Examples of accessing Amazon S3 data from Spark
The following examples demonstrate basic patterns of accessing data in S3 using Spark. The examples show the setup steps, application code, and input and output files located in S3.
Reading and Writing Text Files From and To Amazon S3
Run a word count application on a file stored in Amazon S3
(sonnets.txt in this example):
- Scala
-
val sonnets = sc.textFile("s3a://dev-env/test-data/sonnets.txt") val counts = sonnets.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) counts.saveAsTextFile("s3a://dev-env/test-data/sonnets-wordcount") - Python
-
sonnets = sc.textFile("s3a://dev-env/test-data/sonnets.txt") counts = sonnets.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda v1,v2: v1 + v2) counts.saveAsTextFile("s3a://dev-env/test-data/sonnets-wordcount")
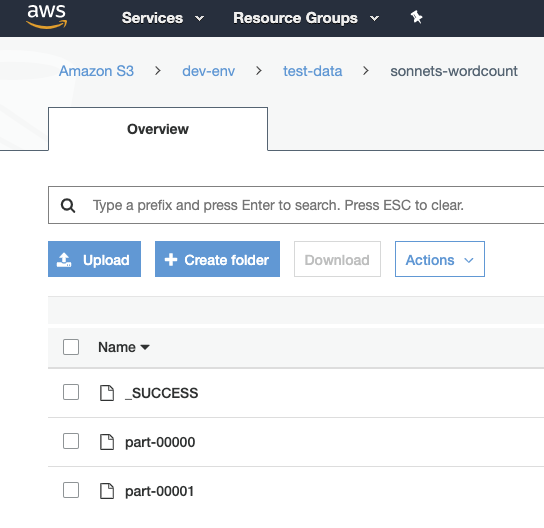
Yielding the output:
Reading and Writing Data Sources From and To Amazon S3
The following example illustrates how to read a text file from Amazon S3 into an RDD, convert the RDD to a DataFrame, and then use the Data Source API to write the DataFrame into a Parquet file on Amazon S3:
- Read a text file in Amazon S3:
val sample_data = sc.textFile("s3a://dev-env-data/test-data/sample_data.csv") - Map lines into columns:
import org.apache.spark.sql.Row val rdd_sample = sample_data.map(_.split('\t')).map(e ⇒ Row(e(0), e(1), e(2).trim.toInt, e(3).trim.toInt)) - Create a schema and apply to the RDD to create a DataFrame:
scala> import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}; scala> val schema = StructType(Array( StructField("code",StringType,false), StructField("description",StringType,false), StructField("total_emp",IntegerType,false), StructField("salary",IntegerType,false))) scala> val df_sample = spark.createDataFrame(rdd_sample,schema) - Write DataFrame to a Parquet file:
df_sample.write.parquet("s3a://dev-env-data/test-data/sample_data-parquet")
The files are compressed with the defaultsnappycompression.