Migrating Hive metadata
You first perform a dry run of HMS Mirror, and check the output. You see how to execute HMS Mirror to migrate the Hive metadata in HMS on the HDP cluster to the Cloudera as a Service cluster.
In this procedure, you run the HMS Mirror command as shown in the step 6. In summary, use the Migrate ACID flag option -ma to migrate Hive ACID tables. Alternatively, you can migrate the data by specifying the HYBRID data strategy. An HMS Mirror command that sets the intermediate storage flag stages data in S3, as required for transfers in the public cloud. The target Cloudera SaaS environment uses the S3 object store in the cloud instead of the on-prem HDFS because the target does not have direct access to the on-prem HDFS.
- If you are going to migrate non-native Hive tables, such as HBase, Kafka, or JDBC-backed tables, make these services available on the Cloudera cluster; otherwise metadata migration does not work.
- If you have many databases to migrate, separate them into batches of 100 databases, or fewer. HMS Mirror does not accept a larger batch.
- A batching strategy is recommended. Inspect the number of tables/partitions within each database and develop a general criterion for batching.
-
Run HMS Mirror to perform a dry run by omitting the -e option.
The output looks something like this:hms-mirror -db migrate_db -mnn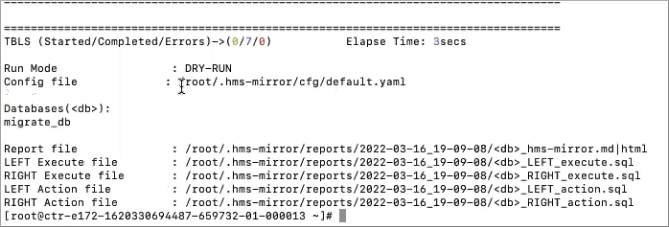
-
List the generated reports.
For example,
ls /root/.hms-mirror/reports/2022-03-16_19-09-08/
-
Open the HMS Mirror report in the migrate_db_hms-mirror.html file, and scroll
down to see the DB Create Statement.
 Reports follow the DB Create Statement.
Reports follow the DB Create Statement. -
Scroll down to Skipped Tables/Views.
 Your managed tables will not be listed in Skipped Tables/Views, if you omit the -ma option, for example.
Your managed tables will not be listed in Skipped Tables/Views, if you omit the -ma option, for example. -
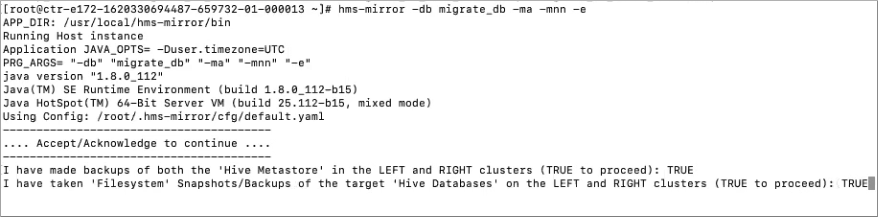
At the prompt to confirm that you backed up the Hive Metastore (HMS) in both
clusters, enter TRUE.