Creating and deploying a Model
Using Cloudera AI, you can create any function within a script and deploy it to a REST API. In a Cloudera AI project, this is typically a predict function that accepts an input and returns a prediction based on the model's parameters.
Using Cloudera AI, you can create any function within a script and deploy it to a REST API. In a machine learning project, this will typically be a predict function that will accept an input and return a prediction based on the model's parameters.
For the purpose of this quick start demo we are going to create a very simple function that adds two numbers and deploy it as a model that returns the sum of the numbers. This function will accept two numbers in JSON format as input and return the sum.
- Create a new project. Note that models are always created within the context of a project.
- Click New Session and launch a new Python 3 session.
- Create a new file within the project called
add_numbers.py. This is the file where we define the function that will be called when the model is run. For example:add_numbers.py
import cml.models_v1 as models @models.cml_model def add(args): result = args["a"] + args["b"] return result -
Before deploying the model, test it by running the
add_numbers.pyscript, and then calling theaddfunction directly from the interactive workbench session. For example:add({"a": 3, "b": 5})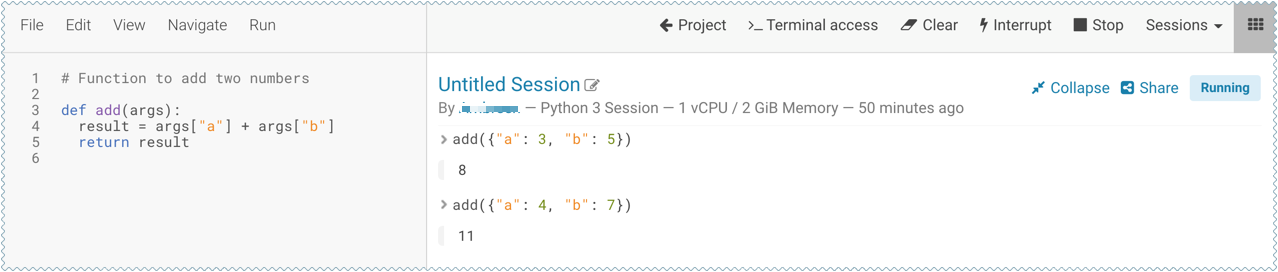
- Deploy the
addfunction to a REST endpoint.- Go to the project Overview page.
- Click .
- Give the model a Name and Description.
- In Deploy Model as, if the model is to be deployed in a service account, select Service Account and choose the account from the dropdown menu.
-
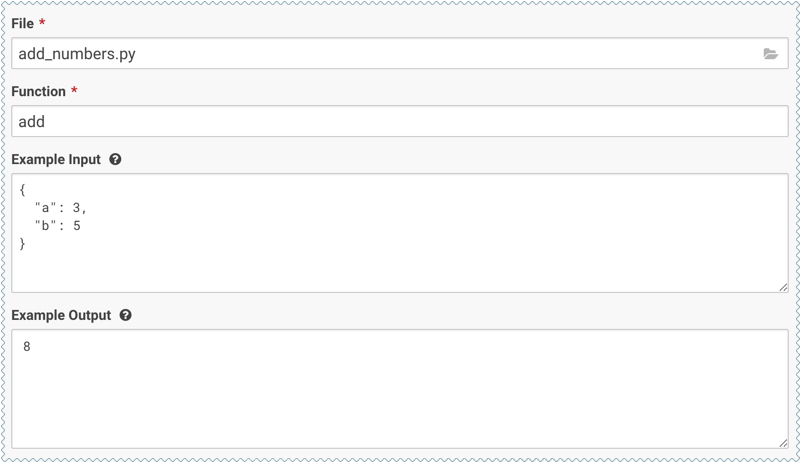
Enter details about the model that you want to build. In this case:
- File: add_numbers.py
- Function: add
- Example Input: {"a": 3, "b": 5}
- Example Output: 8
- Select the resources needed to run this model, including any replicas for load
balancing. To specify the maximum number of replicas in a model
deployment, go to . The default is 9 replicas, and up to 199 can be set.
- Click Deploy Model.
