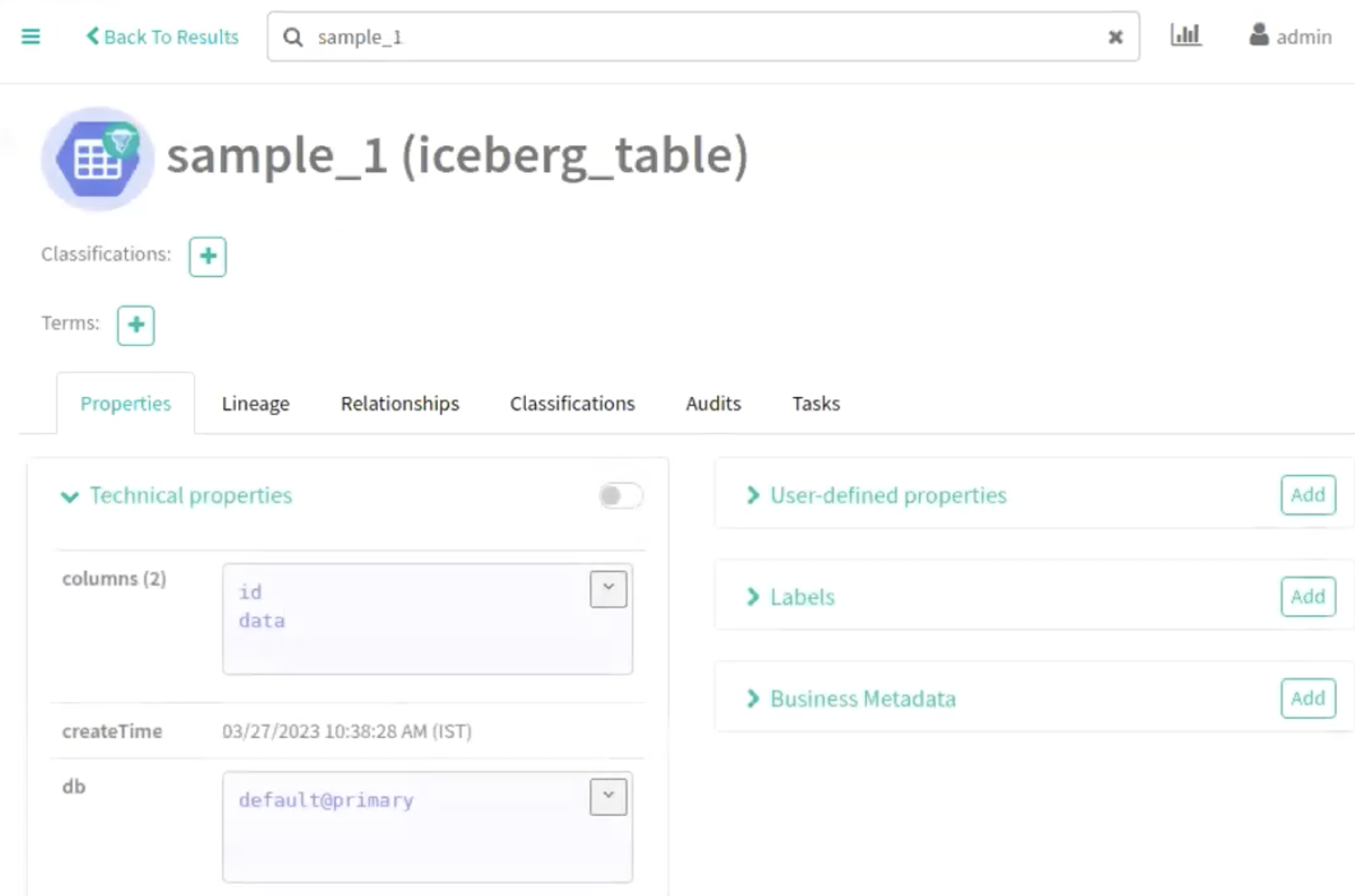
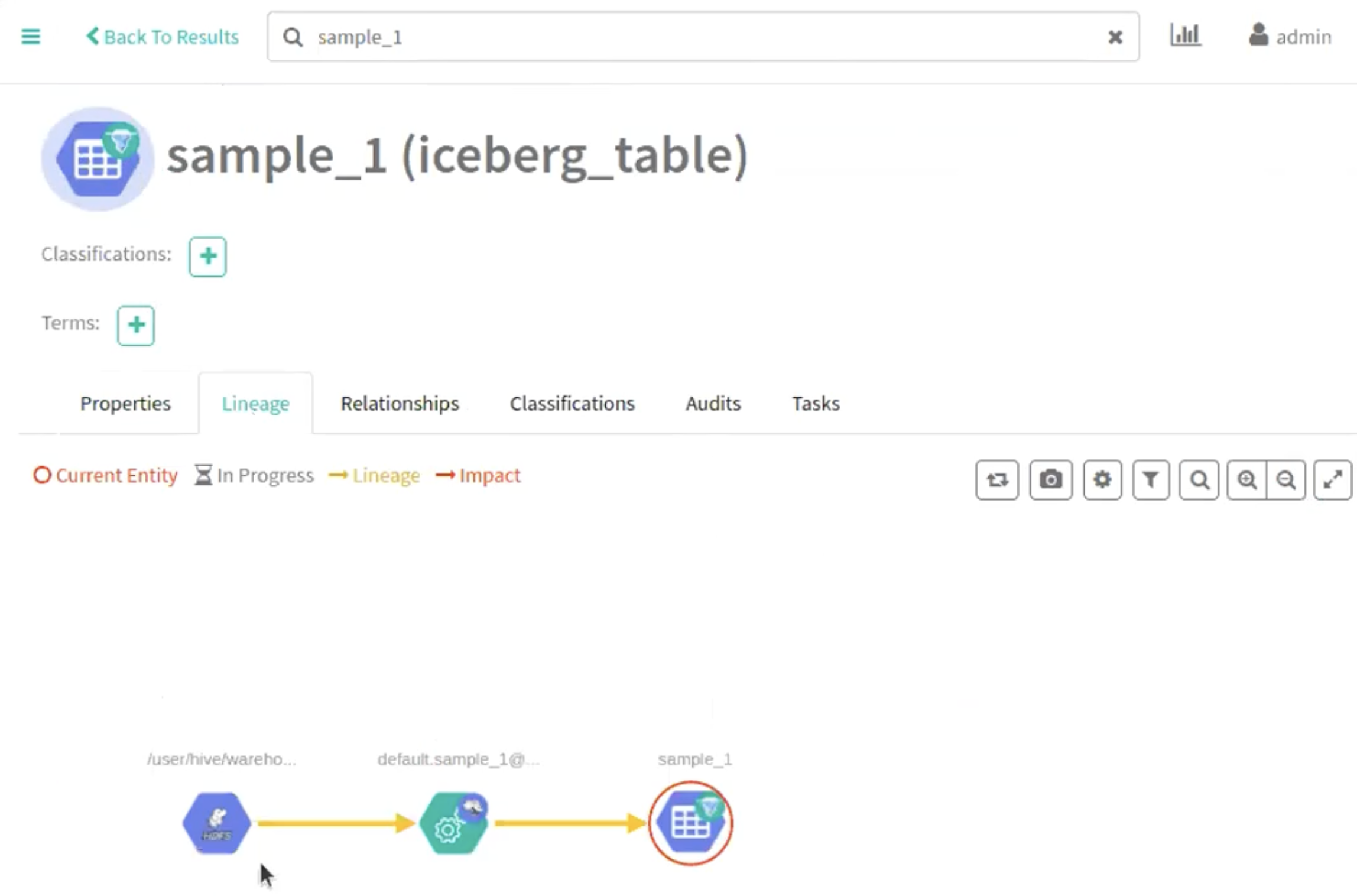
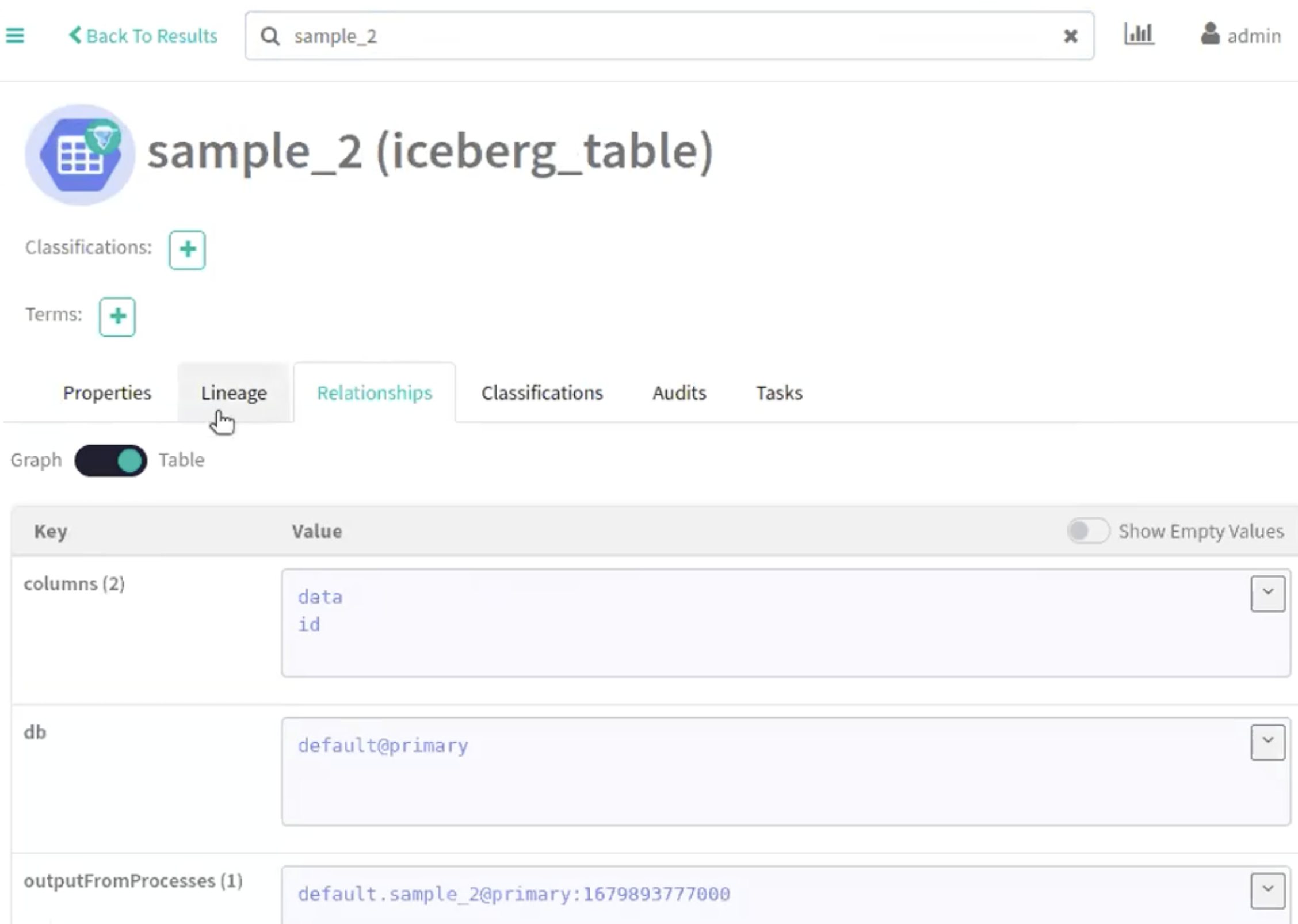
