Known Issues and Limitations
There are some known issues you might run into while using Cloudera AI.
Model download fails after Cloudera AI Registry in-place upgrade on Azure (DSE-58510)
On Azure public cloud deployments running Cloudera AI Registry
1.13.0-b41 or later, performing an in-place upgrade of the Cloudera AI Registry causes subsequent model download operations to fail.
While the upgrade process itself may appear to complete successfully, the registry becomes
unable to process download requests post-upgrade. This issue strictly impacts Azure-backed
workbenches that utilized the Cloudera AI Registry in-place upgrade
feature.
Cloudera AI workloads fail due to PostgreSQL shared memory exhaustion (DSE-57237)
Cloudera AI workloads can fail when internal PostgreSQL instances
(cdsw-db and cdsw-model-metrics pods) exhaust their
shared memory segment during parallel queries. Kubernetes caps the memory-backed
/dev/shm volume at 64 MB by default, which fills under heavy load. When
exhausted, queries fail with QueryFailedError: could not resize shared memory
segment... No space left on device, causing dependent tasks to fail.
posix to mmap, redirecting shared memory to the larger
$PGDATA persistent volume:- Run this command on your Cloudera AI Kubernetes
cluster:
kubectl exec -it db-0 -n <CML_WORKBENCH_NAMESPACE> -- psql -U sense -c "ALTER SYSTEM SET dynamic_shared_memory_type = 'mmap';" - Restart the database pod to apply the change.
LiveLog cleanup fails on Istio-enabled workbenches (DSE-58563)
On Istio-enabled Cloudera AI Workbenches running on version
2.0.55-b193 or later, the automated livelog-cleaner
job fails to delete old LiveLog topics because DELETE requests are blocked
by the Istio AuthorizationPolicy with an HTTP 403 error. This occurs
because the policy excludes the sa-cdsw-livelog-cleaner service account
from its allowed principals, while a secondary bug silently marks these failed attempts as
cleaned, permanently skipping them in future cycles. Over time, LiveLog storage fills up and
PVC capacity is exhausted, eventually causing session and workload failures with the
No space left on device" error.
Issues after upgrading Cloudera AI Workbench to v2.0.58 on Public Cloud (DSE-58422, DSE-58496, DSE-58500)
2.0.58 on Public
Cloud, the base integration setting (EnableBaseIntegration) is incorrectly
set to false. Because this base integration configuration is missing, the
following issues occur: - Spark session failures: Apache Spark sessions fail with a
ModuleNotFoundErrorerror because the required Hadoop configuration files are not generated and necessary Spark paths are not added to thesys.pathPython path. - Cloud storage access failures: Accessing cloud storage using the
hadoop fs -lscommand fails with an exception. - Data Hub connection fallback: Data Hub data connections revert to requiring username and password authentication instead of integrated authentication.
- Run the following commands to patch the configuration map, update the environment
deployment variables, and trigger a rolling restart of the
API:
kubectl -n mlx patch configmap api-config --type merge \ -p '{"data":{"api.enable.base.integration":"true"}}' kubectl -n mlx set env deployment/web ENABLE_BASE_INTEGRATION=true kubectl -n mlx rollout restart deployment/api
Users quota table displays 0 value instead of actual quota values
(DSE-50999)
In the Cloudera AI Workbench UI, the Users quota table incorrectly
displays 0 value for all custom quota values, including CPU, GPU, and
memory, instead of the actual values returned by the backend. This occurs because the
api/v1/quotas/custom-quota endpoint returns field names in
snake_case format, which the UI does not parse correctly. Although the
backend returns the correct quota values, the UI fails to map them, resulting in all quota
fields appearing with 0 value in the table.
livelog-go fails during reconnect (DSE-56531)
In Cloudera AI Workbench version 2.0.52-b27 or later, the
livelog‑publisher might crash with a concurrent write to
websocket error when its WebSocket connection drops. This results in
temporary loss of container logs.
Azure endpoints incorrectly display Failed state in UI despite healthy
background status (DSE-58509)
All Azure endpoints might incorrectly display a Failed state in the Cloudera AI Inference service user interface. This is a UI synchronization issue,
the endpoints continue to run normally and backend inference requests succeed.
Workaround: Stop and restart the affected endpoint. This forces the UI to syncronize
and display the correct status, that is Succeeded or
Running.
Multi-gpu TRT-LLM deployments fail with NCCL errors on EKS 1.33 or higher (DSE-58056)
Deploying TRT-LLM NIMs using multi-GPU profiles (where tensor parallelism is greater than 1) on AWS clusters running EKS version 1.33 or higher results in container initialization failures due to a localized NCCL error. This issue specifically impacts PCIe GPU instances on AWS because the default EKS 1.33 Amazon Machine Image (AMI) ships with an incompatible CUDA 13.0 configuration. Single-GPU deployments and clusters running on Microsoft Azure are completely unaffected by this infrastructure limitation.
Missing CPU and Memory values for Infra Node instance types on Azure (DSE-57351)
On Cloudera AI Workbench deployed on Azure, the CPU and Memory fields are displayed as hyphens for Infra Node instance types (such as Standard_D8ds_v5 and Standard_D4ds_v5) under the Node Groups > Infra Nodes section of the Configuration page.
This is a display-only issue in the UI metadata representation. The underlying infrastructure and instance types remain correctly provisioned, fully operational, and completely unaffected in terms of workload execution or autoscaling capabilities.
Workaround: To verify the exact hardware specifications of your infrastructure nodes, see the respective instance types directly within the official Microsoft Azure VM sizes documentation (for example, Standard_D8ds_v5 provides 8 vCPUs and 32 GiB RAM).
Model Endpoint updates fail with a 400 error. (DSE-55495)
When attempting to update an existing Model Endpoint, the operation fails and the backend
returns a 400 Bad Request error. This occurs because the user interface
sends an unexpected property in the update payload, which the backend currently rejects.
Workaround: To apply changes to a Model Endpoint, you must delete the existing endpoint and recreate it with the desired configuration.
The testing interface for the Magpie model incorrectly requires audio input instead of text. (DSE-50753)
When testing the Magpie model through the user interface, the system incorrectly prompts for an audio sample as the input. Because Magpie is a Text-to-Speech (TTS) model, it is designed to take text as input and generate audio as the output. The current UI configuration prevents users from providing the text strings necessary to test the model's speech generation functionality.
Certain optimization profiles and metadata fields (VAD/Diarization) are unsupported when using the HTTPS transcription API with the Parakeet 1.1B NIM runtime.(DSE-51840)
The NVIDIA Parakeet 1.1B NIM (v1.4.0) has technical limitations when using the HTTPS transcription API. Additionally, VAD and Diarization metadata are not exposed in the JSON response, meaning only plain transcript text is returned. As a result, speaker labels and related fields are currently unavailable through this interface.
