
Cloudera AI Inference service Configuration and Sizing
Consider the following factors for the configuration and sizing of Cloudera AI Inference service.
Node Group Configuration
The configuration and size ofCloudera AI Inference service cluster is determined by the nature of the workloads you expect to deploy on the platform. Certain models might require GPUs, while other kinds of models might run only on CPUs. Similar considerations must be taken for the model endpoints. For example, you must determine the number of replicas of a model that are required to handle normal inference traffic, and there could be peak traffic for which additional replicas shall be spun up to keep user experience at acceptable levels.
For example, when you deploy the following NVIDIA NIM for Llama 3.1:
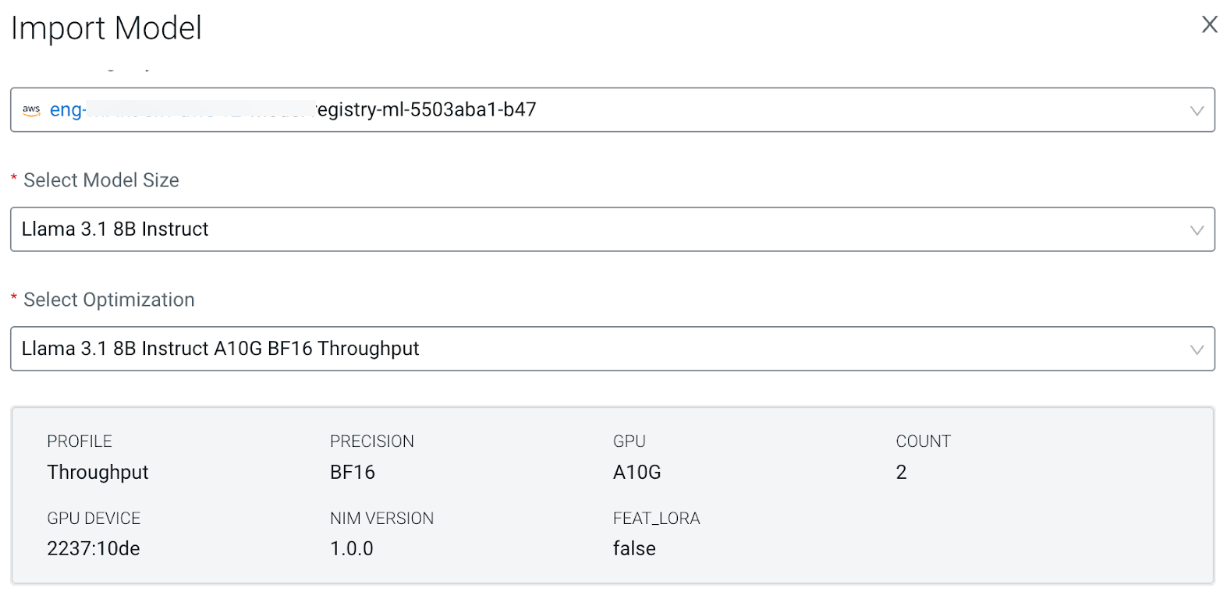
In the above image, you can see that each replica of this model requires two A10G GPUs (due
to the model being optimized for A10G with a tensor parallelism of two). You can assume that
two replicas are required to handle normal traffic, but an additional replica would be
required during peak traffic. Therefore, you must configure the model endpoint to autoscale
between two and three replicas. Consequently, for normal traffic 4 A10G GPUs must be
allocated, and two more for peak traffic. To ensure seamless rolling update for this model
endpoint, and assuming updates are made during off-peak traffic, your cluster must be able
to add eight A10G GPUs on-demand. An optimal node group configuration for this scenario on
AWS would be one that has 0-2 instances of the g5.12xlarge instance type.
One instance runs two replicas during normal load, and the second instance is added using
autoscaling during peak traffic, and during rolling update. Another, less cost-efficient,
possibility is to use a single g5.48xlarge instance type in the node group,
in which case all the resource headroom is available on a single node. The larger node also
helps to ensure that autoscaling model replicas and rolling updates are quicker as you do
not have to wait for a new node to be spun up, and the container images to be pulled.