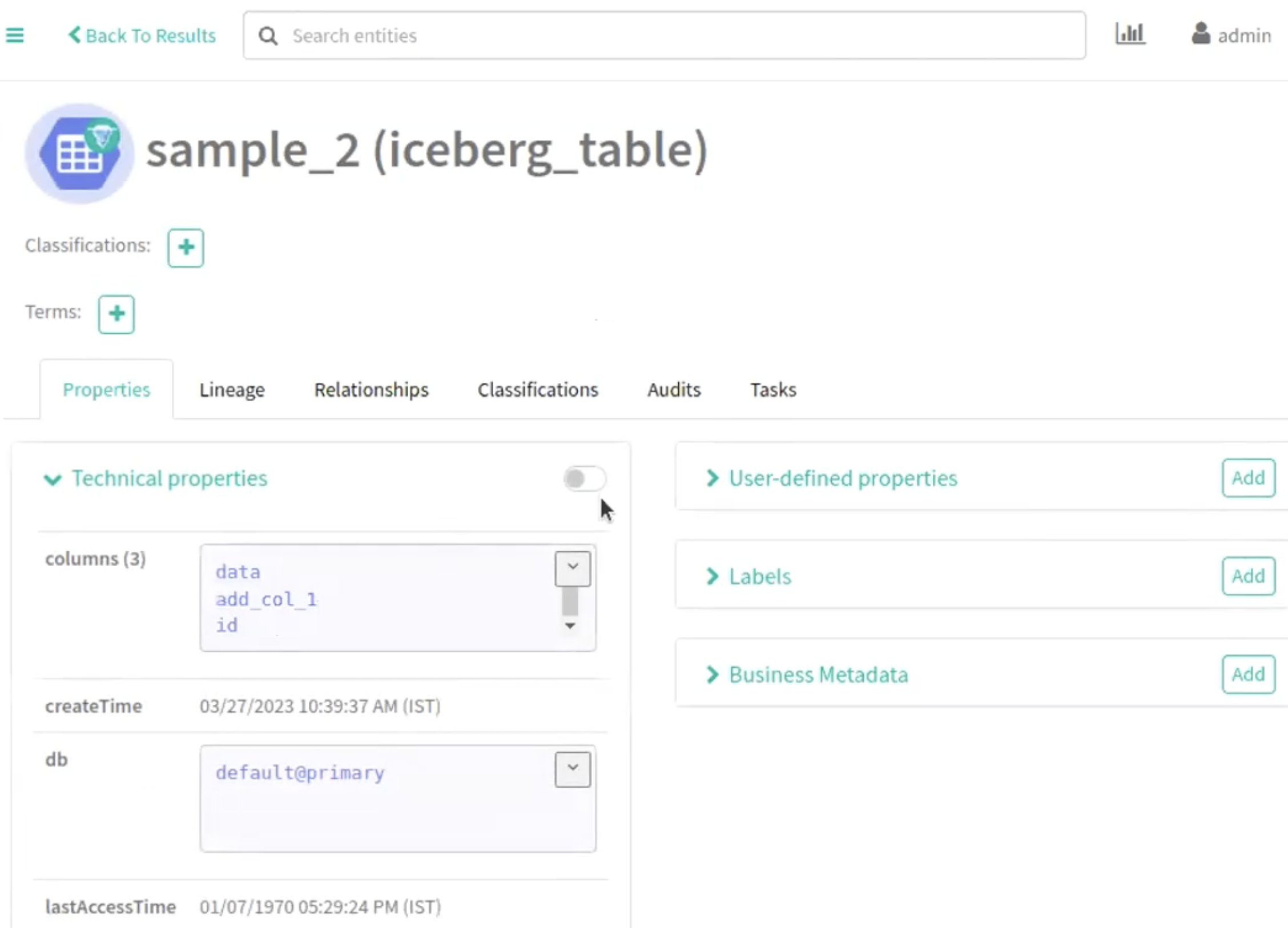
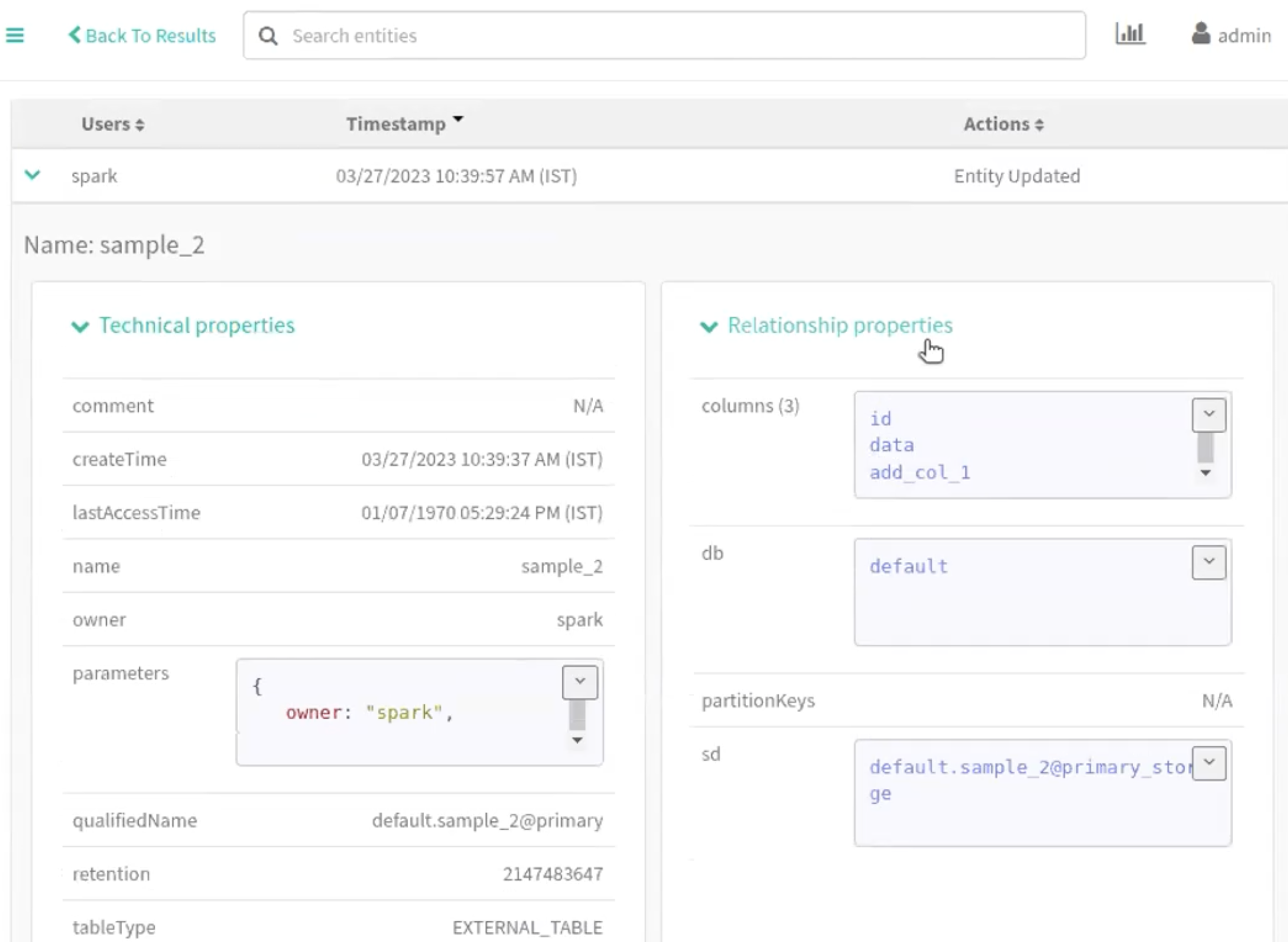