Cloudera AI Inference service Actions menu is greyed out on the Details page. (DSE-54891)
Administrator actions on the Cloudera AI Inference service Details page remain disabled despite a healthy service status.
Workaround: Use the Cloudera AI Inference service List view to access and execute these actions.
Parakeet UI code samples unavailable (DSE-53227)
/audio/translations endpoint may not be supported across all
model variants, which may result in HTTP
errors.import requests
import json
import urllib3
# Suppress SSL warnings for demonstration purposes
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# Replace with your actual endpoint URL and API Key
BASE_URL = "https://<your-domain-name>/namespaces/<namespace>/endpoints/<endpoint-name>/v1"
API_KEY = "<YOUR_API_KEY>"
headers = {
"Authorization": f"Bearer {API_KEY}"
}
# For transcribing an audio file
def transcribe_audio(audio_file_path, language="en-US"):
url = f"{BASE_URL}/audio/transcriptions"
with open(audio_file_path, "rb") as f:
files = {"file": f}
data = {"language": language}
# Note: verify=False is for demonstration only. Re-enable for production.
response = requests.post(url, headers=headers, files=files, data=data, verify=False)
response.raise_for_status()
return response.json()
# For translating an audio file
def translate_audio(audio_file_path, language="en-US"):
url = f"{BASE_URL}/audio/translations"
with open(audio_file_path, "rb") as f:
files = {"file": f}
data = {"language": language}
response = requests.post(url, headers=headers, files=files, data=data, verify=False)
response.raise_for_status()
return response.json()
# Example usage
audio_file = "/path/to/your/audio_file.wav"
# Transcribe
try:
print("=== Transcription ===")
transcription_result = transcribe_audio(audio_file, "en-US")
print(json.dumps(transcription_result, indent=2))
except Exception as e:
print(f"Transcription error: {e}")
# Translate (if supported by the model)
print("\n=== Translation ===")
try:
translation_result = translate_audio(audio_file, "en-US")
print(json.dumps(translation_result, indent=2))
except requests.exceptions.HTTPError as e:
print(f"Translation not supported by this model variant: {e}")IAM Policy Simulator preflight check fails with resource policy validation (DSE-53148)
IAM Resource Policy validation failed on AWS. CrossAccount role does not have permissions for these operations : : ssm:GetParameter, ssm:GetParameters, ssm:GetParameterHistory, ssm:GetParametersByPathThis happens because even if a given cross account role is allowed to perform a certain action (granted through IAM Policies), an attached Service Control Policy (SCP) may override that capability if it enforces a Deny on that action. SCP takes precedence over IAM Policies. SCPs are either applied at the root of an organization, or can be applied to individual accounts. A permission can be blocked at any level above the account, either implicitly or explicitly (by including it in a Deny policy statement). As the IAM Simulator SDK does not have an option to include or exclude an organization’s SCP policy, the preflight check will fail if an SCP policy is denying an action, even though the IAM role has the necessary permissions.
This is a known issue in AWS.
- UI-based skip: When configuring the service, select the Skip Validation option in the user interface. This allows you to proceed with the setup despite the preflight check failure.
- Account entitlement: Use the
LIFTIE_DISABLE_IAM_PREFLIGHT_CHECKentitlement for your account. This is a Liftie-level configuration that specifically skips the IAM Policy preflight validation while allowing other critical checks to remain active.
Incorrect capacity reservation details lead to misleading error messages (DSE-52081)
When configuring a GPU node group, providing an incorrect Capacity Reservation ID or selecting a subnet that does not match the reservation's region causes the system to generate irrelevant or misleading error messages. This can make it difficult to identify the root cause as a configuration mismatch.
Workaround: Verify your AWS capacity reservation details before entry. Ensure that the Capacity Reservation ID is exact and that the selected Subnet is associated with the specific cluster and region where the reservation was originally created.
Failures in Cloudera AI model deployments and workbench provisioning on Azure (DSE-50902)
An incompatibility has been identified between recently updated Azure Kubernetes Service (AKS) node images (released on February 2, 2026) and Buildkit, a critical component of the Cloudera AI Workbench. This issue causes failures when attempting to provision new workbenches, deploy new models, or deploy new workflows within Agent Studio. Additionally, attempting to restart or scale out existing model deployments will also fail. Other core workbench functionalities remain unaffected.
- Do not stop or scale down any currently operational models that may need to be restarted.
- Refrain from creating or upgrading any Cloudera AI Workbench deployments.
Cloudera AI Inference service CPU and GPU nodes are unable to scale up (COMPX-25220)
When Cloudera AI Inference service is installed on a new Compute Cluster or after an existing Compute Cluster has been upgraded, CPU and GPU node groups may fail to scale up. This leads to Model Endpoints remaining in a Pending state for an extended duration before eventually failing to deploy.
Workaround: You must manually reconfigure the cluster autoscaler deployment within the affected Compute Cluster. Ensure that you are using a recent version of CDP CLI.
- Obtain the Compute Cluster CRN.
- In the Management Console UI, navigate to Environments > <Your Environment> > Compute Clusters.
- Locate the compute cluster used for the installation of the Cloudera AI Inference service .
- Copy the CRN identifier for the cluster.
- Execute the following command in your terminal to reconfigure the cluster autoscaler
deployment in your Compute
Cluster:
cdp compute upgrade-deployment \ --cluster-crn <COMPUTE_CLUSTER_CRN> \ --name autoscaler \ --namespace kube-system \ --overrides '{"extraArgs":{"startup-taint_0":"ebs.csi.aws.com/agent-not-ready", "startup-taint_1":"efs.csi.aws.com/agent-not-ready"}}'
Incorrect Knox version warning (DSE-51893)
During deployment of an application on the Cloudera AI Inference service, the system may incorrectly display a warning stating that Knox version 3.0.0 is required. This message can be safely ignored, as the actual minimum requirement for this release is Knox version 2.0.2-dsp.1.
Cloudera AI Inference service installation fails with Knox add-on conflict (DSE-51010)
Attempting to install Cloudera AI Inference service version
1.8.0 on a compute cluster provisioned with Knox add-on version
3.0.0-dsp.3 (typically clusters created after January 30, 2025) may
result in a Helm installation failure.
proxy-extauthz service. The installation fails with the following
error:Unable to continue with install: Service "proxy-extauthz" in namespace "knox" exists and cannot be imported into the current release: invalid ownership metadata; annotation validation error: key "meta.helm.sh/release-name" must equal "cml-serving": current value is "knox"; annotation validation error: key "meta.helm.sh/release-namespace" must equal "cml-serving": current value is "knox"Workaround: Downgrade the Knox add-on version in Compute cluster and retry the installation:
-
Navigate to the Cloudera AI Inference service Application details page.