Instance Volume Sizing
Cloudera AI Inference service service downloads model artifacts to the instance volume (also known as root volume) of the node where the model replica pod is scheduled. Large Language Model artifacts can be tens to hundreds of gigabytes large. The required instance volume size for a given node group can be estimated using the following formula:
S ≅ So + ∑ni=1riSi + Sc
Where:
- So: Size of storage required by the operating system, typically 30 to 40 GB.
- Si: Size of the i-th model replica artifacts on a node.
- ri: Number of replicas of the i-th model on the node.
- Sc: Total size of all container images on the node. This is dominated by model runtime container images.
For instance, if you want to run 2 replicas of the instruction-tuned Llama 3.1 70b at FP16 precision on a node, you would need something like the following:
S ~ 40 + 2*148 + 20 = 356 GB
Where it is assumed that the aggregate size of container images is 20 GB.
Cloudera recommends that the instance volume is slightly over-provisioned to ensure that you do not run out of disk space. In the above example, for instance, it is recommended to round up to 512 GB of instance volume. A larger instance volume also provides higher IOPs, which helps reduce model endpoint startup times. Note that the instance volume of an existing node group cannot be modified. You must first delete the node group and then add it back to the cluster with the new instance volume size.
Choosing an NVIDIA NIM Profile
The following guidance here is in the context ofCloudera AI Inference service. See Nvidia documentation for information about NVIDIA NIM profiles.
NVIDIA NIM comes in three kinds of optimization profiles:
- Latency: This profile minimizes Time to First Token (TTFT) and Inter-Token Latency (ITIL) by using higher tensor parallelism, that is, using more GPUs.
- Throughput: This maximizes the token throughput per GPU by utilizing the minimum number of GPUs to host the model.