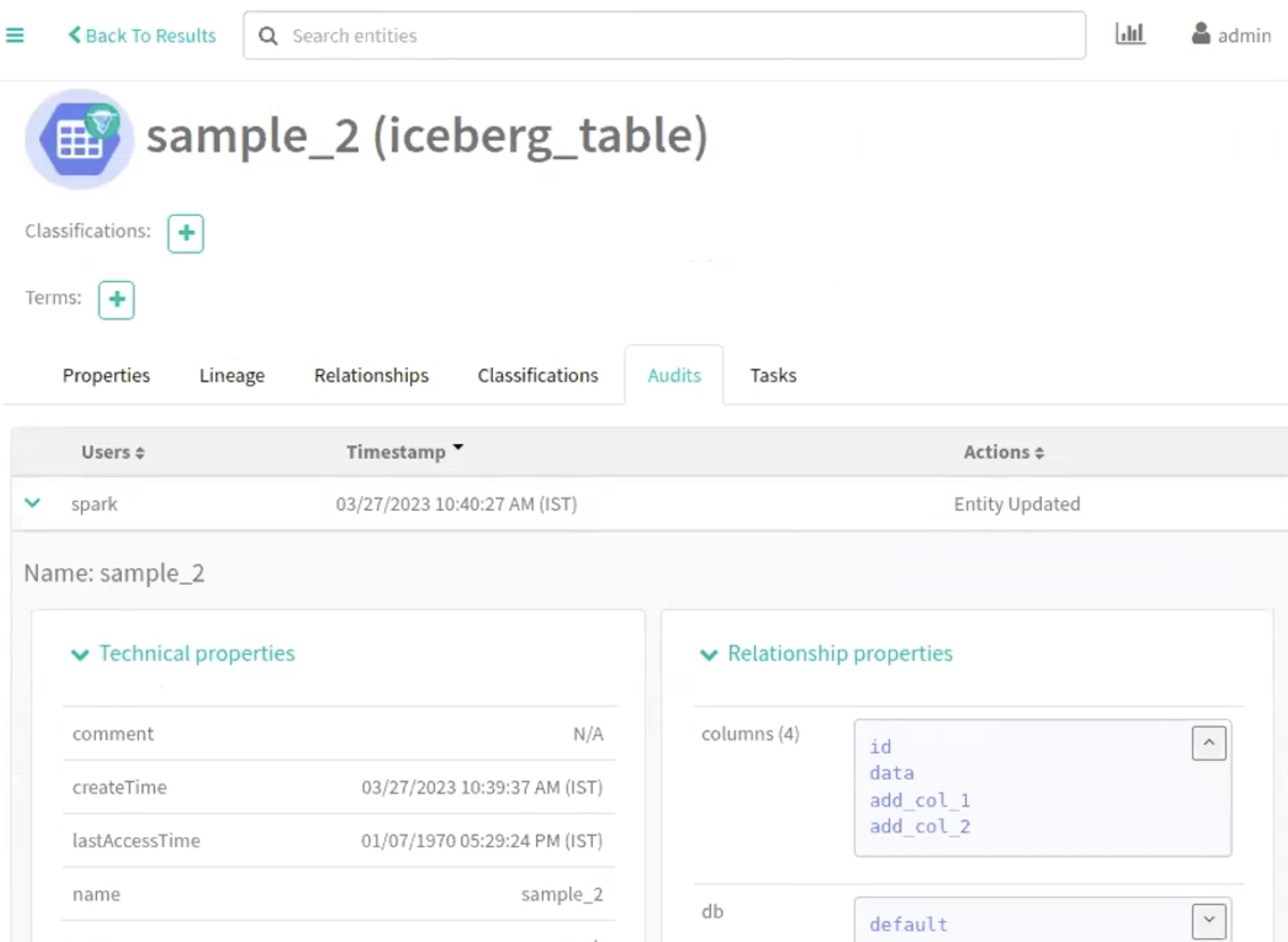
Navigate accordingly in the Atlas UI to view the changes.
