Performing manual repair
Manual repair should be performed on a cluster that has nodes marked as unhealthy.
Required role: The DataHubAdmin or Owner roles at the scope of Cloudera Data Hub allow you to manage the Cloudera Data Hub cluster. Note that EnvironmentAdmin and Owner of the environment can also manage Cloudera Data Hub clusters.
When a cluster has unhealthy nodes, a warning is displayed:
- Cluster tile on the cluster dashboard shows unhealthy nodes
- Nodes are marked as "UNHEALTHY" in the Hardware section
- Cluster's event history shows "Manual recovery is needed for the following failed nodes"
There are two ways to repair the failed nodes:
- Repair the failed nodes: (1) All non-ephemeral disks are detached from the failed nodes. (2) Failed nodes are removed (3) New nodes of the same type are provisioned. (4) The disks are attached to the new volumes, preserving the data.
- Delete the failed nodes: Failed nodes are deleted with their attached volumes.
If a node is marked as deleted from the cloud provider side, you must perform manual repair before restarting the cluster. If you do not perform the manual repair, the cluster will not restart.
You can perform manual repair from the Cloudera web interface or CLI.
To perform manual repair from Cloudera web interface:
- Log in to the Cloudera web interface.
- Navigate to Cloudera Management Console > Data Hub Clusters.
- Browse to the cluster details.
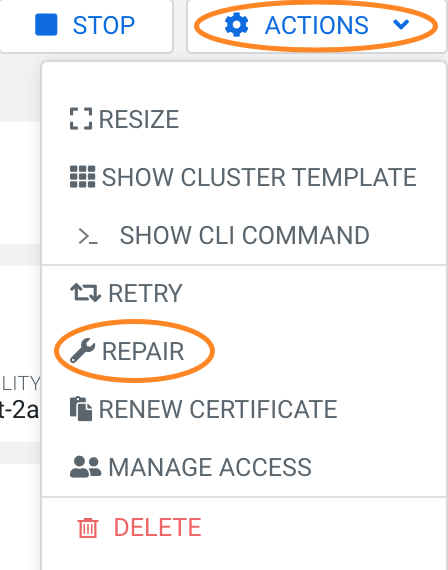
- Choose one of the following options:
- To repair all of the failed nodes in a particular host group, select Actions >
Repair and then select the host group to repair. Only one host group can be
selected at a time:
- To repair a single node failure or select certain nodes within a host group to
repair, select the Hardware tab and then the repair icon next
to the host group that contains the failed node(s). Alternatively you can use the CDP
CLI:
cdp datahub repair-cluster help - When you initiate a repair from the Hardware tab, you also have the option to delete any volumes attached to the instance. This can be useful if a volume is lost on the cloud provider side. To delete the attached volumes, select the Delete Volumes checkbox.
- To repair all of the failed nodes in a particular host group, select Actions >
Repair and then select the host group to repair. Only one host group can be
selected at a time:
- By default, unhealthy nodes are removed and then replaced. If you would like to just remove the nodes without replacing them, select Remove only.
- Click Repair.
- Once the recovery flow is completed, the cluster status changes to 'RUNNING'.