How To Configure Authentication for Amazon S3
There are several ways to integrate Amazon S3 storage with Cloudera clusters, depending on your use case and other factors, including whether the cluster has been deployed using Amazon EC2 instances and if those instances were deployed using an IAM role, such as might be the case for clusters that have a single-user or small-team with comparable privileges.
Clusters deployed to support many different users with various privilege levels to the Amazon S3 need to use AWS Credentials and have privileges to target data set up in Ranger.
Authentication through the S3 Connector Service
With Cloudera Manager and CDH 5.10+ clusters, the S3 Connector Service automates the authentication process to Amazon S3 for Impala, Hive, and Hue, the components used for business-analytical use cases designed to run on persistent multi-tenant clusters.
- Kerberos for authentication, and
- Ranger for role-based authorization.
The S3 Connector Service setup wizard is launched automatically in Cloudera Manager during the AWS Credential setup process when you select the path to add the S3 Connector Service.
See Configuring the Amazon S3
Connector
for more information about the S3 Connector Service.
Authentication through Advanced Configuration Snippets
core-site.xml configuration file (through Cloudera Manager's Advanced Configuration
Snippet mechanism). This approach is not recommended. AWS credentials provide read and write
access to data stored on Amazon S3, so they should be kept secure at all times. - Never share the credentials with other cluster users or services.
- Do not store in cleartext in any configuration files. When possible, use Hadoop's credential provider to encrypt and store credentials in the local JCEK (Java Cryptography Extension Keystore).
- Enable Cloudera sensitive data redaction to ensure that passwords and other sensitive information does not appear in log files.
To enable Cloudera services to access Amazon S3, AWS credentials can be
specified using the fs.s3a.access.key and
fs.s3a.secret.key properties:
<property>
<name>fs.s3a.access.key</name>
<value>your_access_key</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>your_secret_key</value>
</property>The process of adding AWS credentials is generally the same as that detailed in