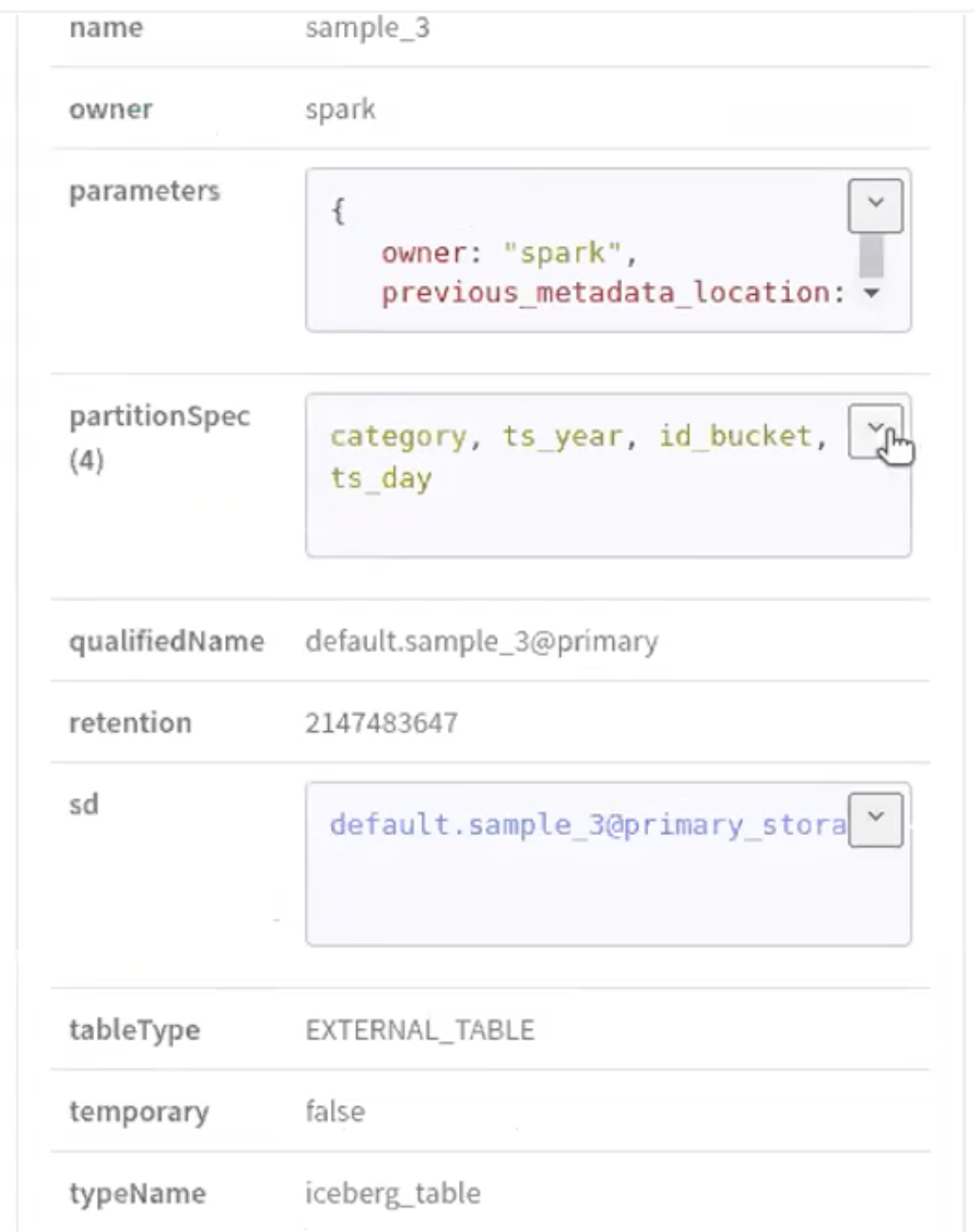
The following image provide information about Iceberg schema creation
process.