-
Click the link for the Compute Cluster associated with the setup.
-
Select the Add-ons tab.
-
Locate the Knox add-on and downgrade the version from 3.0.0-dsp3 to 2.0.2-dsp1.
-
Return to the application setup and retry the installation.
Knox add-on uninstallation during Compute Cluster upgrade (DSE-50986)
In Cloudera AI Inference service version 1.8.0-x, attempting to
upgrade the compute cluster or manually upgrading the Knox add-on results in the unintended
uninstallation of the Knox add-on.
This issue causes authentication failures for all existing workloads, including
applications and model endpoints residing in the cluster. Do not perform compute
cluster upgrades on Cloudera AI Inference service version 1.8.0-x
instances until further notice.
Workaround: If an upgrade has already been performed and the cluster is in a broken state, you must recreate the Cloudera AI Inference service instance and redeploy the models from the Cloudera AI Registry.
Limited GPU support for Boltz2 Runtime (DSE-48889)
The new Boltz2 Runtime, upgraded to version 1.3.0, currently only supports deployments configured with a single NVIDIA L40S GPU (1xL40S). Attempting to deploy this runtime on other GPU types (for example, A100, V100) or configurations with multiple L40S GPUs will result in deployment or execution failures.
Additionally, to ensure proper function with the new runtime, the environment variable
NIM_MAX_POLYMER_LENGTH has been set to the value of
1536.
Permission denied error on new Model Endpoint Details page (DSE-50255)
Immediately following the creation of a Model Endpoint, the UI automatically redirects to the Model Endpoint Details page. During this transition, you may encounter a Permission Denied error message despite having the correct access rights.
Workaround: If you encounter this error, wait a few seconds and then refresh your browser page. The Details page should load correctly without further intervention.
AI Registry model import failure behind proxy (NTP Setup) (DSE-48642)
When Cloudera AI Registry is deployed within an NTP (Non-Transparent Proxy) setup, attempts
to import models from Model Hub (such as NVIDIA or Hugging Face) may fail with a 401
Unauthorized error. This occurs because the Knox service, which gates the
Cloudera AI Registry, does not honor the HTTPS_PROXY environment variable, preventing
successful communication with the Control Plane API over the proxy.
- Retrieve proxy details and construct the string:
-
Go to your environment page where the AI Registry is deployed.
-
In Summary, go to the Proxy section.
-
Click on the Proxy value to view the Server Host and Server Port. Take note of these two values.
-
Use the collected proxy details to create the following string:
-Dhttps.proxyHost=<Server Host> -Dhttps.proxyPort=<Server Port>For Example:Dhttps.proxyHost=10.80.123.45 -Dhttps.proxyPort=6789
-
- Edit the knox deployment and append the Proxy string:
-
Get the
kubeconfigof your AI Registry. -
Run the following command to edit the Knox deployment:
kubectl edit deployment knox -n knox -
Search for the environmentVariable
KNOX_GATEWAY_DBG_OPTSin that deployments file. -
Append the string you created to the value of
KNOX_GATEWAY_DBG_OPTS. It is highly recommended to enclose the entire value in double quotes.For example, if original value was-Dcom.sun.jndi.ldap.object.disableEndpointIdentification=true, then the string would be:"Dhttps.proxyHost=10.80.123.45 -Dhttps.proxyPort=6789 -Dcom.sun.jndi.ldap.object.disableEndpointIdentification=true" -
Save the changes to the deployment. This action automatically restarts the Knox pod.
-
Verify if the new pod is running:
kubectl get pods -n knox - Restart model-registry-v2
pods:
kubectl rollout restart deployment model-registry-v2 -n mlx -
Once the new pod is up, attempt to import the model from NVIDIA or Hugging Face again. The import should now succeed.
-
User or Team Sync status in UI does not update in real-time after sync trigger (DSE-43688)
After triggering a user or team sync, the sync status in the UI does not update instantly. Instead, it is refreshed based on a 30-second polling interval, causing a delay before the updated sync status is displayed in the UI.
Resource Group selection not visible without GPU profile (DSE-48683)
When editing or redeploying an existing workload (Job, Application, or Model), the Resource Group that was previously selected is not displayed. This display issue affects all workloads when the workbench does not have a GPU Resource Group configured in the Control Plane. The selected values are still active but are not loaded or visible in the UI edit screens.
Workaround: An Administrator must configure at least one GPU Resource Group for the workbench on the Control Plane. Once a GPU profile exists, the correct Resource Group values will be loaded and displayed in the workload edit screens.
Session Timeout (SESSION_MAXIMUM_MINUTES) does not stop specific Runtime sessions (DSE-47697)
- JupyterLab Editor: The session is running with the JupyterLab Editor and if the Runtime is from the Runtime release 2025.01.1 or later.
- PBJ Custom Runtime: The session is running with a PBJ Custom Runtime that utilizes a custom editor.
Events and Logs unavailable for Cloudera AI Registry (DSE-47205)
Events and Logs information is not displayed in the UI for a fresh installation of Cloudera AI Registry. However, logs for other events, such as Upgrade and Renew, are displayed correctly.
JWT token not refreshing before expiry in Cloudera AI Workbench (DSE-41395)
In the Cloudera AI Workbench, the JSON Web Token (JWT) does not automatically refresh before the existing token expires. This can lead to unexpected session interruptions and connection failures when using the workbench.
- Navigate to the environment where your workbench is provisioned.
- Go to Environment Details → Datalake → Cloudera Manager UI → knox.
- Find the setting named knox_token_kerberos_ttl_ms.
- It is recommended to set the value of this setting to a number larger than 20 minutes (1,200,000 milliseconds).
- After setting the new value, restart the Knox service for the change to take effect.
Resource profiles are not automatically updated after an instance type change (DSE-47568)
If an administrator modifies the instance type of a Resource Group, the associated Resource Profiles will not automatically reflect the new instance capacity.
Modifying the Persistent Volume size fails in private cluster (DSE-46334)
Helm upgrade failure: another
operation is in progress error, even if the UI appears updated.Sessions stuck in Scheduling state (DSE-48087)
After launching a new Session, the browser interface may intermittently get stuck in the Scheduling state. This prevents the Session from starting automatically.
- (Immediate) Refresh the page in your browser to immediately unstick the Session and allow it to finish launching.
- (Permanent) An administrator can permanently resolve this issue by restarting the web pods in the Kubernetes cluster.
