Running applications using CDS 3.2.3 with GPU SupportCDS 3.2.3 with GPU Support
- Log on to the node where you want to run the job.
- Run the following command to launch
spark3-shell:
wherespark3-shell --conf "spark.rapids.sql.enabled=true" \ --conf "spark.executor.memoryOverhead=5g"--conf spark.rapids.sql.enabled=true-
enables the following environment variables for GPUs:
"spark.task.resource.gpu.amount" - sets GPU resource amount per task "spark.rapids.sql.concurrentGpuTasks" - sets the number of concurrent tasks per GPU "spark.sql.files.maxPartitionBytes" - sets the input partition size for DataSource API, The recommended value is "256m". "spark.locality.wait" - controls how long Spark waits to obtain better locality for tasks. "spark.sql.adaptive.enabled" - enables Adaptive Query Execution. "spark.rapids.memory.pinnedPool.size" - sets the amount of pinned memory allocated per host. "spark.sql.adaptive.advisoryPartitionSizeInBytes" - sets the advisory size in bytes of the shuffle partition during adaptive optimization. --conf "spark.executor.memoryOverhead=5g"- sets the amount of additional memory to be allocated per executor process
- Run a job in spark3-shell.For example:
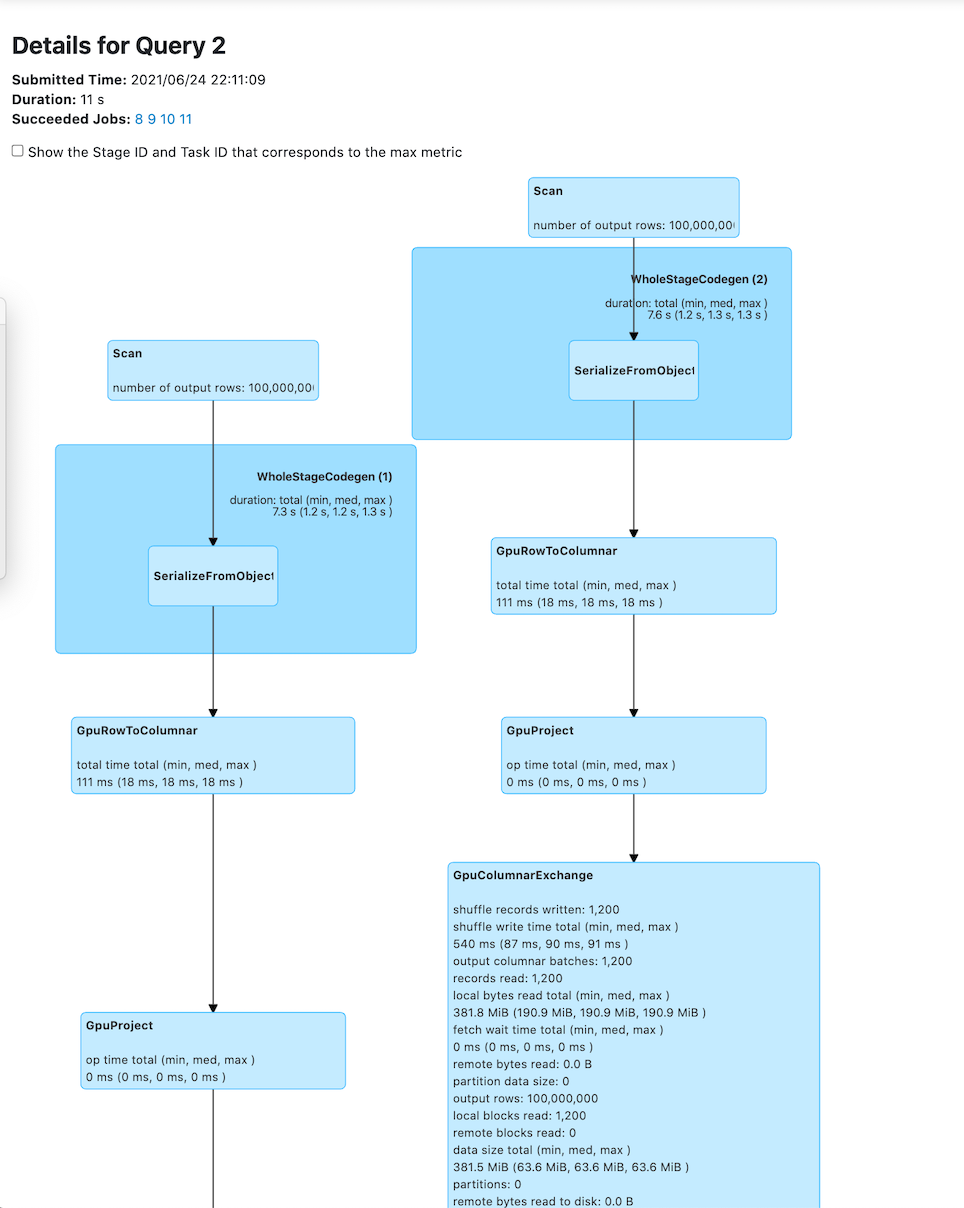
scala> val df = sc.makeRDD(1 to 100000000, 6).toDF df: org.apache.spark.sql.DataFrame = [value: int] scala>val df2 = sc.makeRDD(1 to 100000000, 6).toDF df2: org.apache.spark.sql.DataFrame = [value: int] scala> df.select($"value" as "a").join(df2select($"value" as "b"), $"a" === $"b").count res0: Long = 100000000 - You can verify that the job run used GPUs, by logging on to the Yarn UI v2 to review the
execution plan and the performance of your spark3-shell application:
Select the Applications tab then select your [spark3-shell application]. Select to see the execution plan.
Running a Spark job using CDS 3.2.3 with GPU Support with UCX enabled
- Log on to the node where you want to run the job.
- Run the following command to launch spark3-shell:
wherespark3-shell --conf "spark.rapids.sql.enabled=true" \ --conf "spark.executor.memoryOverhead=5g" --rapids-shuffle=true--rapids-shuffle=true- makes the following configuration changes for
UCX:
spark.shuffle.manager=com.nvidia.spark.rapids.spark320cdh.RapidsShuffleManager spark.executor.extraClassPath=/opt/cloudera/parcels/SPARK3/lib/spark3/rapids-plugin/* spark.executorEnv.UCX_ERROR_SIGNALS= spark.executorEnv.UCX_MEMTYPE_CACHE=n
- Run a job in spark3-shell.