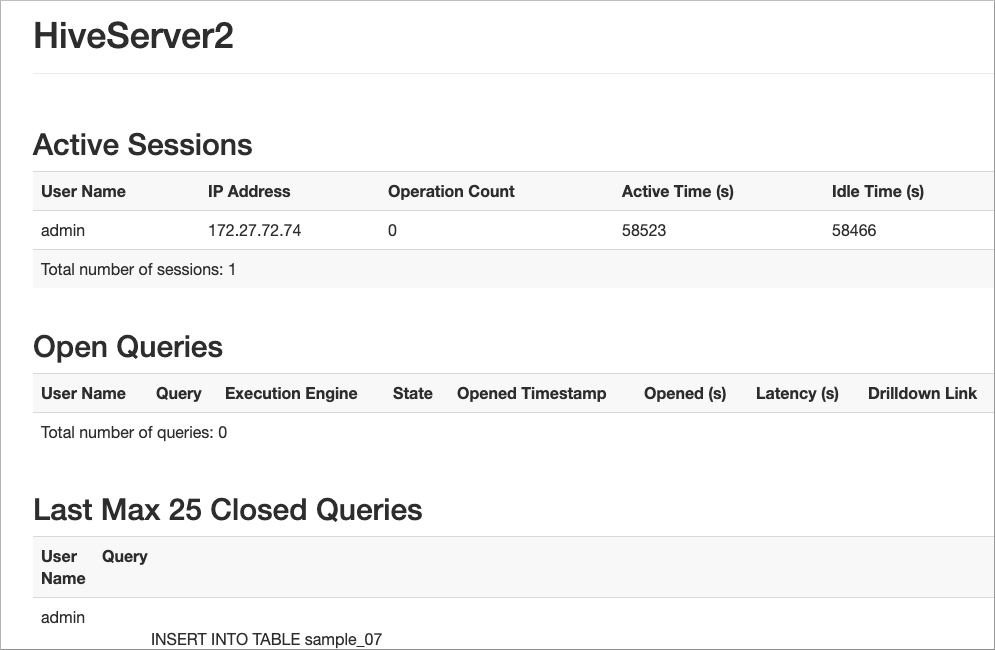
Tracking Hive on Tez query execution
You need to know how to monitor Hive on Tez queries during execution. Several tools provide query details, such as execution time.
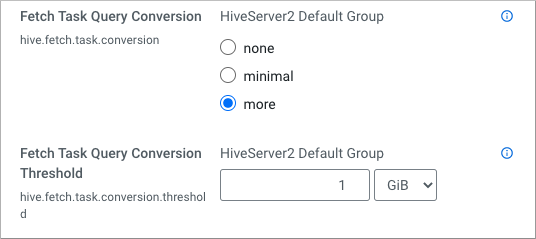
- hive.fetch.task.conversion
- Value:
minimal
- hive.fetch.task.conversion.threshold
- Value:
1 GiB
Increasing the static pool does not speed reads and there is not recommended.
-
Accept, or change, the default values of the fetch task properties.
-
Navigate to the HiveServer log directory and look at the log files.
In Cloudera Manager, you can find the location of this directory as the value of HiveServer2 Log Directory.

-
In Cloudera Manager, click , and click to the HiveServer Web UI.