Configuring server-side encryption for Amazon S3
, that is, using the Cloudera Manager Admin Console
to add the properties and values to the core-site.xml configuration file
(Advanced Configuration Snippet). However, Cloudera strongly
discourages this approach: in general, adding AWS credentials to the
core-site.xml is not recommended. A somewhat more secure approach is to
use temporary credentials, which include a session token that limits the viability of the
credentials to a shorter time-frame within which a key can be stolen and used.
Using Temporary Credentials for Amazon S3
The AWS Security Token Service (STS) issues temporary credentials to access AWS
services such as Amazon S3. These temporary credentials include an access key, a secret
key, and a session token that expires within a configurable amount of time. Temporary
credentials are not currently handled transparently by Cloudera, so administrators must obtain
them directly from Amazon STS. For details, see Temporary Security
Credentials
in the AWS Identity and Access Management
Guide
.
-Dfs.s3a.access.key=your_temp_access_key
-Dfs.s3a.secret.key=your_temp_secret_key
-Dfs.s3a.session.token=your_session_token_from_AmazonSTS
-Dfs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProviderCreating a Table in a Bucket
To create a table in a bucket, a user must have Ranger permissions on the S3 database and bucket URI. Cloudera recommends that you create a database specifically for the purpose of creating tables. Then, you must grant the user's role one of the following options:
- CREATE on the server and ALL on the URI
- CREATE on the database and ALL on the URI
To allow a user to create tables in a bucket, complete the following steps:
- Create a database where you want to create the tables.
- Grant CREATE on the database to the user's role, as shown in the following example:
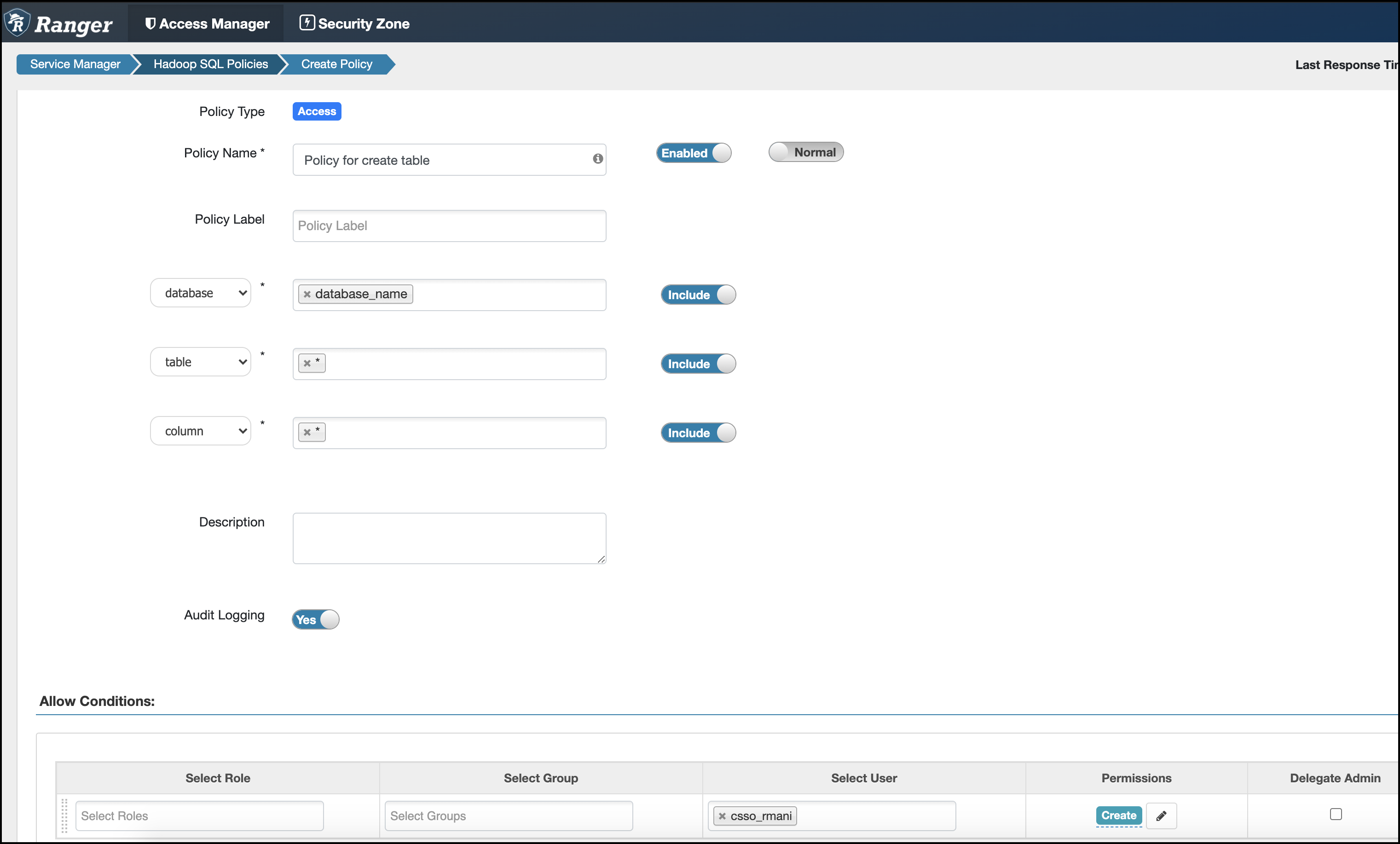
- Grant ALL on the bucket URI to the user's role, as shown in the following example:
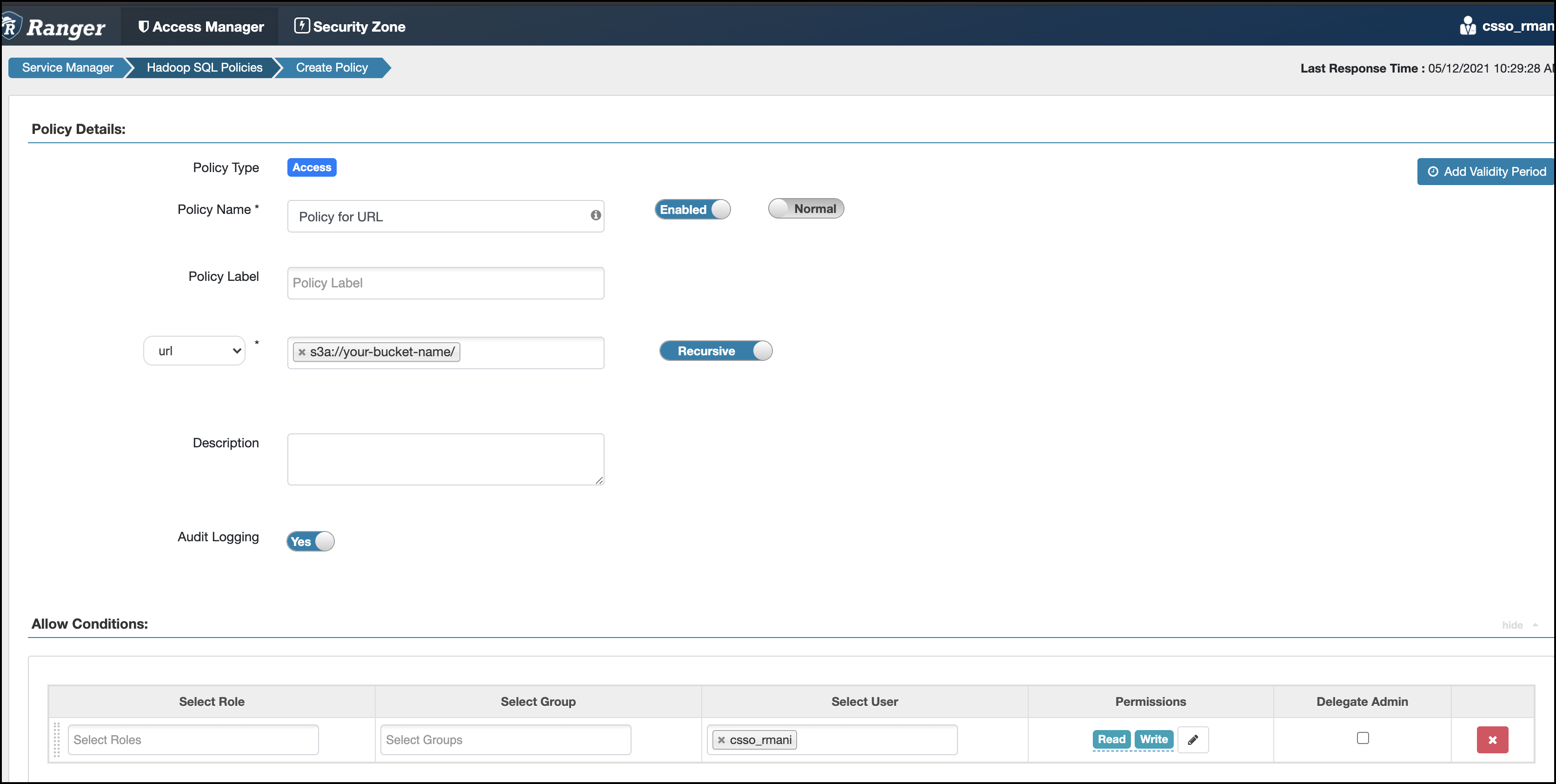
- The user must create the table with a reference to the database. For example:
CREATE EXTERNAL TABLE rangers3demo.your_external_s3_table (name STRING, type STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 's3a://your-bucket-name/';