Cloudera AI Workbench upgrade intermittently fails (DSE-46502)
Status: Upgrade Failed
failed to execute post-upgrade processes: failed to scale up nodes: failed to scale up nodes: rpc error: code = Internal desc = A workbench update is currently in progress please try again laterWorkaround: If you encounter this issue, use the Retry Upgrade Workbench option in the Cloudera AI UI to restart the upgrade workflow.
Upgrade of Cloudera AI Registry in Azure with UDR-enabled subnet fails with subnet error (DSE-46225)
Cloudera AI is not selecting the correct subnet when upgrading the Cloudera AI Registry, which causes the upgrade to fail.
Workaround: Migrate your Cloudera AI Registry database. The following steps are required to migrate your Cloudera AI Registry database, which includes generating a database dump from an existing instance and restoring it to a new AI Registry.
- Obtain the kubeconfig file for your Cloudera AI Registry using the following steps:
- In the Cloudera console,
click the Cloudera AI tile.
The Cloudera AI Workbenches page displays.
- Click AI Registries under
Administration on the left navigation menu.
The AI Registries page displays.
- In the AI Registries page,
click
 in the
Actions column.
in the
Actions column. - Click Download Kubeconfig.
- In the Cloudera console,
click the Cloudera AI tile.
- Access the database pod of your existing Cloudera AI Registry
instance.
kubectl exec -it model-registry-db-0 -n mlx -- bash - Connect to the PostgreSQL sense database and verify the schema migration
status.
psql -U sense \c sense \dtA successful schema migration will display a list of relations similar to the following:List of relations Schema | Name | Type | Owner --------+----------------------+-------+------- public | config | table | sense public | model_permissions | table | sense public | model_registry_users | table | sense public | model_versions | table | sense public | models | table | sense public | schema_migrations | table | sense public | tags | table | sense - Generate database dump. The type of database dump you generate depends on whether the
schema migration is complete.
-
If the schema migration is confirmed (output matches the example above), generate a data-only dump of the sense database:
pg_dump -U sense --data-only sense > /tmp/dump.sql -
If the output differs (schema migration is not complete), generate a full database dump:
pg_dump -U sense sense > /tmp/dump.sql
-
- Copy the generated dump file from your local machine to the new Cloudera AI Registry database
pod:
kubectl cp mlx/model-registry-db-0:/tmp/dump1.sql ./dump1.sql -
Set up the new environment for data restoration.
-
Delete the old Cloudera AI Registry, as you can only have one Cloudera AI Registry in any given environment.
-
Create a new Cloudera AI Registry instance. For information on creating an AI Registry in an Azure subnet with UDR, see Creating a Cloudera AI Registry on an Azure UDR Private Cluster.
-
Configure
kubectlto point to thekubeconfigof the newly created Cloudera AI Registry.
-
- Once the new Cloudera AI Registry is set up, copy the
dump.sql file from your local machine to the new Cloudera AI Registry database
pod:
kubectl cp <abs path of dump.sql> model-registry-db-0:/tmp/ -n mlx - Restore the database within the new Cloudera AI Registry pod.
- Execute into the new Cloudera AI Registry database
pod:
kubectl exec -it model-registry-db-0 -n mlx -- bash - Verify the presence of the dump file inside the /tmp/ directory
of the new pod:
ls /tmp/dump.sql - Run the command to restore the database by applying the dump to the
sensedatabase:psql -U sense sense < /tmp/dump.sql
- Execute into the new Cloudera AI Registry database
pod:
When opening a Cloudera AI Workbench from the Control Plane for the first time, it might take five or more minutes to load. (DSE-41691)
This is caused by a known issue where the code for Cloudera AI Workbench checks to see that the Data Lake is available and online. If the Data Lake is not in the Ready (green) status, then this code will prevent the Cloudera AI Workbench from loading.
Workaround: Ensure that every node in the Data Lake is running completely and upgrade to the latest version of Cloudera AI.
Unable to deploy ONNX optimization profiles for embedding and ranking NIMs on GPUs with optimization profiles (DSE-40509)
Deploying ONNX profiles for embedding and ranking NIMs on GPUs where compatible GPU profiles exist will lead to deployment failure. Before deploying an ONNX optimization profile for embedding or ranking NIMs from the Model Hub, ensure that the NIM does not have a supported profile for the target GPU.
Cloudera AI does not support non-transparent proxy with authentication (DSE-36512)
Cloudera AI on cloud does not support non-transparent proxy with authentication. While configuring proxy using the Cloudera console, do not specify your username and password.
Unable to paginate in Cloudera AI Workbench backup table (DSE-41406)
When selecting a backup in the Workbench backup table, pagination to the next page does not work as expected. This is due to an issue in the cuix library.
Workaround: To avoid the issue, do not try to navigate to the next page after selecting a backup. Instead, refresh the page to view details of other Workbench backups.
Too many Federated Identity Credentials have been assigned to the Managed Identity. error is displayed in the Event Log file (DSE-41063)
Each Azure managed identity, that is, Logger Identity in a Cloudera environment can have a maximum of 20 federated identity credentials. Because each cluster requires 1–2 federated identities, there is a maximum number of clusters that can be created per environment. If you exceed the maximum number of clusters, Too many Federated Identity Credentials have been assigned to the Managed Identity." error is displayed.
- Log into the Microsoft Azure portal.
- Go to Managed Identity and select the logger identity you defined of your resource group.
- Click > .
- In the Federated Credentials page, delete the unused federated identity credentials (with no AKS cluster associated with it).
Cloudera AI automatic JWT authorization to Cloudera Data Warehouse is failing due to a wrong KNOX URL (DSE-39855)
Due to an issue, there is a mismatch of the Data Lake name between the actual Data Lake name in the environment and the one parsed by the CML 2.0.43-b208 version or later.
- Obtain the correct Data Lake version by running the following command using CDP
CLI:
cdp datalake describe-datalake - Override the KNOX URL in the environment variable by performing the following:
- Run the following command to save the deployment status to a
file:
kubectl get deployment ds-cdh-client -o json -n mlx > /tmp/rs.json - Edit the /tmp/rs.json file and add the below object for
ds-cdh-client environment under the
spec.template.spec.containers.env
section.
{ "name": "FIXED_KNOX_URL", "value": "https://[***ENVIRONMENT-VARIABLE***]/value" } - Apply the
configuration.
kubectl apply -f /tmp/rs.json
- Run the following command to save the deployment status to a
file:
Python workloads running multiple-line comments or strings fail (DSE-41757)
Python workloads running multiple-line comments or strings might fail to run when using the Workbench Editor..
Workaround: Run the code using the PBJ Workbench Editor.