- Generic: Unlike the first two profiles, this profile uses the vLLM backend to load the model and run inference against it. This profile provides the most flexibility in terms of choosing GPU models at the cost of lower performance. Note that not all NIMs provide the generic profiles.
For a given precision, the latency profile provides the highest performance by utilizing the maximum number of GPUs while the generic profile offers the most flexibility by sacrificing performance and precision. The throughout profile strikes a good balance between the other two.
Cloudera AI Inference service lets you choose which NVIDIA NIM profile to deploy, so that only artifacts specific to the chosen profile are downloaded to your Cloudera AI Registry to save on storage costs.
- Hardware budget - which cloud instance types you have access to.
- Model performance requirement in terms of latency and throughput.
As an example, let us look at some of the available profiles for the instruction-tuned Llama 3.1 8b model. Each entry in the Optimization picker specifies the model name, GPU architecture, floating point precision, and profile type:
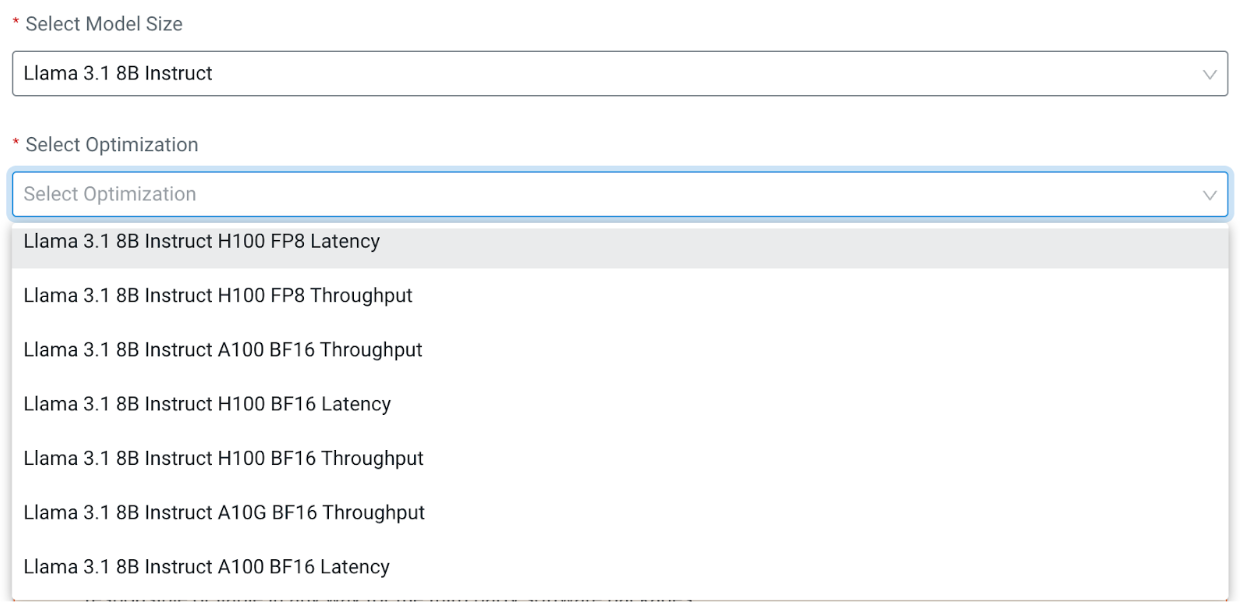
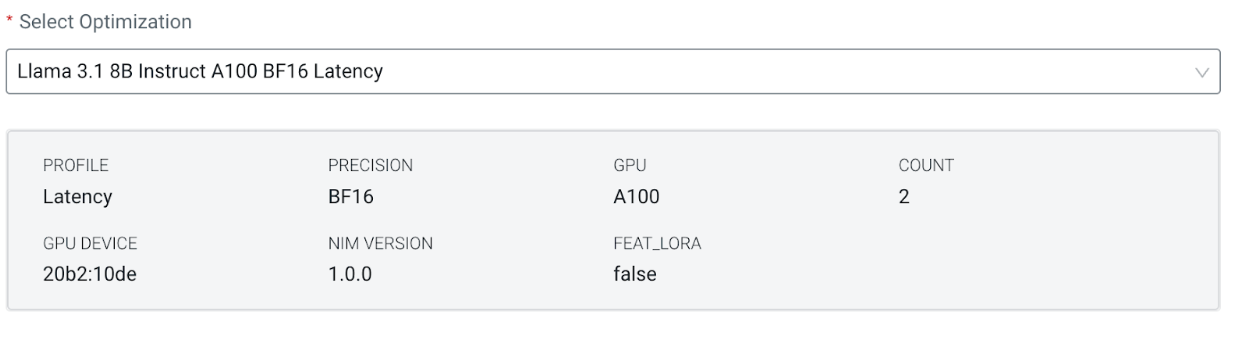
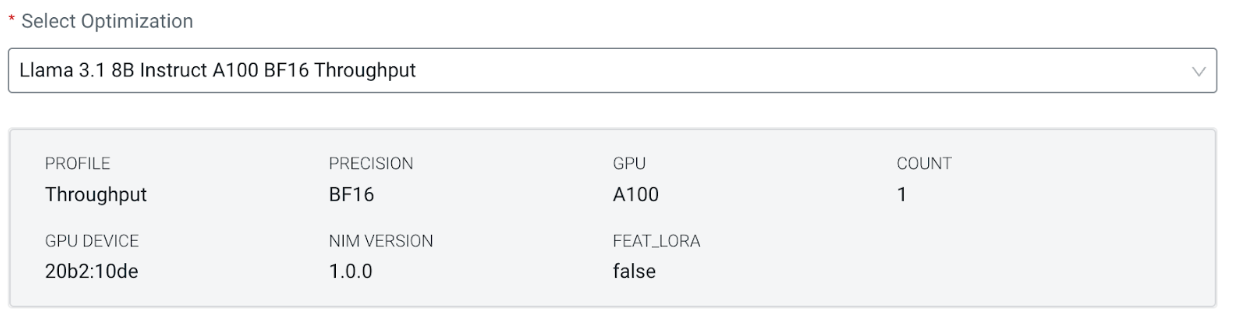
As shown in the figures, the GPU count per model replica of the latency profile is double the size of the throughput profile.
Quantization, for example, FP8 vs BF16. A quantized
model, if available, will have lower resource footprint and higher performance (latency and
throughput) than a non-quantized one.
The actual latency and throughput as seen by a client application is affected by the end-end performance of the network between the client and the model server, which will include authentication and authorization checks, in addition to the performance of the chosen NVIDIA NIM profile, as well as the number of concurrent connections. For any chosen profile, end-to-end latency and throughput can be optimized by increasing the number of model endpoint replicas for the model.