Streams Replication Manager replication flows and replication policies
Get familiar with the concepts of replication flows and replication policies. Additionally, learn about the default replication policies shipped with Streams Replication Manager (SRM) as well as the most commonly used types of replication flows.
Replication flows
Replication involves sending records and consumer group checkpoints from a source cluster to a
target cluster. In SRM, a replication flow (also referred to as a replication or flow) specifies
a source and target cluster pair, the direction in which data is flowing and the topics that are
being replicated. Source and target cluster pairs can be specified in Cloudera Manager; they are
notated source->target. Initially, when source->target pairs
are set up they are considered inactive, as no data is being replicated between them. To start
replication, you must specify which topics to replicate with the srm-control
command line tool.
Replication in SRM is configured independently for each source->target
cluster pair. Moreover, configuration is done on a per topic basis. This means that each topic
in a source cluster can have a different direction or target that it is being replicated to. A
set of topics in the source cluster can be replicated to multiple target clusters while others
are being replicated to only one target cluster. This allows users to set up powerful, topic
specific replication flows.
A basic example of a replication flow is when topics are being sent from one cluster to
another cluster in a different geographical location. Note that in this example there is only
one replication or source->target pair. Moreover, only one of the two topics on
the source cluster are being replicated to the target cluster.
Replication policies
In any replication flow, the selected source topics are replicated to remote (replicated) topics on the target cluster. The basic rules of how these topics are replicated is defined by the replication policy that is used by SRM. CDP includes two replication policies by default. These are the DefaultReplicationPolicy and IdentityReplicationPolicy. The main difference between the two policies is how they name remote topics. In addition to these policies, SRM also supports the use of custom replication policies.
- DefaultReplicationPolicy
- The DefaultReplicationPolicy is the default and Cloudera-recommended
replication policy. This is because the DefaultReplicationPolicy is capable
of automatically detecting replication loops and supports all monitoring features provided by
the SRM Service.
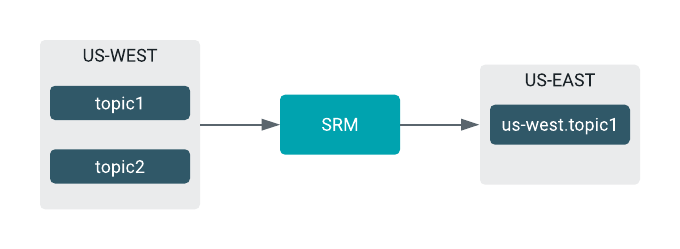
This policy prefixes the remote topic's name with the cluster name (alias) of the source topics. For example, the
topic1topic from theus-westsource cluster creates theus-west.topic1remote topic on the target cluster.Figure 2. Simple Replication Flow Example
If a remote topic is also replicated, the remote topic references all source and target clusters. The prefix in the name will start with the cluster closest to the final target cluster. For example, the
topic1topic replicated from theus-westsource cluster to theus-eastcluster and then to theeu-westcluster will be namedus-east.us-west.topic1.Figure 3. Complex Replication Flow Example 
- IdentityReplicationPolicy
-
The IdentityReplicationPolicy does not change the names of remote topics. When this policy is in use, topics retain the same name on both source and target clusters. For example, the
topic1topic from theus-westsource cluster creates thetopic1remote topic on the target cluster.
This type of replication is also referred to as prefixless replication. This replication policy is recommended for deployments where SRM is used to aggregate data from multiple streaming pipelines. Alternatively, this replication policy can also be used if the deployment requires MirrorMaker1 (MM1) compatible replication.
The IdentityReplicationPolicy has the following limitations:- Replication loop detection is not supported. As a result, you must ensure that topics are not replicated in a loop between your source and target clusters.
- The
/v2/topic-metrics/{target}/{downstreamTopic}/{metric}endpoint of SRM Service v2 API does not work properly with prefixless replication. Use the/v2/topic-metrics/{source}/{target}/{upstreamTopic}/{metric}endpoint instead. - The replication metric graphs shown on the Topic Details page of the SMM UI do not work with prefixless replication.
- Custom replication policies
- If neither the DefaultReplicationPolicy or IdentityReplicationPolicy fit your business requirements, you can develop your own replication policy implementation. Developing and using your own replication policy enables you to gain full control over how SRM replicates data. For more information, see the ReplicationPolicy interface in the Kafka Java documentation
Bidirectional replication flows
SRM supports bidirectional replication flows. A bidirectional replication flow is a setup where the topics of two or more clusters are mutually replicated. Records sent to one cluster are replicated to the other and the other way around. You can configure any number of clusters in this way.
A common issue with a bidirectional setup is that you can easily create replication loops. A replication loop is when a topic from one cluster is replicated to another and that same topic is replicated back to the source. The DefaultReplicationPolicy is capable of detecting replication loops. If this policy is in use, SRM will never replicate records in an infinite loop. As a result, you can freely use regex patterns in your allow and deny lists without having to worry about accidental replication loops.
