Learn how to create a NiFi dataflow that processes Mainframe / EBCDIC encoded
data.
The basic steps of setting up the elements of your dataflow in NiFi involve opening
NiFi in a CDP Public Cloud Flow Management cluster, adding processors to your NiFi
canvas, and connecting the processors.
Open NiFi in CDP Public Cloud.
To access the NiFi service in your Flow Management cluster, navigate
to Management Console service > Data Hub Clusters.
Click the tile representing the Flow Management Data Hub cluster that
you want to work with.
Click the NiFi icon in the
Services section of the cluster overview page
to access the NiFi UI.
You will be logged into NiFi automatically with your CDP
credentials.
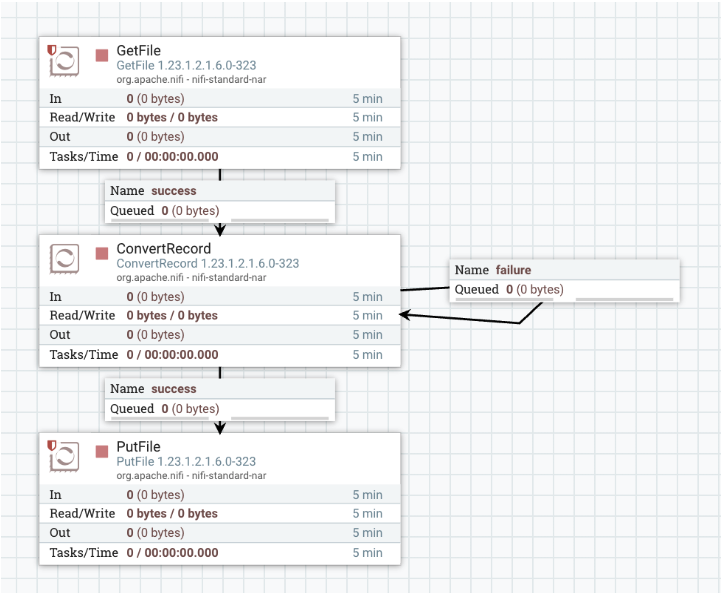
Add and configure the GetFile processor for data
input.
This processor creates FlowFiles from files in a directory.
Drag and drop the processor icon into the canvas.
This displays a dialog that allows you to choose the processor you
want to add.
Use the Add Processor filter box to search for
the GetFile processor and click Add.
You can use other processors (for example SFTP processors) to retrieve
offloaded binary files from a given location.
Add and configure the ConvertRecord processor for data
conversion.
This processor converts records from one data format to another using Record
Reader and Record Write Controller Services. You can use it to transform your
EBCDIC encoded data into JSON or other structured formats. Configure it with the
EBCDICRecordReader previously described and a default JSON writer.
Add and configure the PutFile processor for data
output.
You can replace PutFile with any other sink processor appropriate for your use
case (for example ingesting data into Iceberg, CDW, object store).
Connect the processors to create the flow.
Drag the connection icon from the one processor, and drop it on the
next processor.
Configure the connection.
Click Add to close the dialog box and add the
connection to your flow.
Your dataflow may resemble the following:
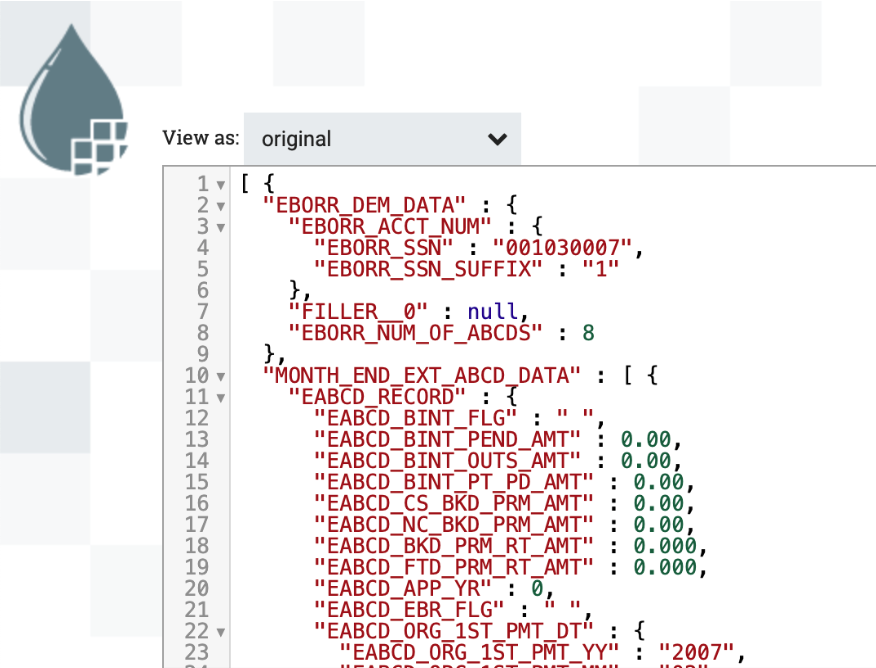
When this flow is running and receives a file from the Mainframe, it converts
the data to JSON format, with a result that would look like the following: