
Using Zeppelin Interpreters
This section describes how to use Apache Zeppelin interpreters.
Before using an interpreter, ensure that the interpreter is available for use in your note:
- Navigate to your note.
- Click on “interpreter binding”:
- Under "Settings", make sure that the interpreter you want to use is selected (in
blue text). Unselected interpreters appear in white text:
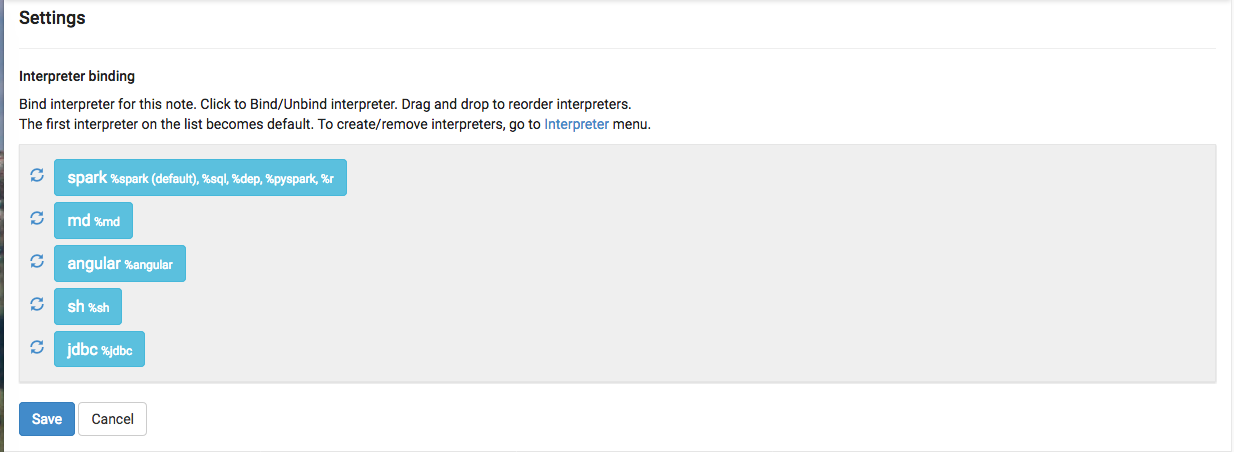
- To select an interpreter, click on the interpreter name to select the interpreter. Each click operates as a toggle.
- You should unselect interpreters that will not be used. This makes your choices
clearer. For example, if you plan to use
%livyto access Spark, unselect the%sparkinterpreter.
Whenever one or more interpreters could be used to access the same underlying service, you can specify the precedence of interpreters within a note:
-
Drag and drop interpreters into the desired positions in the list.
-
When finished, click "Save".
Use an interpreter in a paragraph
To use an interpreter, specify the interpreter directive at the beginning of a
paragraph, using the format %[INTERPRETER_NAME]. The directive must
appear before any code that uses the interpreter.
The following paragraph uses the %sh interpreter to access the system
shell and list the current working directory:
%sh pwd home/zeppelin
Some interpreters support more than one form of the directive. For example, the
%livy interpreter supports directives for PySpark, PySpark3, SparkR,
Spark SQL.
To view interpreter directives and settings, navigate to the Interpreter page and scroll through the list of interpreters or search for the interpreter name. Directives are listed immediately after the name of the interpreter, followed by options and property settings. For example, the JDBC interpreter supports the %jdbc directive:

Note: The Interpreter page is subject to access control settings. If the Interpreters page does not list settings, check with your system administrator for more information.
Use interpreter groups
Each interpreter belongs to an interpreter group. Interpreters in the same group can reference each other. For example, if the Spark SQL interpreter and the Spark interpreter are in the same group, the Spark SQL interpreter can reference the Spark interpreter to access its SparkContext.
