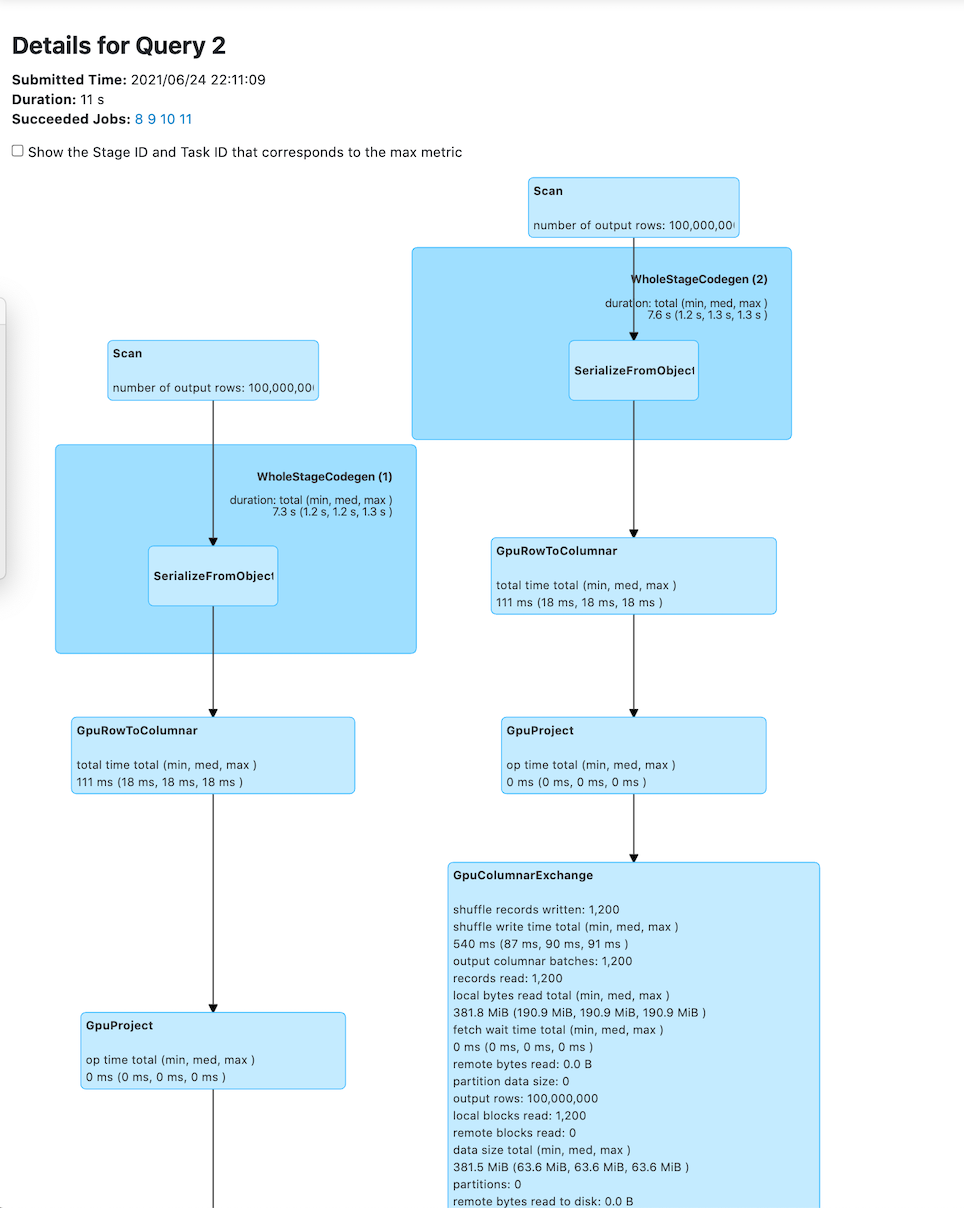
The Spark 3 job commands
With Spark 3, you use slightly different command names than with Spark 2, so that you can run both versions of Spark side-by-side without conflicts:
spark3-submitinstead ofspark-submit.spark3-shellinstead ofspark-shell.pyspark3instead ofpyspark.
For development and test purposes, you can also configure an alias on each host so that invoking the Spark 2 command name runs the corresponding Spark 3 executable.