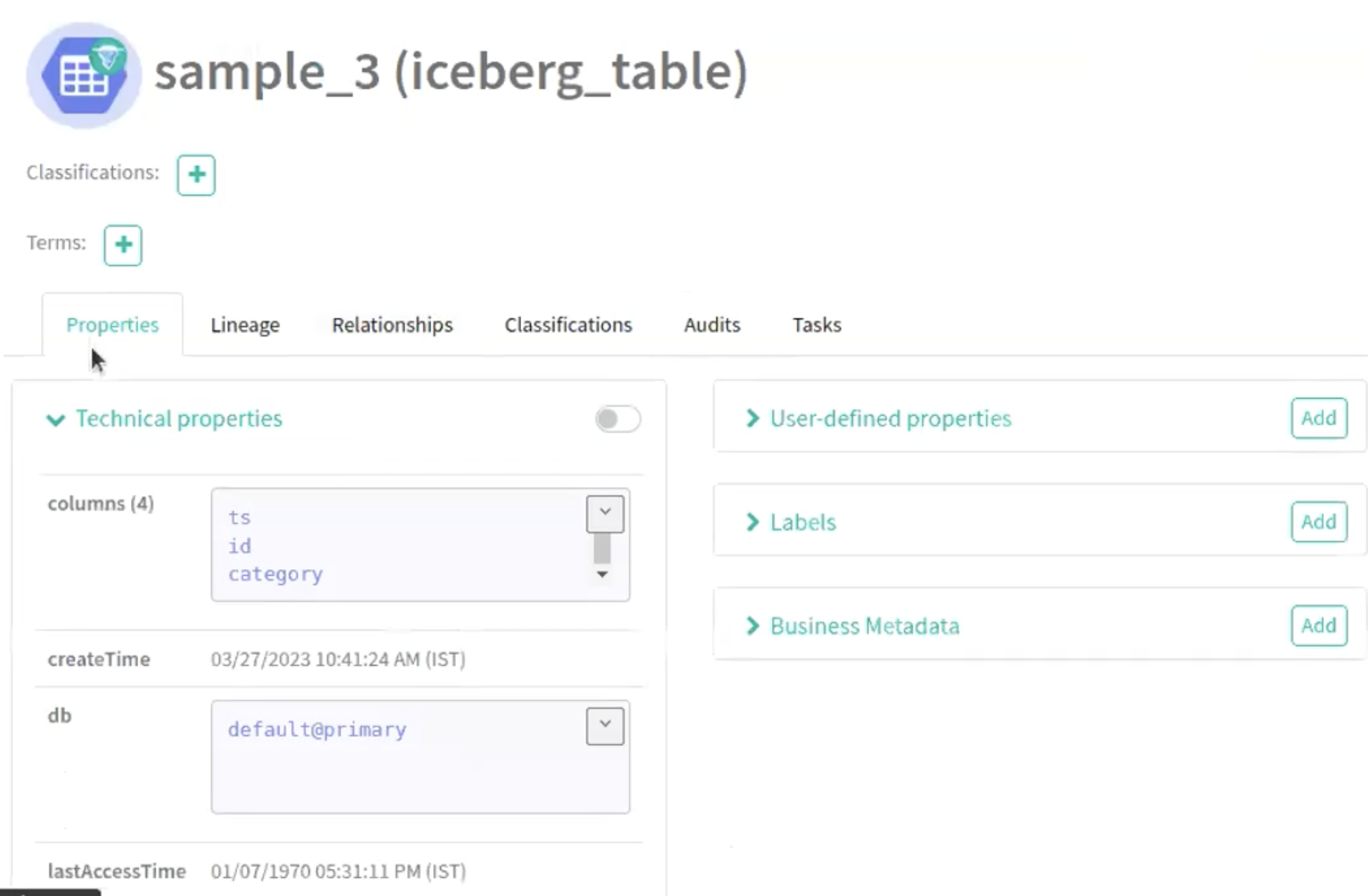
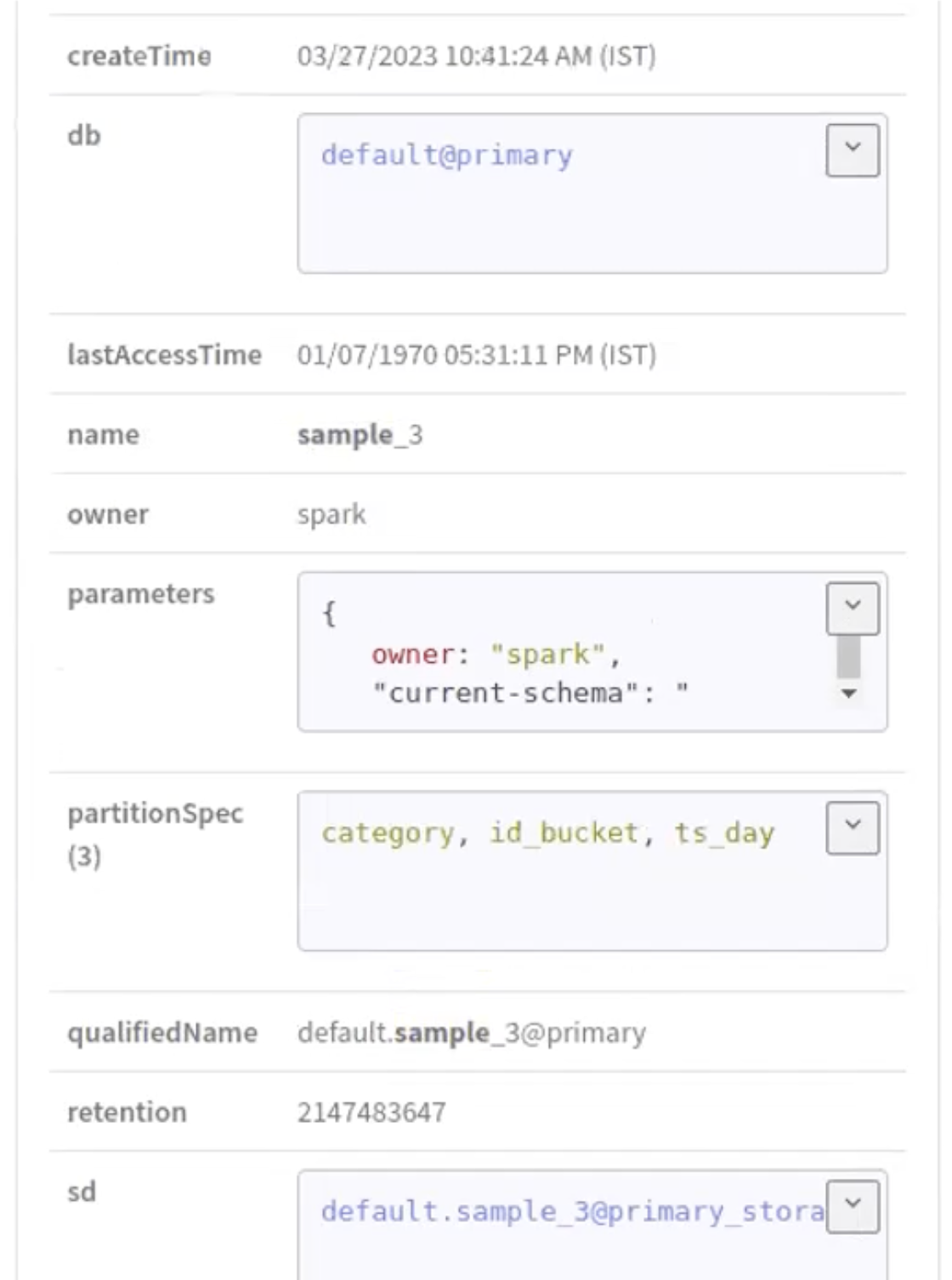
Run the following command in your Spark shell to create a
Partition Specification in a new table
(sample_3):
spark.sql("CREATE TABLE spark_catalog.default.sample_3 (id bigint,data
string,category string,ts timestamp) USING iceberg PARTITIONED BY (bucket(16,
id), days(ts), category)");
Navigate accordingly in the Atlas UI to view the changes.
The following images provide information about Iceberg partition specification
process.
