Using Spark SQL
This section provides information about using Spark SQL.
There are two ways to interact with Spark SQL:
-
Interactive access using the Spark shell (see "Accessing Spark SQL through the Spark Shell" in this guide).
-
From an application, operating through one of the following two APIs and the HiveServer2:
-
JDBC, using your own Java code or the Beeline JDBC client
-
ODBC, through the Simba ODBC driver
-
The following diagram illustrates the access process, depending on whether you are using the Spark shell or business intelligence (BI) application:
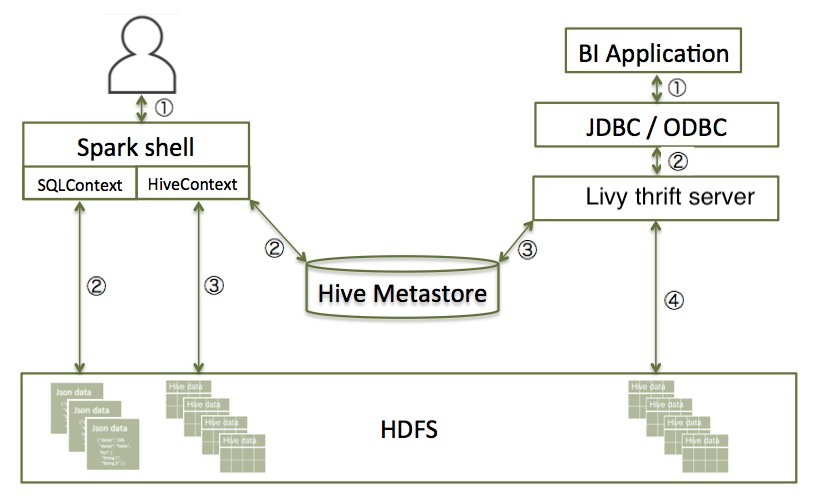
The following subsections describe how to access Spark SQL through the Spark shell, and through JDBC and ODBC.