Web pod crashes if a project forking takes more than 60 minutes (DSE-35251)
2024-04-23 22:52:36.384 1737 ERROR AppServer.VFS.grpc crossCopy grpc error data = [{"error":"1"},{"code":4,"details":"2","metadata":"3"},"Deadline exceeded",{}]
["Error: 4 DEADLINE_EXCEEDED: Deadline exceeded\n at callErrorFromStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/call.js:31:19)\n at Object.onReceiveStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client.js:192:76)\n at Object.onReceiveStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client-interceptors.js:360:141)\n at Object.onReceiveStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client-interceptors.js:323:181)\n at /home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/resolving-call.js:94:78\n at process.processTicksAndRejections (node:internal/process/task_queues:77:11)\nfor call at\n at ServiceClientImpl.makeUnaryRequest (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client.js:160:34)\n at ServiceClientImpl.crossCopy (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/make-client.js:105:19)\n at /home/cdswint/services/web/server-dist/grpc/vfs-client.js:235:19\n at new Promise (<anonymous>)\n at Object.crossCopy (/home/cdswint/services/web/server-dist/grpc/vfs-client.js:234:12)\n at Object.crossCopy (/home/cdswint/services/web/server-dist/models/vfs.js:280:38)\n at projectForkAsyncWrapper (/home/cdswint/services/web/server-dist/models/projects/projects-create.js:229:19)"]
node:internal/process/promises:288
triggerUncaughtException(err, true /* fromPromise */);
^Error: 4 DEADLINE_EXCEEDED: Deadline exceeded
at callErrorFromStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/call.js:31:19)
at Object.onReceiveStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client.js:192:76)
at Object.onReceiveStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client-interceptors.js:360:141)
at Object.onReceiveStatus (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client-interceptors.js:323:181)
at /home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/resolving-call.js:94:78
at process.processTicksAndRejections (node:internal/process/task_queues:77:11)
for call at
at ServiceClientImpl.makeUnaryRequest (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/client.js:160:34)
at ServiceClientImpl.crossCopy (/home/cdswint/services/web/node_modules/@grpc/grpc-js/build/src/make-client.js:105:19)
at /home/cdswint/services/web/server-dist/grpc/vfs-client.js:235:19
at new Promise (<anonymous>)
at Object.crossCopy (/home/cdswint/services/web/server-dist/grpc/vfs-client.js:234:12)
at Object.crossCopy (/home/cdswint/services/web/server-dist/models/vfs.js:280:38)
at projectForkAsyncWrapper (/home/cdswint/services/web/server-dist/models/projects/projects-create.js:229:19) {
code: 4,
details: 'Deadline exceeded',
metadata: Metadata { internalRepr: Map(0) {}, options: {} }
} UPDATE site_config SET grpc_git_clone_timeout_minutes = <new value>; Enabling Service Accounts (DSE-32943)
Teams in the Cloudera AI Workbench can only run workloads within team projects with the Run as option for service accounts if they have previously manually added service accounts as a collaborator to the team.
Working with files larger than 1 MB in Jupyter causes error (OPSAPS-61524)
While working on files or saving files of size larger than 1 MB, Jupyter Notebook may display an error message such as 413 Request Entity Too Large.
Workaround:
Clean up the notebook cell results often to keep the notebook below 1 MB. Use the
kubectl CLI to add the following annotation to the ingress corresponding
to the session.
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: "0"- Get the session ID (the alphanumeric suffix in the URL) from the web UI.
- Get the corresponding namespace:
kubectl get pods -A | grep <session ID> - List the ingress in the namespace
kubectl get ingress -n <user-namespace> | grep <session ID> - In the metadata, add the annotation.
kubectl edit ingress <ingress corresponding to the session> -n <user-namespace>
Terminal does not stop after time-out (DSE-12064)
After a web session times out, the terminal should stop running, but it remaings functional.
Cloudera AI Workbench upgrades disabled with NTP
Upgrades are disabled for Cloudera AI Workbench configured with non-transparent proxy (NTP). This issue is anticipated to be fixed in a subsequent hotfix release.
Using dollar character in environment variables in Cloudera AI
Environment variables with the dollar ($) character are not parsed correctly by Cloudera AI. For example, if you set PASSWORD="pass$123" in the project environment
variables, and then try to read it using the echo command, the following output will be
displayed: pass23
echo 24 | xxd -r -p
or
echo JAo= | base64 -d$() or ``. For example, if you want to set the
environment variable to ABC$123,
specify:ABC$(echo 24 | xxd -r -p)123
or
ABC`echo 24 | xxd -r -p`123Models: Some API endpoints not fully supported
In the create_run api, run_name is not supported.
Also, search_experiments only supports pagination.
When a team added as a collaborator, it does not appear in the UI. (DSE-31570)
Run Job as displays even if the job is enabled on a service account. (DSE-31573)
If the job is enabled on a service account, the Run Job as option should not display. Even if me is selected at this point, the job still runs in the service account.
AMP archive upload fails if Project does not contain metadata YAML file
- Download the AMP zip file from GitHub
- Unzip it to a temp directory
- From the command line navigate to the root directory of the zip
- Run this command to create the new zip file:
zip -r amp.zip.
Make sure you see the .project-metadata/yaml in the root of the zip file.
Cloning from Git using SSH is not supported via HTTP proxy
Workaround: Cloudera AI Projects support HTTPS for cloning git projects. It is suggested to use this as the workaround.