Run the following command in your Spark shell to create a
Partition Evolution in a new table (sample_3):
spark.sql("ALTER TABLE spark_catalog.default.sample_3 ADD PARTITION FIELD
years(ts)");
Navigate accordingly in the Atlas UI to view the changes.
The following images provide information about Iceberg partition evolution
process.
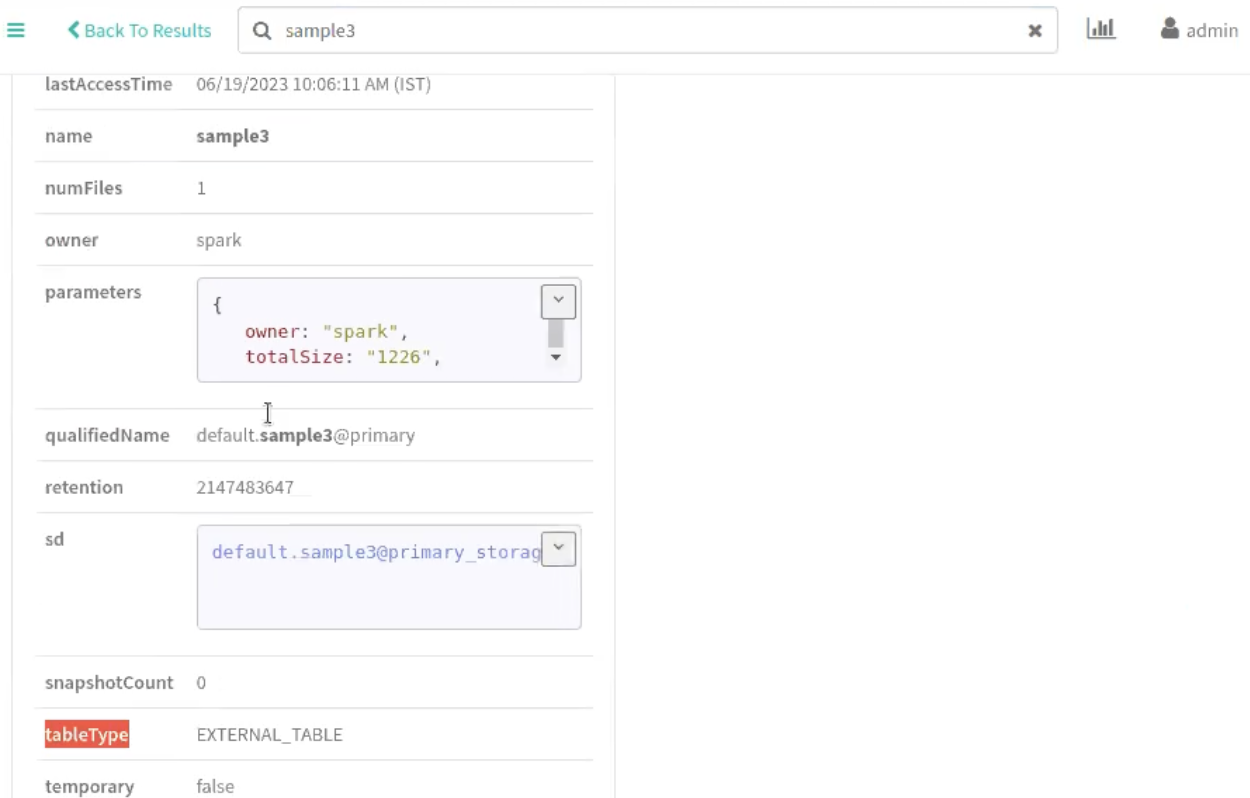
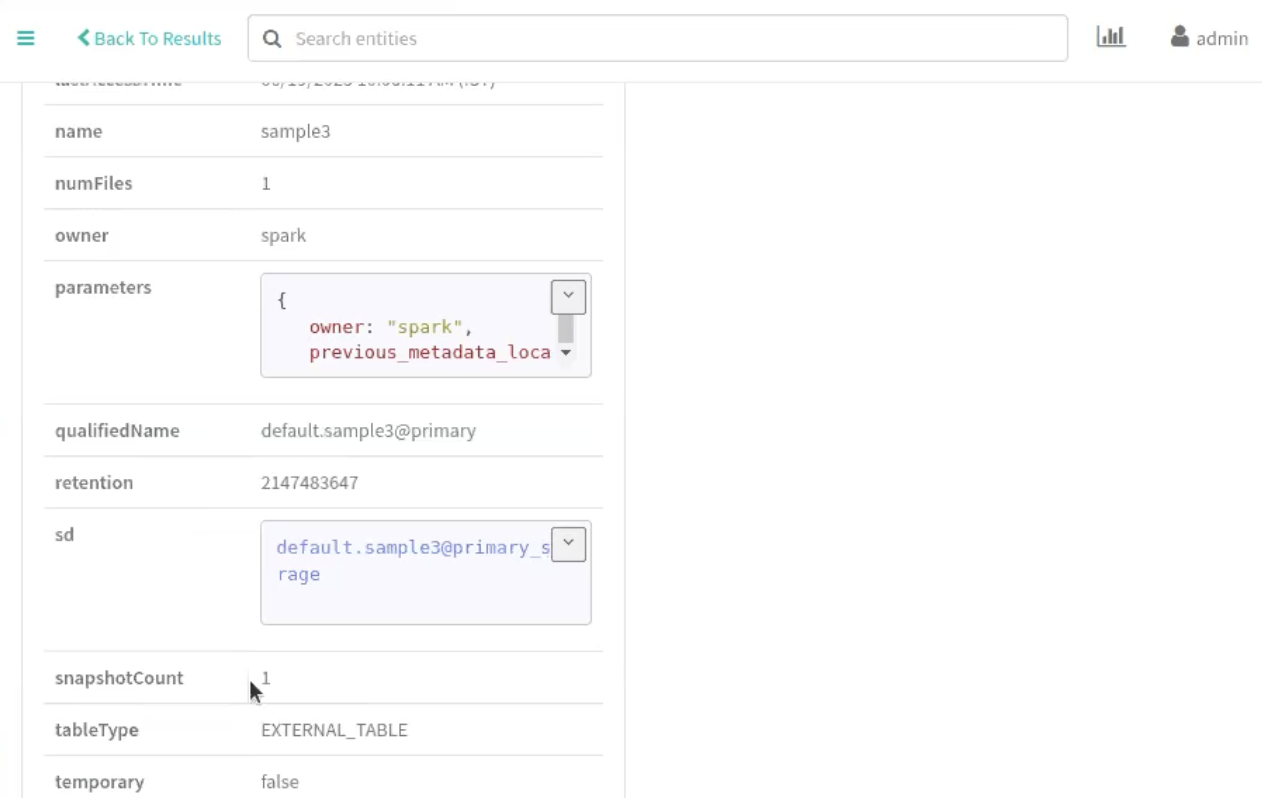
Displaying Snapshot attributes
Run the following command to display relevant snapshot table
parameters as attributes in Atlas. For example: Existing snapshot ID,
