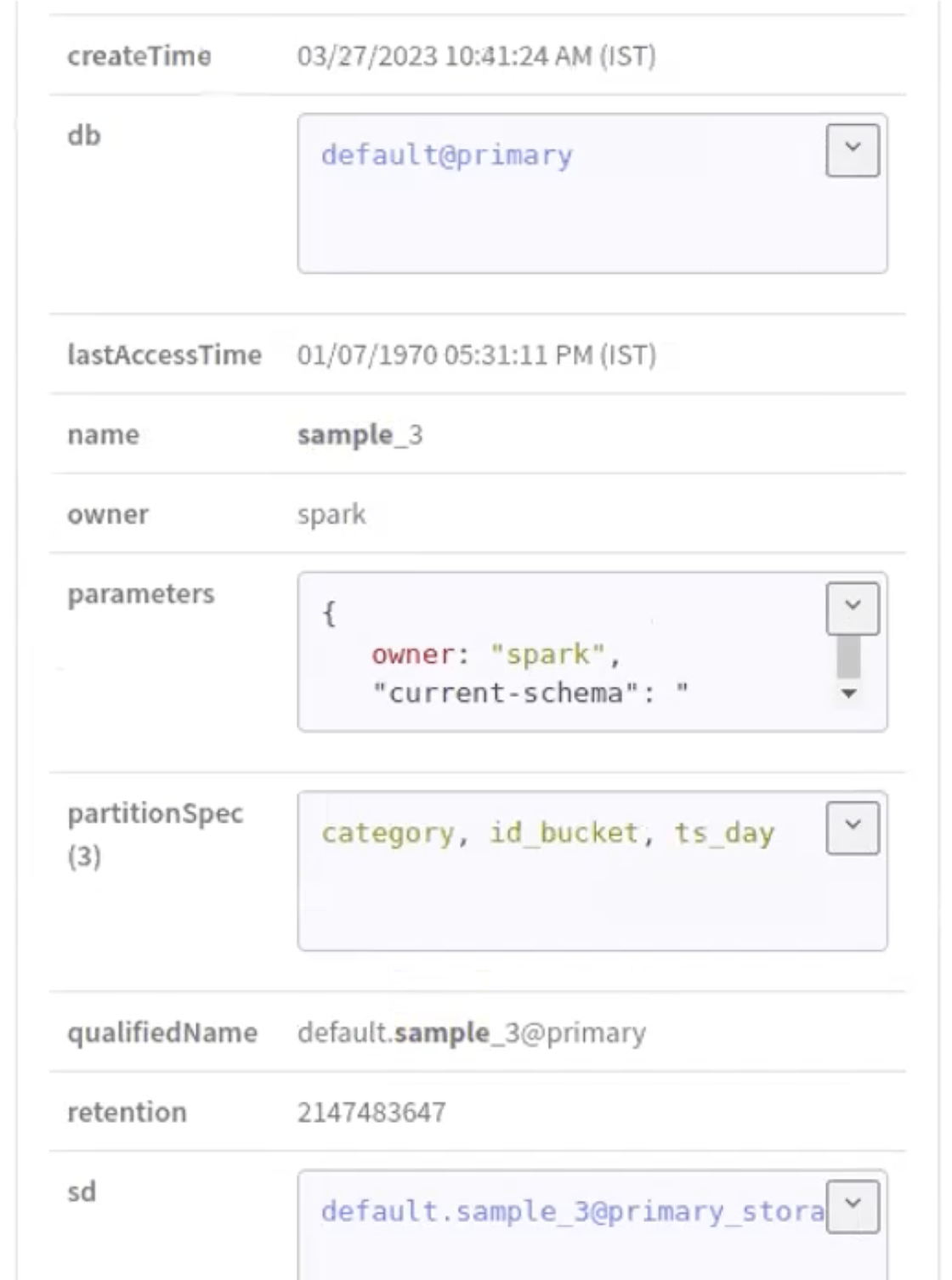
-
Navigate accordingly in the Atlas UI to view the changes.
The following images provide information about Iceberg partition evolution process.