
Partitions
Learn more about Kafka partitions.
Instead of all records handled by the system being stored in a single log, Kafka divides records into partitions. Partitions can be thought of as a subset of all the records for a topic. Partitions help with the ideal of “Unlimited Scaling”.
Records in the same partition are stored in order of arrival.
When a topic is created, it is configured with two properties:
- partition count
- The number of partitions that records for this topic will be spread among.
- replication factor
- The number of copies of a partition that are maintained to ensure consumers always have access to the queue of records for a given topic.
Each topic has one leader partition. If the replication factor is greater than one, there will be additional follower partitions. (For the replication factor = M, there will be M-1 follower partitions.)
Any Kafka client (a producer or consumer) communicates only with the leader partition for data. All other partitions exist for redundancy and failover. Follower partitions are responsible for copying new records from their leader partitions. Ideally, the follower partitions have an exact copy of the contents of the leader. Such partitions are called in-sync replicas (ISR).
With N brokers and topic replication factor M, then
- If M < N, each broker will have a subset of all the partitions
- If M = N, each broker will have a complete copy of the partitions
In the following illustration, there are N = 2 brokers and M = 2 replication factor. Each producer may generate records that are assigned across multiple partitions.
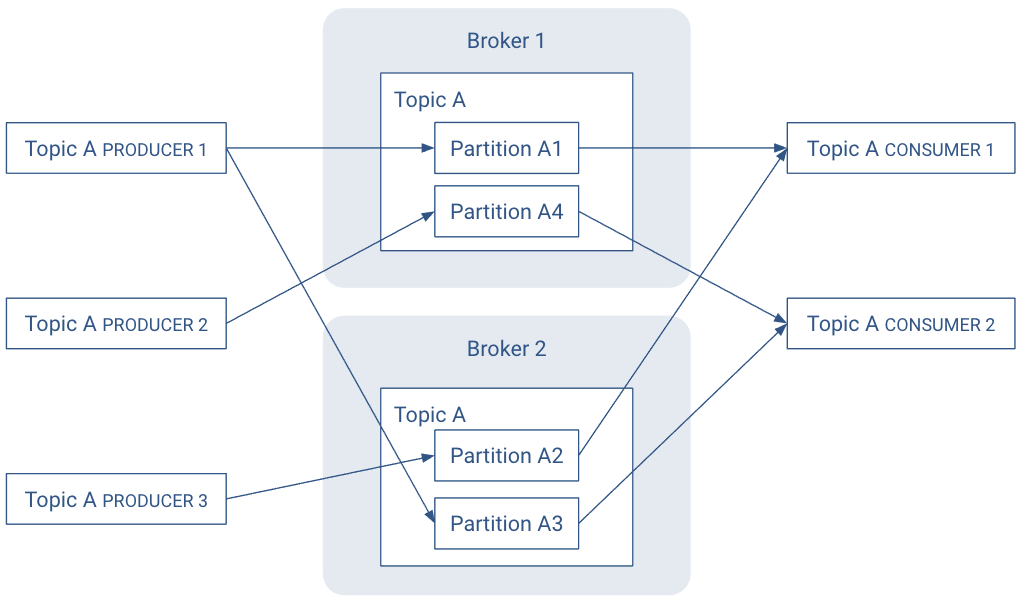
Partitions are the key to keeping good record throughput. Choosing the correct number of partitions and partition replications for a topic:
- Spreads leader partitions evenly on brokers throughout the cluster
- Makes partitions within the same topic are roughly the same size
- Balances the load on brokers.