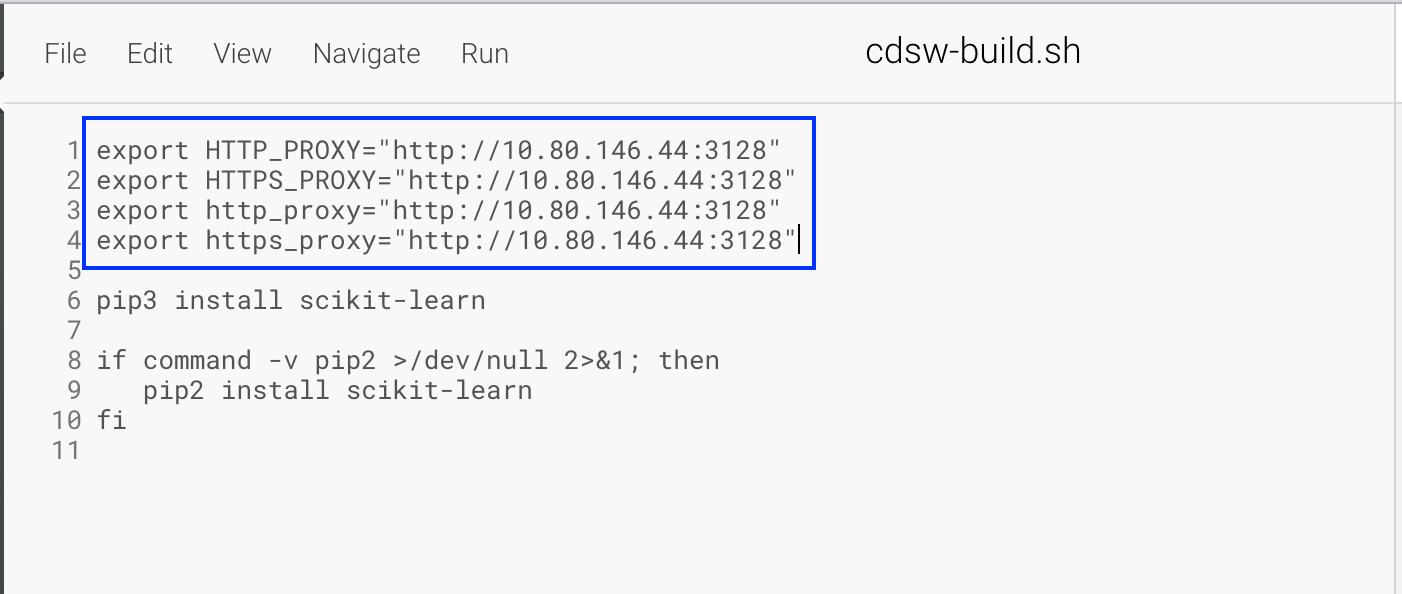
Model deployments requiring outbound access via proxy do not honor HTTP_PROXY, HTTPS_PROXY environment variables
Workaround: Add the HTTP_PROXY, HTTPS_PROXY, http_proxy and https_proxy environment variables to the cdsw-build.sh file of the Project Repository.
Application does not restart after upgrade or migration
An application may fail to automatically restart after a workbench upgrade or migration. In this case, manually restart the application.
Do not use backtick characters in environment variable names
Avoid using backtick characters ( ` ) in environment variable names, as
this will cause sessions to fail with exit code 2.
Cloudera AI Registry is not supported on R models
Cloudera AI Registry is not supported on R models.
The mlflow.log_model registered model files might not be available on NFS Server (DSE-27709)
When using mlflow.log_model, registered model files might not be available on the NFS server due to NFS server settings or network connections. This could cause the model to remain in the registering status.
- Re-register the model. It will register as an additional version, but it should correct the problem.
- Add the ARTIFACT_SYNC_PERIOD environment variable to hdfscli-server Kubernetes deployment and set it to an integer value. This will set the Cloudera AI Registry retry operation to twice the number of seconds specified by the artifact sync period integer value. If the ARTIFACT_SYNC_PERIOD is set to 30 seconds then Cloudera AI Registry will retry for 60 seconds. The default value is 10 and Cloudera AI Registry retries for 20 seconds. For example: -name: ARTIFACT_SYNC_PERIOD value: “30”.
Applications appear in failed state after upgrade (DSE-23330)
After upgrading Cloudera AI from version 1.29.0 on AWS, some applications may be in a Failed state. The workaround is to restart the application.
Cannot use hashtag character in JDBC connection string
The special character # (hashtag) cannot be used in a password that is
then used in a JDBC connection string. Avoid using this special character, or use
'%23' instead.
Cloudera AI Workbench installation fails
Cloudera AI Workbench installation with Azure NetApp Files on NFS v4.1 fails. The workaround is to use NFS v3.
Spark executors fail due to insufficient disk space
Generally, the administrator should estimate the shuffle data set size before provisioning the workbench, and then specify the root volume size of the compute node that is appropriate given that estimate. For more specific guidelines, see the following resources.
Runtime Addon fails to load (DSE-16200)
A Spark runtime add-on may fail when upgrading a workbench.
Solution: To resolve this problem, try to reload the add-on. In , in the option menu next to the failed add-on, select Reload.
Cloudera AI Workbench provisioning times out
When provisioning a Cloudera AI Workbench, the process may time out with
an error similar to Warning FailedMount or Failed to sync secret
cache:timed out waiting for the condition. This can happen on AWS or Azure.
Solution: Delete the workbench and retry provisioning.
Cloudera AI endpoint connectivity from Cloudera Data Hub and Cloudera Data Engineering (DSE-14882)
When Cloudera services connect to Cloudera AI services, if the Cloudera AI Workbench is provisioned on a public subnet, traffic is routed out of the VPC first, and then routed back in. On Cloudera on premises Cloudera AI, traffic is not routed externally.
NFS performance issues on AWS EFS (DSE-12404)
Cloudera AI uses NFS as the filesystem for storing application and user data. NFS performance may be much slower than expected in situations where a data scientist writes a very large number (typically in the thousands) of small files. Example tasks include: using git clone to clone a very large source repository (such as TensorFlow), or using pip to install a Python package that includes JavaScript code (such as plotly). Reduced performance is particularly common with Cloudera AI on AWS (which uses EFS), but it may be seen in other environments.
Disable file upload and download (DSE-12065)
You cannot disable file upload and download when using the Jupyter Notebook.
Remove Workbench operation fails (DSE-8834)
Remove Workbench operation fails if workbench creation is still in progress.
API does not enforce a maximum number of nodes for Cloudera AI Workbench
When the API is used to provision new Cloudera AI Workbench, it does not enforce an upper limit on the autoscale range.
Downscaling Cloudera AI Workbench nodes does not work as expected (MLX-637, MLX-638)
Downscaling nodes does not work as seamlessly as expected due to a lack of Bin Packing on
the Spark default scheduler, and because dynamic allocation is not currently enabled. As a
result, currently infrastructure pods, Spark driver/executor pods, and session pods are
tagged as non-evictable using the cluster-autoscaler.kubernetes.io/safe-to-evict:
"false" annotation.
First time user synchronization adds ML user as the default role to the already synced users (DSE-42775)
When you perform user synchronization, by default, the newly added users are designated as
ML User. This behavior applies to all users who are newly added and
synced to CML from CML2.0.47-b359 or in CML2.0.47-b360 releases.
Workaround: You must perform user synchronization once again to display the actual or designated roles.
Disable auto synchronization feature for users and teams (DSE-36718)
The automated team and user synchronization feature is disabled. Newly installed or upgraded workbenches do not have the automatic synchronization option in the Cloudera AI UI.
Cloudera AI workload sessions will not be created using password-protected SSH key (DSE-42698)
Impacted users will not be able to start workloads or clone private github accounts. Cloudera recommends upgrading the Workbench to version the CML2.0.47-b360 on priority.
This issue impacts following set of users:
- Newly added users synced to a freshly created Cloudera AI Workbench version CML2.0.47-b359.