current snapshot timestamp, snapshot count, number of files and related
attributes.
spark.sql("CREATE TABLE spark_catalog.default.sample3 ( id
int, data string) USING iceberg");
spark.sql("INSERT INTO default.sample3 VALUES (1,
'TEST')");
Run the following command to scale up the snapshot count value.
spark.sql("INSERT INTO default.sample3 VALUES (1,
'TEST')");
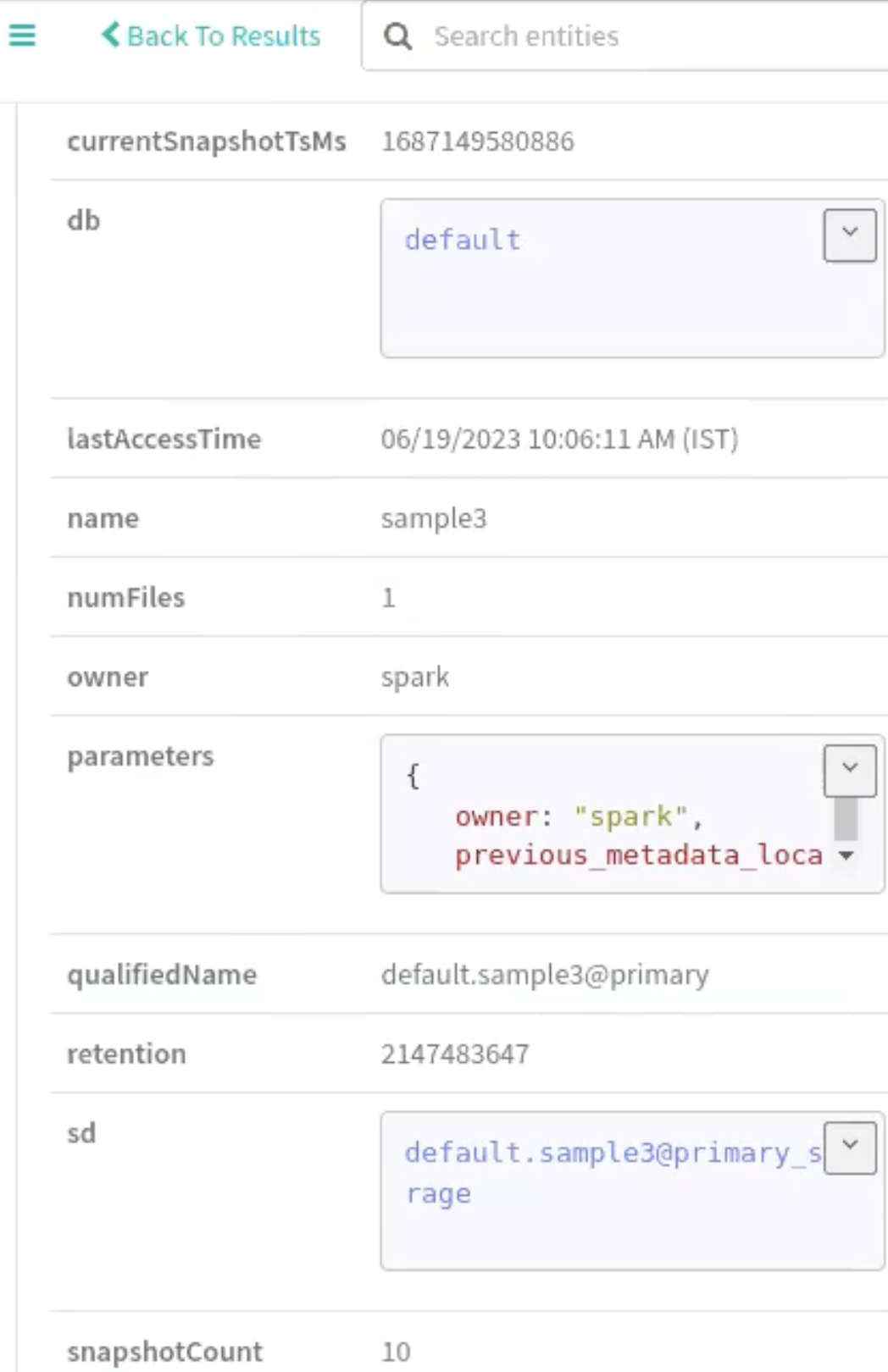
The latest Snapshot ID that Iceberg points
to along with the Snapshot timestamp and
Snapshot count are updated respectively.