-
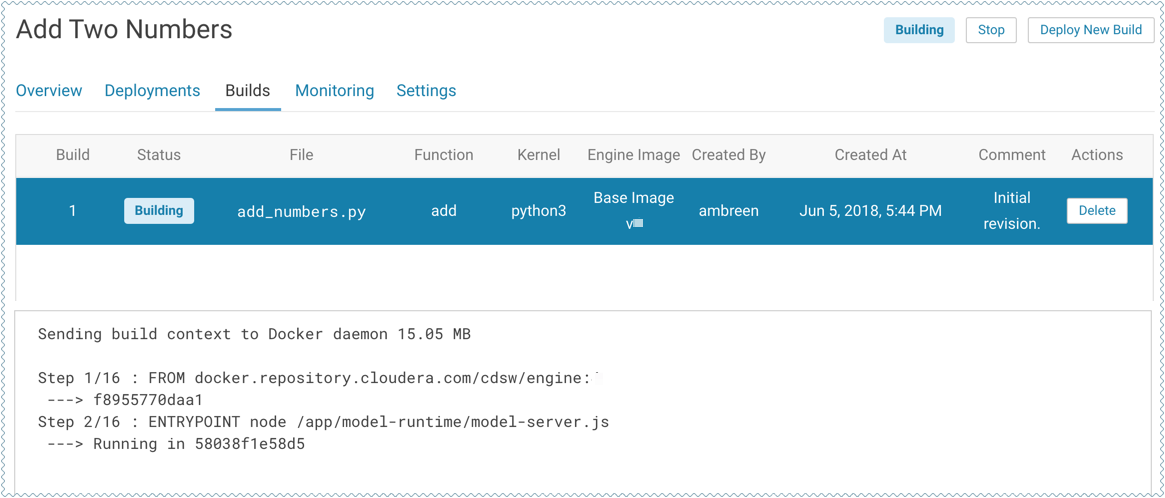
Click on the model to go to its Overview page. Click Builds to track realtime progress as the model is built and deployed. This process essentially creates a Docker container where the model will live and serve requests.
-
Once the model has been deployed, go back to the model Overview page and use the Test Model widget to make sure the model works as expected.
If you entered example input when creating the model, the Input field will be pre-populated with those values. Click Test. The result returned includes the output response from the model, as well as the ID of the replica that served the request.
Model response times depend largely on your model code. That is, how long it takes the model function to perform the computation needed to return a prediction. It is worth noting that model replicas can only process one request at a time. Concurrent requests will be queued until the model can process them.
Create and deploy a model using the Models API as instructed in this example:
- Create a project with the Python template and a legacy engine.
- Start a session.
- Run
!pip3 install sklearn - Run fit.py
The example script first obtains the project ID, then creates and deploys a model.
projects = client.list_projects(search_filter=json.dumps({"name": "<your project name>"}))
project = projects.projects[0] # assuming only one project is returned by the above query
model_body = cmlapi.CreateModelRequest(project_id=project.id, name="Demo Model", description="A simple model")
model = client.create_model(model_body, project.id)
model_build_body = cmlapi.CreateModelBuildRequest(project_id=project.id, model_id=model.id, file_path="predict.py", function_name="predict", kernel="python3")
model_build = client.create_model_build(model_build_body, project.id, model.id)
while model_build.status not in ["built", "build failed"]:
print("waiting for model to build...")
time.sleep(10)
model_build = client.get_model_build(project.id, model.id, model_build.id)
if model_build.status == "build failed":
print("model build failed, see UI for more information")
sys.exit(1)
print("model built successfully!")
model_deployment_body = cmlapi.CreateModelDeploymentRequest(project_id=project.id, model_id=model.id, build_id=model_build.id)
model_deployment = client.create_model_deployment(model_deployment_body, project.id, model.id, build.id)
while model_deployment.status not in ["stopped", "failed", "deployed"]:
print("waiting for model to deploy...")
time.sleep(10)
model_deployment = client.get_model_deployment(project.id, model.id, model_build.id, model_deployment.id)
if model_deployment.status != "deployed":
print("model deployment failed, see UI for more information")
sys.exit(1)
print("model deployed successfully!")