- Users added and synced to Cloudera AI Workbench version CML2.0.47-b359, later upgraded to version CML2.0.47-b360 (using in-place or backup-restore upgrades).
- Users added after upgrading Cloudera AI Workbench to version CML2.0.47-b359 from an earlier version.
- Users can rotate their own SSH keys individually by logging into Cloudera AI Workbench UI > select User Settings → select the Outbound SSH tab → click Reset SSH Key button.
- If the Workbench is upgraded to CML 2.0.47-b360 from CML
2.0.47-b359, run the
mitigation.shscript only once.
While using CML 2.0.47-b359 version, the administrator has to run the
mitigation.sh script after synchronizing each user or team operation.
You must run the mitigation.sh script providing the
namespace, kubeconfig, and
db-reset-ssh-pass-keys.sh script as arguments.
- On your local system, copy and paste both of the code snippets to
mitigation.shanddb-reset-ssh-pass-keys.shrespectively.Copy the following code todb-reset-ssh-pass-keys.shscript:#!/bin/bash # This script must be run inside of web pod in mlx namespace by getting a k8s exec shell into that pod # Detects if a private key is inappropriately password protected and rotates it for a new one # This should be executed as often as user sync is performed to fix ssh keys for any newly synced users export PGPASSWORD=$POSTGRESQL_PASS query="psql -h db.mlx.svc.cluster.local -U $POSTGRESQL_USER -qAtX -c" USERS_ID_LIST=$($query "select id from users;") touch /tmp/existing-priv-key chmod 0700 /tmp/existing-priv-key while IFS= read -r user_id do $query "select private_key from public.ssh_keys where id=$user_id;" > /tmp/existing-priv-key ssh-keygen -y -P "" -f /tmp/existing-priv-key &> /dev/null if [ $? -ne 0 ]; then echo "Detected passphrase protected SSH key for User $user_id" rm -f /tmp/new-priv-key rm -f /tmp/new-priv-key.pub ssh-keygen -f /tmp/new-priv-key -b 2048 -C cdsw -q -N "" priv_key=`cat /tmp/new-priv-key` pub_key=`cat /tmp/new-priv-key.pub` $query "update public.ssh_keys set private_key='$priv_key', public_key='$pub_key' where id=$user_id" echo "Rotated SSH key for User $user_id" fi done <<< $USERS_ID_LIST rm -f /tmp/new-priv-key rm -f /tmp/new-priv-key.pub rm -f /tmp/existing-priv-keyCopy the following code tomitigation.shscript:#!/bin/bash # ### Usage: ./mitigation.sh <namespace> <kubeconfig> <file_to_copy_and_run> # ex: ./mitigation.sh mlx /root/configs/ums.conf db-reset-only-pass-ssh.sh # Input arguments NAMESPACE=$1 KUBECONFIG=$2 FILE_TO_COPY_AND_RUN=$3 # Check if required arguments are provided if [ -z "$NAMESPACE" ] || [ -z "$KUBECONFIG" ] || [ -z "$FILE_TO_COPY_AND_RUN" ]; then echo "✘ Error: Missing required arguments." echo "Usage: $0 <namespace> <kubeconfig> <file_to_copy_and_run>" exit 1 fi # Ensure kubectl is using the provided kubeconfig export KUBECONFIG=$KUBECONFIG # Get the name of the pod under the 'web' deployment in the specified namespace POD_NAME=$(kubectl get pods -n $NAMESPACE -l app=web -o jsonpath='{.items[0].metadata.name}' --kubeconfig=$KUBECONFIG) if [ -z "$POD_NAME" ]; then echo "✘ Error: No pod found for the 'web' deployment in the namespace $NAMESPACE." exit 1 fi echo "✔ Found pod: $POD_NAME" # Copy the file to the pod kubectl cp $FILE_TO_COPY_AND_RUN $NAMESPACE/$POD_NAME:/tmp/$(basename $FILE_TO_COPY_AND_RUN) --kubeconfig=$KUBECONFIG # Check if the file copy was successful if [ $? -ne 0 ]; then echo "✘ Error: Failed to copy file $FILE_TO_COPY_AND_RUN to pod $POD_NAME." exit 1 fi echo "✔ File copied to pod successfully." # Run the script inside the pod kubectl exec -n $NAMESPACE $POD_NAME -- /bin/bash /tmp/$(basename $FILE_TO_COPY_AND_RUN) --kubeconfig=$KUBECONFIG # Check if the script execution was successful if [ $? -ne 0 ]; then echo "✘ Error: Failed to execute the script inside the pod." exit 1 fi echo "✔ Script executed successfully inside the pod." - Download the Cloudera AI cluster's kubeconfig. For more details see Granting remote access to Cloudera AI Workbenches.
Run the
./mitigation.shscript as follows:./mitigation.sh <cml-namespace> <kubeconfig-path> db-reset-ssh-pass-keys.sh
Cloudera AI Inference service Known issues
- DSE-48604: When the Access Control feature is enabled on
the Cloudera AI Inference service Details page, you can encounter two related
issues:
- The list of currently deployed endpoints is not visible.
- The UI slider/toggle does not immediately refresh its state after enabling or disabling the feature.
- DSE-48399: Clicking the Swagger UI link on the Cloudera AI Inference
service Details page incorrectly results in an
HTTP ERROR 401 Unauthorizederror instead of displaying the documentation. This is caused by a missing trailing slash in the URL generated by the link.Workaround: After clicking the link and seeing the error, manually append a trailing slash (/) to the end of the URL in your browser's address bar and reload the page. The Swagger UI should then load correctly.
- DSE-48145: The Boltz2 NIM model server does not publish Prometheus metrics starting in Cloudera AI version 2.0.52-b60. Consequently, the charts in the Metrics tab on the Model Endpoint Details page will not display any data for Boltz2 models.
- The following compute instance types are not supported by Cloudera AI Inference service:
- Azure: NVadsA10_v5 series.
- AWS: p4d.24xlarge
- DSE-39826: Running the
modify-ml-serving-appcommand on Cloudera AI Inference service Azure clusters in theus-west-2workload region fails. When this occurs, the status of the application is incorrectly displayed asmodify:failed.Workaround: You must first delete the instance group you want to modify using the delete-instance-group-ml-serving-app API. Then, recreate the instance group, modify the configuration based on your requirements, and add the instance group using the add-instance-groups-ml-serving-app API.
- Unclean deletion of Cloudera AI Inference service version 1.2.0 and older. If you delete Cloudera AI Inference service version 1.2.0 or older, some Kubernetes resources are left in the cluster and causes a subsequent creation of Cloudera AI Inference service on the same cluster to fail. It is recommended that you delete the Compute cluster and recreate it to deploy Cloudera AI Inference service on it.
