Step 2 Create an Optimization Plan
Describes how an Optimization Plan can accelerate your migration by defining which workloads, jobs, and queries to optimize before and which workloads to optimize after migration.
Your optimization plan should include a list of workloads or set of workloads and their existing status, including any current performance issues and health check violations, and the suggested improvement recommendations by Workload Manager or Workload XM. From your list of insights, decide which workloads, jobs, and queries require optimization before migration and which workloads, jobs, and queries require optimization after migration.
- The type and severity of the issue
- The Cloudera form factor
- Your data infrastructure
- The number of clusters in your Cloudera environment
- Memory sizing considerations
- The before and after features, engines, and services
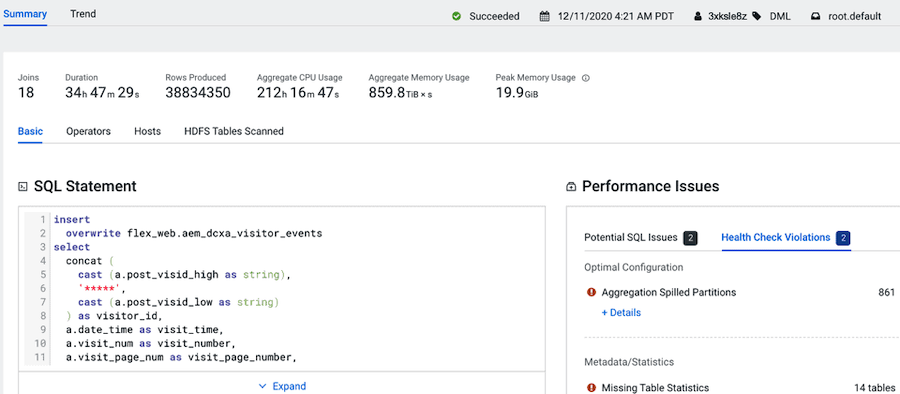
When a performance issue lists Aggregate Spilled Partitions as the cause it denotes memory issues. To ensure that all your SQL queries have sufficient memory when processing you should consider increasing your cluster’s memory size. For this issue, the optimization would be solved as part of your Cloudera infrastructure and sizing considerations. Where you would use this information to research the costs of more memory for your Cloudera clusters as this would ensure enough memory for other such queries.
For the missing table statistics issue, it would also be more productive to collect the table statistic metadata after migration. Therefore, for this issue the optimization should be performed after migration.
- Understanding what features and engines are available in Cloudera.
For example, users will have the ability to use Hive on TEZ and Hive LLAP in Cloudera, which are not available in CDH or HDP. Therefore, consider optimizing your Hive engine issues after migration.
- Your legacy applications and workloads that are at the end of their life cycle or those that would require development in order to work in Cloudera.
- Any issue or condition that would result in migrating garbage data. For example, you can immediately improve the processing performance of an Impala query by rewriting any poor SQL code, as described in the next topic Identifying and Correcting Inefficient SQL Code.