Backing up before an upgrade
The Cloudera Data Hub cluster upgrade is an in-place upgrade and the data on attached volumes will be retained. The following section outlines data stored in the Cloudera Data Hub clusters by different services. To prepare for a worst-case scenario where the cluster can't be restored, retain the data in these clusters. Also take note of any cluster configurations updated through Cloudera Manager.
Service configurations in Cloudera Manager
- Any service configurations that you have updated since the cluster creation. Typically these can be found by selecting the “Non-default values” filter on the Configuration menu in Cloudera Manager.
Custom drivers
Take a backup of any custom drivers for services running on Cloudera Data Hub. An OS upgrade will delete the root volume and you will not be able to recover the driver if a backup is not taken.
Data Engineering clusters
The underlying data is in cloud storage. However, the following data is specific to each Cloudera Data Hub cluster:
- Oozie - workflow and coordinator definitions
- Hue - saved queries
- Hive UDFs and Spark applications
- Oozie custom sharelibs
A script is available for backing up and restoring the Oozie and Hue databases in clusters created with the Data Engineering and Data Engineering HA templates. Execute the commands from the Cloudera Manager node. Run the following:
sudo su
chmod +x /srv/salt/postgresql/disaster_recovery/scripts/backup_and_restore_dh.shThen, for backup run:
/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -b <s3 or abfs path> <database names>For example:
/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -b s3a://my/test/path oozie hue/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -r <s3 or abfs path> <database names>For example:
/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -r s3a://my/test/path oozie hueStreams Messaging clusters
Backing up and restoring data
Data stored on volumes:
- Zookeeper: /hadoopfs/fs1/zookeeper (only on the first attached volume)
- Kafka: /hadoopfs/fsN/kafka (for on all attached volumes, N stands for volume index)
Data stored in database:
- Schema Registry schemas
Data stored in S3/ADLS:
- Schema Registry serde jars
A script is available for backing up and restoring the Schema_registry and SMM databases in clusters created with the Streams Messaging Light Duty and Streams Messaging Heavy Duty templates. Run the following:
sudo su
chmod +x /srv/salt/postgresql/disaster_recovery/scripts/backup_and_restore_dh.shThen, for backup run:
/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -b <s3 or abfs path> <database names>For example:
/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -b s3a://my/test/path smm schema_registry/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -r <s3 or abfs path> <database names>For example:
/srv/salt/postgresql/disaster_recovery/scripts/backup_and_resto
re_dh.sh -r s3a://my/test/path smm schema_registryBacking up and restoring Kafka Connect secret password and salt
On a Streams Messaging Cloudera Data Hub cluster, you need to manually reset the Kafka Connect secret password and salt in Cloudera Manager and save them for later so that you can manually reset them again when you need to recreate the cluster from scratch. Otherwise, Kafka Connect can go into a bad health state. The only way for you to know this password and salt is to reset them and manually record them somewhere.
Set new password and salt values in Cloudera Manager for the below values and Restart Kafka Connect to ensure the new password and salt is used for encryption:
- kafka.connect.secret.global.password
- kafka.connect.secret.pbe.salt
Save the password and salt for later use because you will need them if you need to recreate the cluster.
Resetting Kafka Connect secret password when recreating a cluster from backup
After recreating a Cloudera Data Hub cluster, you need to manually reset the Kafka Connect password and salt values to the values used on the original cluster.
- Restart Kafka Connect after the Cloudera Data Hub cluster is recreated.
- Set the following password and salt values to the ones that you have saved earlier for
the original cluster:
- kafka.connect.secret.global.password
- kafka.connect.secret.pbe.salt
- Restart Kafka Connect again.
