End-to-End Example: MeCab
This section demonstrates how to customize the Cloudera Data Science Workbench base engine image to include the MeCab (a Japanese text tokenizer) library.
# Dockerfile
FROM docker.repository.cloudera.com/cdsw/engine:8
RUN rm /etc/apt/sources.list.d/*
RUN apt-get update && \
apt-get install -y -q mecab \
libmecab-dev \
mecab-ipadic-utf8 && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
RUN cd /tmp && \
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git && \
/tmp/mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -y -n -p /var/lib/mecab/dic/neologd && \
rm -rf /tmp/mecab-ipadic-neologd
RUN pip install --upgrade pip
RUN pip install mecab-python==0.996To use this image on your Cloudera Data Science Workbench project, perform the following steps.
-
Whitelist the image,
<your-company-registry>/user/cdsw-mecab:latest. Only a site administrator can do this.Go to and add<company-registry>/user/cdsw-mecab:latestto the list of whitelisted engine images.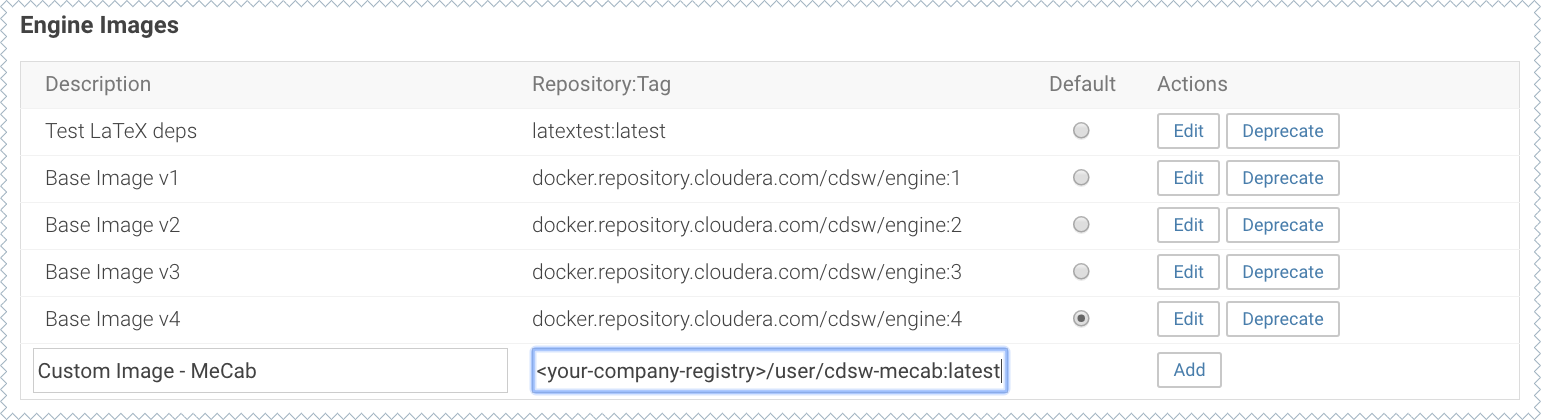
-
Ask a project administrator to set the new image as the default for your project.
Go to the project Settings, click Engines, and select
company-registry/user/cdsw-mecab:latestfrom the dropdown.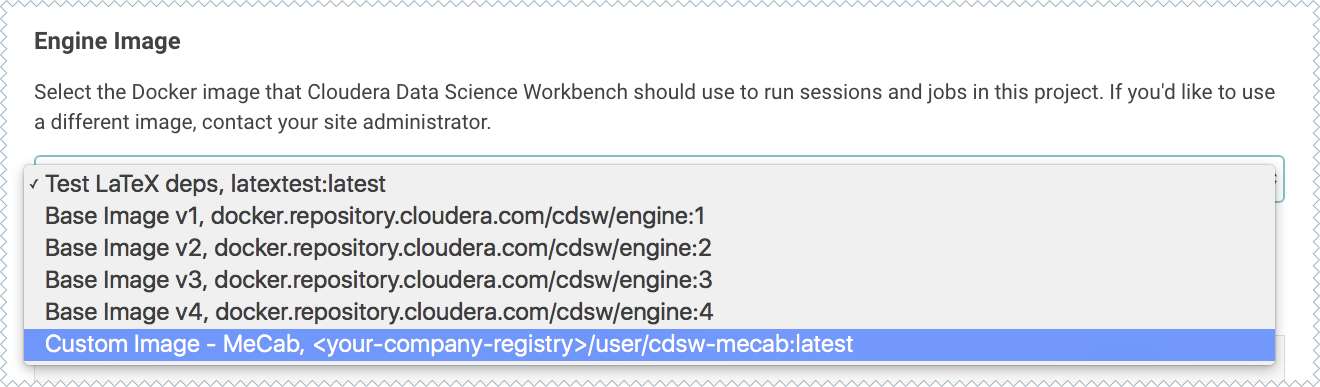
You should now be able to run this project on the customized MeCab engine.