- Graceful deletion of Cloudera AI Inference service version older than
1.3.0-b111 fails. A new feature introduced in version 1.3.0-b111 has caused a regression
where graceful deletion of an existing Cloudera AI Inference service version
1.2.0 fails. Workaround: Use the CDP CLI version 0.9.131 or higher to forcefully delete Cloudera AI Inference service.Cloudera recommends that after a forceful deletion of Cloudera AI Inference service, you delete the underlying compute cluster as well to ensure that all resources are cleaned up properly.
cdp ml delete-ml-serving-app --app-crn [***APP_CRN***] --force - Updating the description after a model has been added to a model endpoint will lead to a UI mismatch in the model builder for models listed by the model builder and the models deployed.
- When you create a model endpoint from the Create Endpoint page, even though the instance type selection is not mandatory, the endpoint creation fails if the instance type is not selected.
- DSE-39626: If no worker node can be found within 60 minutes to schedule a model endpoint that is either newly created or is scaling up from 0, the system will give up trying to create and schedule the replica. A common reason for this behavior is insufficient cloud quota, or capacity constraints on the cloud service provider’s side. You could either ask for increased quota, or try to use an instance type that is more readily available.
- When updating an Model Endpoint with a specific GPU requirement, the instance type must
be explicitly set again even if there is no change.
- To bring up the endpoint after a revision is failed, the endpoint configuration needs to be updated. This can be achieved currently in the form of an autoscale range change, or resource requirements change.
- When updating an endpoint with a specific GPU requirement, the instance type must be explicitly set again even if there is no change.
- Embedding models function in two modes:
queryorpassage. This has to be specified when interacting with the models. There are two ways to do this:-
suffix the model id in the payload by either
-queryor-passageor -
specify the
input_typeparameter in the request payload.For more information, see NVIDIA documentation.
-
-
Embedding models only accept strings as input. Token stream input is currently not supported.
-
Llama 3.2 Vision models are not supported on AWS on A10G and L40S GPUs.
-
Llama 3.1 70B Instruct model L40S profile needs 8 GPUs to deploy successfully, while Nvidia documentation lists this model profile as needing only 4 L40S GPUs.
-
Model Runtimes have been changed in a non-backward compatible way between Cloudera AI Inference service version 1.2 and 1.3. Therefore, NIM model endpoints deployed in version 1.2 need to be redeployed by downloading their profiles again through Model Hub and creating a new endpoint from the most recent version of the model in the Cloudera AI Registry.
-
You cannot upgrade from Cloudera AI Inference service version 1.3.0-b111 to higher. You must first delete the service and recreate it to deploy version 1.3.0-b113 or higher.
-
Hugging Face model deployment fails in Cloudera AI Inference service 1.3.0-b114.
-
DSE-42519: Specifying subnets for load balancer from the UI when creating Cloudera AI Inference service does not work. The specified subnets are accepted by the UI, but these settings are not actually applied to the load balancer service created in the cluster.
Workaround: Use CDP CLI to specify subnets for the load balancer.
Limitations
- Cloudera AI Inference service and Cloudera AI Registry are not supported on Azure East Asia and Qatar Central regions
-
Cloudera AI Inference service and Cloudera AI Registry are not supported on Microsoft Azure East Asia and Qatar Central regions due to lack of support for Workload Identity by Microsoft Azure.
Technical Service Bulletins
- TSB 2026-960 (Security): Remediation and Mitigation Actions: Linux Kernel Vulnerabilities – Copy Fail, Dirty Frag, and Fragnesia
-
Cloudera has evaluated the impact of the recently disclosed Linux kernel vulnerabilities. This Technical Service Bulletin describes the affected deployment scenarios and provides remediation and mitigation guidance.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2026-960 (Security): Remediation and Mitigation Actions: Linux Kernel Vulnerabilities – Copy Fail, Dirty Frag, and Fragnesia .
- TSB 2025-844: Garbage collection for pods in Error or Stuck states in Cloudera AI on cloud is not working in Cloudera AI
-
In certain (older) versions of Cloudera AI on cloud, garbage collection of pods in states such as Error and Init:Unknown inside Cloudera AI Workbenches is not occurring. This can prevent the deployment of new pods and lead to unnecessary cloud costs for stale workload pods no longer serving any purpose.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2025-844: Garbage collection for pods in Error or Stuck states in Cloudera AI on cloud is not working .
- TSB 2025-826: Non-authorized users can perform CRUD operations in Cloudera AI
-
Non-authorized but authenticated users can carry out CRUD operations on Cloudera AI Registry metadata tables. This includes the ability to update/delete existing metadata of models, model-versions, and tags tables. This can allow them to update permissions in the metadata to in turn access existing model artifacts that are stored in S3 or Azure Blob Storage.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2025-826: Non-authorized users can perform CRUD operations in Cloudera AI
- TSB 2024-761: Orphan EBS Volumes in Cloudera AI Workbench
-
Cloudera AI provisions Elastic Block Store (EBS) volumes during provisioning of a workbench. Due to missing labels on Cloudera AI Workbench, delete operations on previously restored Cloudera AI Workbench didn’t clean up a subset of the provisioned block volumes.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB 2024-761: Orphan EBS Volumes in Cloudera AI Workbench
- TSB 2023-628: Sensitive user data getting collected in Cloudera AI Workbench or CDSW workbench diagnostic bundles
-
When using Cloudera Data Science Workbench (CDSW), Cloudera recommends users to store sensitive information, such as passwords or access keys, in environment variables rather than in the code. See Engine Environment Variables in the official Cloudera documentation for details. Cloudera recently learned that all session environment variables in the affected releases of CDSW and Cloudera AI are logged in web pod logs, which may be included in support diagnostic bundles sent to Cloudera as part of support tickets.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB-2023-628: Sensitive user data getting collected in Cloudera AI Workbench or in CDSW workbench diagnostic bundles
- TSB 2022-588: Kubeconfig and new version of aws-iam-authenticator
-
Regenerate Kubeconfig and in conjunction use a newer version of aws-iam-authenticator on AWS. Kubeconfig in Cloudera Cloudera on cloud Data Services needs to be regenerated because the Kubeconfig generated before June 15, 2022 uses an old APIVersion (client.authentication.k8s.io/v1alpha1) which is no longer supported. This causes compatibility issues with aws-iam-authenticator starting from v0.5.7. To be able to use the new aws-iam-authenticator, the Kubeconfig needs to be regenerated.
- Knowledge article
- For the latest update on this issue see the corresponding Knowledge article: TSB-2022-588: Kubeconfig and new version of aws-iam-authenticator