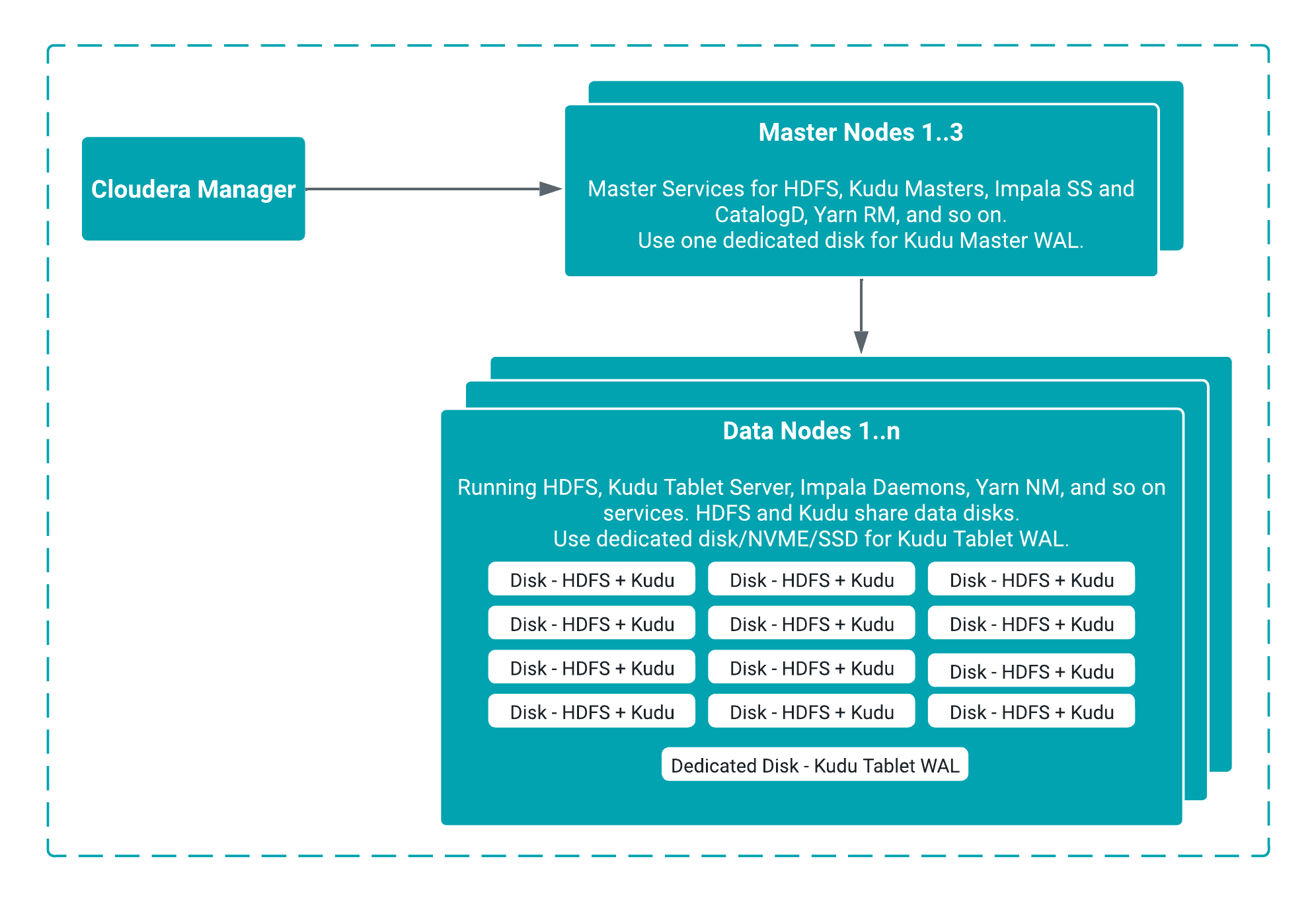
Kudu architecture in a Cloudera Base on premises
deployment
In a Cloudera Base on premises deployment, Kudu is available
as one of the Cloudera services. To use Kudu, install Kudu in
your cluster along with other services such as Spark and Impala, and optional dependencies, such
as HDFS or ZooKeeper.
The following diagram shows a typical Cloudera Base on premises
cluster deployed on Bare Metal. The base cluster is managed through Cloudera Manager. Kudu shares master and data nodes on the base cluster with
Kudu Master Services running on master nodes and Kudu Tablet Service running on data nodes.
The following diagram explains the logical setup of Kudu service:
Recommendations for using Kudu in a Cloudera Base on premises
deployment:
Master nodes
Use two separate disks; one for Kudu Master Data and another for Kudu Master
WAL.
If workloads are SLA driven, then consider using NVME/SSD for Kudu Master WAL
disk.
Data Nodes
Share disks between Kudu Tablet service and HDFS service. An example setup is as
follows:
Disk 01
/data01/hdfs-data/
/data01/kudu-data/
Disk 02
/data02/hdfs-data/
/data02/kudu-data/
For Kudu Tablet WAL, a dedicated disk is always recommended.
If workloads are SLA driven, then consider using NVME/SSD for Kudu Tablet WAL
disk.
Use the recommendations provided in the Hardware Requirements section while deploying a
compute cluster with Kudu.