The IdentityReplicationPolicy, on the other hand, cannot detect replication loops. As a result, if using this policy, you must ensure that topic allow and deny lists are correctly set up without any loops in the replication.
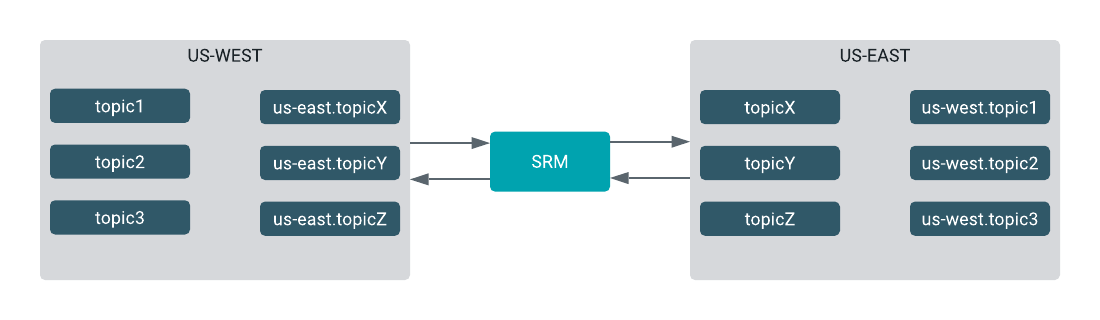
srm-control as
follows:srm-control topics --source us-west --target us-east --add "topic.*?"srm-control topics --source us-east --target us-west --add "topic.*?"srm-control commands with the
IdentityReplicationPolicy would, however, result in an endless replication
loop. Remote topics would be replicated back to their source. In a case like this, the allow and
deny lists must be correctly configured so that no loops are present. For
example:srm-control topics --source us-west --target us-east --add topic1, topic2, topic3srm-control topics --source us-east --target us-west --add topicX, topicY, topicZFan-in and fan-out replication flows
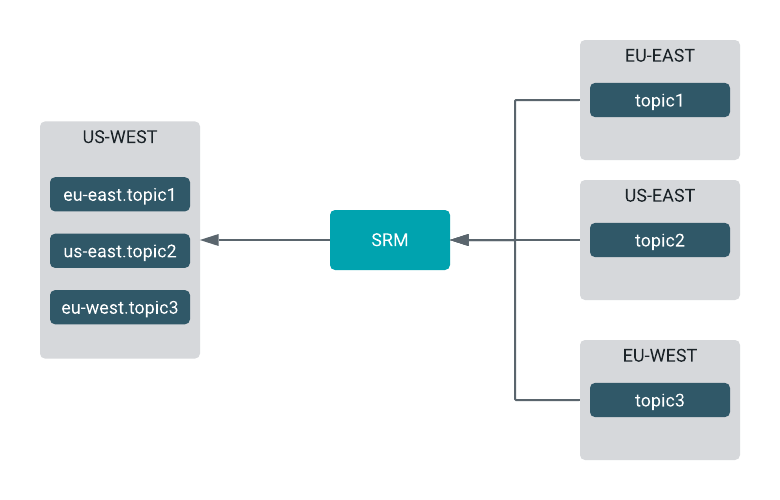
You can construct fan-in replication flows, where records from multiple source clusters are aggregated in a single target cluster.
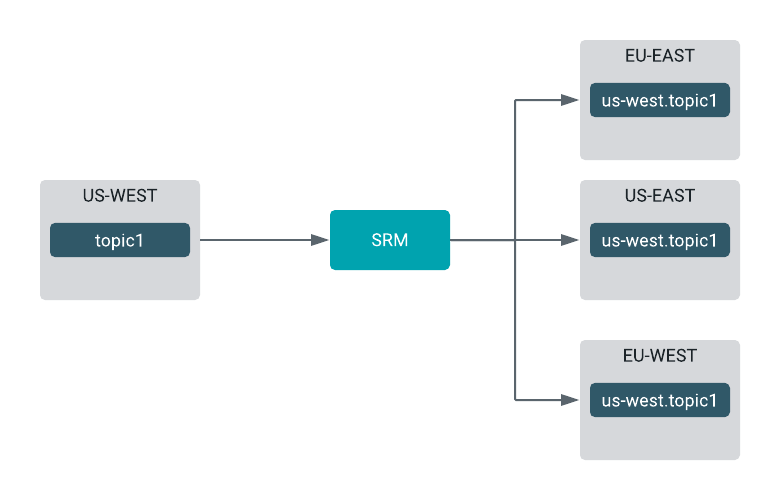
Similarly, you can construct fan-out replication flows as well, where a single cluster is replicated to multiple target clusters.