Click on the parameters field to display the
details pertaining to the snapshot attributes.
Support for data compaction
Data Compaction is the process of taking several small files and
rewriting them into fewer larger files to speed up queries. When performing
compaction on an Iceberg table, execute the rewriteDataFiles procedure,
optionally specifying a filter of which files to rewrite and the desired
size of the resulting files.
As an example, in an Atlas instance consider that the number of
files and snapshot count are 9.
Run the following command to perform data compaction
The count for the number of rewritten data files is
compacted from a total count of 9 to 1.
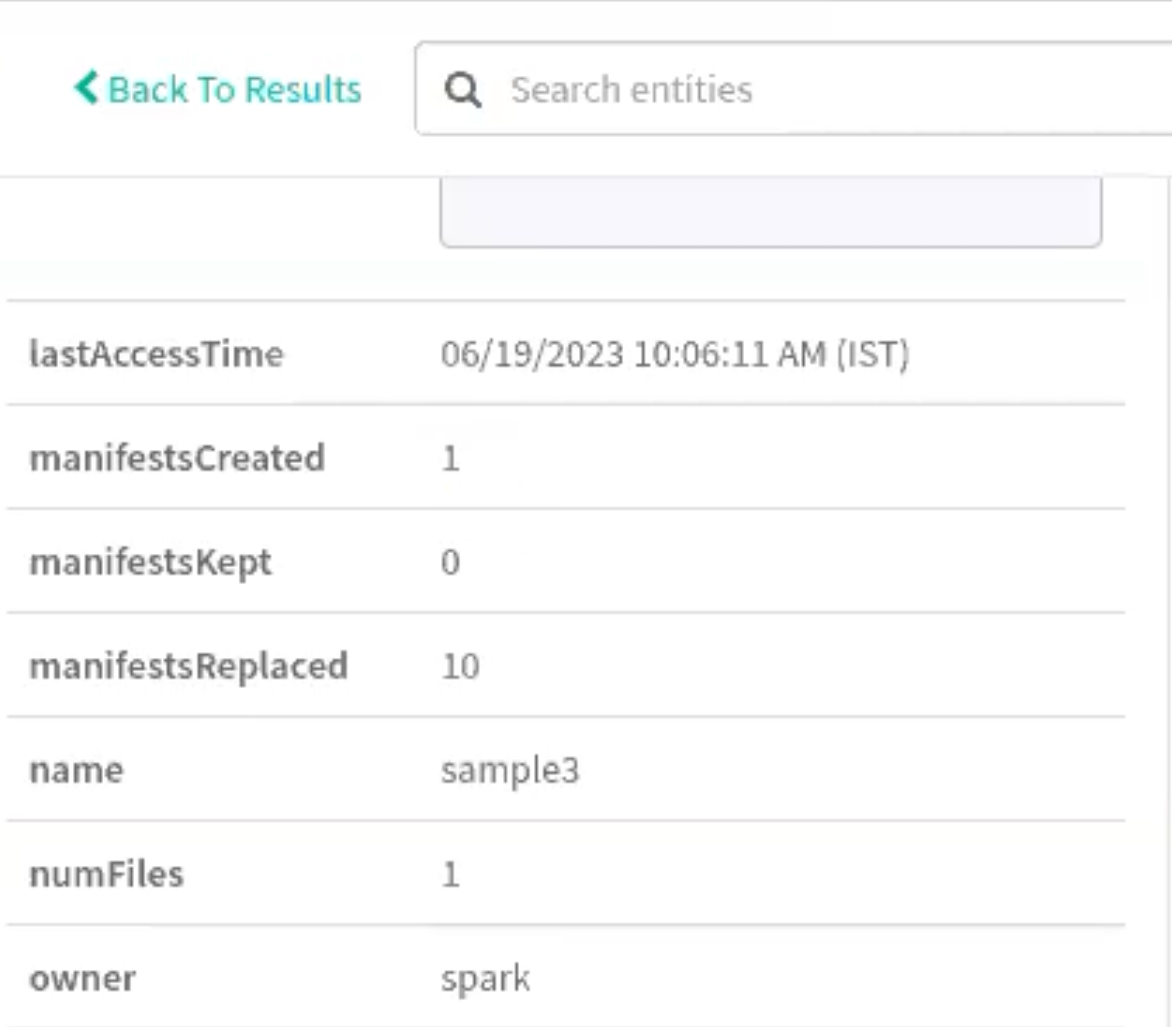
Support for metadata rewrite
attributes
Iceberg uses metadata in its manifest list and manifest files speed
up query planning and to prune unnecessary data files. You can
rewrite manifests for a table to optimize the plan to scan the
data.
Run the following command to rewrite manifests on a sample table
3.