Flow Management clusters
Verify that you have committed all of your flows, then backup the following files/directories into your S3 backup location:
-
nifi.properties - on any NiFi node, run:
ps -ef | grep nifi.propertiesThis will indicate the path to the file. For example:
-Dnifi.properties.file.path=/var/run/cloudera-scm-agent/process/1546335400-nifi-NIFI_NODE/nifi.properties -
bootstrap.conf - on any NiFi node, run:
ps -ef | grep bootstrap.confThis will indicate the path to the file. For example:
-Dorg.apache.nifi.bootstrap.config.file=/var/run/cloudera-scm-agent/process/1546335400-nifi-NIFI_NODE/bootstrap.conf -
Zookeeper data for /nifi znode. From a NiFi node:
/opt/cloudera/parcels/CFM-<CFMversion>/TOOLKIT/bin/zk-migrator.sh -r -z <zk node>:2181/nifi -f /tmp/zk-data.jsonIf a Zookeeper node is co-located with NiFi (light duty template, it’s possible to use localhost:2181), then back up the created
zk-data.jsonfile. -
NiFi Registry data. The versioned flows are stored in an external database provisioned in your cloud provider. Perform a backup of this database following the instructions of your cloud provider and restore the backup in the new database.
- /hadoopfs/fs4/working-dir/ (for the NiFi nodes) - without the
‘work’ directory inside it. This directory contains, for example, the local state
directory as well as the
flow.xml.gzwhich represents the flow definitions. - /hadoop/fs1/working-dir/ (for the Management node).
- Any other “custom” directory, for example directories where client configs and JDBC driver are located.
Data Discovery & Exploration clusters
Complete the following steps to backup DDE clusters:
- Assign the datalake-admin-bucket policy to RANGER_AUDIT_ROLE.
- Create a subfolder for this Cloudera Data Hub cluster inside your S3 backup location.
- Log in to the gateway node of the Cloudera Data Hub cluster.
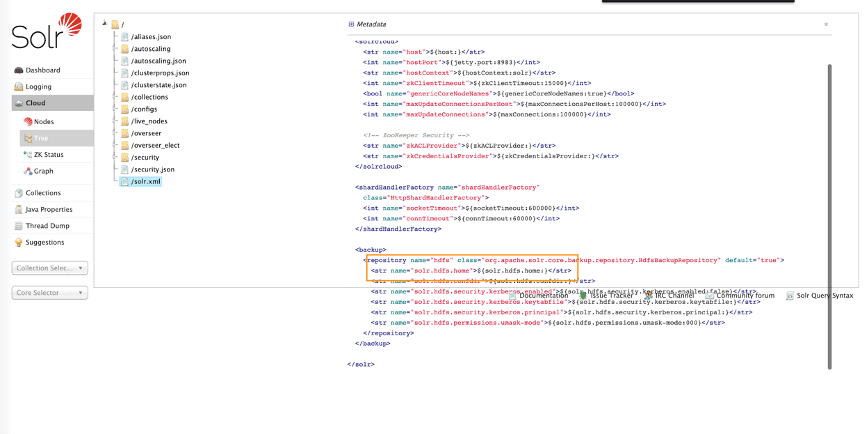
kinitwith the proper user keytab if needed.- Follow this Backing Up and Restoring Solr Collections with these exceptions:
-
Use
solrctl --get-solrxmlto get thesolr.xmlfile.Edit it by changing your backup repository
solr.hdfs.homeparameter (see image) to your backup location (for example:s3a://datalake-bucket/backup/solr).User
solrctl --put-solrxmlto publish your edited solr.xml.Restart Solr.
- You do not need to launch the
prepare-backupcommand; instead launchcreate-snapshotandexport-snapshotfor each collection. - For
export-snapshot, specify your destination ass3a://[your backup location]/[your data hub subfolder] (for example:s3a://datalake-bucket/backup/solr). - Verify on the YARN history server that all of the executions succeeded. If not,
troubleshoot and relaunch any
export-snapshotcommands that failed.
-
Operational Database clusters
Complete the following steps to backup Operational Database clusters:
- Create a subfolder for this Cloudera Data Hub cluster inside of your S3 backup location.
- Ensure snapshots are enabled on Cloudera Manager. They are enabled by default.
- Log in to the gateway node of the Cloudera Data Hub cluster.
kinitwith the proper user keytab if needed.- Launch
hbase shell. - Issue the
snapshotcommand for each of the tables that you want to back up (for example: snapshot ‘mytable’, ‘mytable-snapshot’) - Exit
hbase shell. - Launch
ExportSnapshotcommand for each of the snapshots you created, for example:hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot mytable-snapshot -copy-to s3a://datalake-bucket/backup/hbase -mappers 10 - Verify on the YARN history server that all of the executions succeeded. If not,
troubleshoot and relaunch any
ExportSnapshotcommands that failed.