Cloudera on cloud services
Cloudera on cloud consists of a number of cloud services designed to address specific enterprise data cloud use cases.
This includes Cloudera Data Hub powered by Cloudera Runtime, data services (Cloudera Data Warehouse, Cloudera AI, Cloudera Data Engineering, and Cloudera DataFlow), the administrative layer (Cloudera Management Console), and SDX services (Data Lake, Cloudera Data Catalog, Cloudera Replication Manager, and Cloudera Observability).
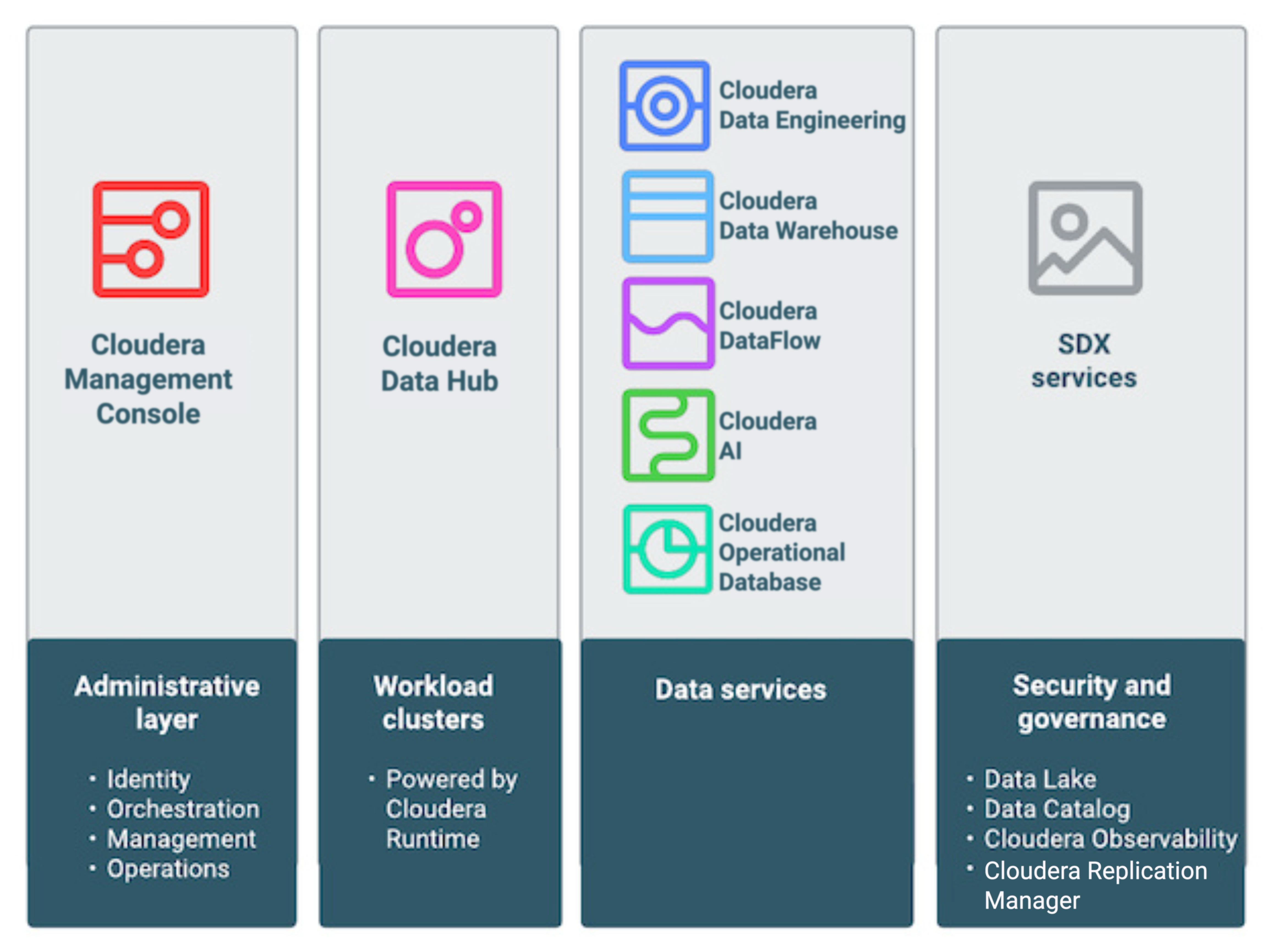
Administrative layer
Cloudera Management Console is a general service used by Cloudera administrators to manage, monitor, and orchestrate all of the Cloudera services from a single pane of glass across all environments. If you have deployments in your data center as well as in multiple public clouds, you can manage them all in one place - creating, monitoring, provisioning, and destroying services.
Workload clusters
Cloudera Data Hub is a service for launching and managing workload clusters powered by Cloudera Runtime (Cloudera’s new unified open source distribution including the best of CDH and HDP). This includes a set of cloud optimized built-in templates for common workload types as well as a set of options allowing for extensive customization based on your enterprise’s needs.
Cloudera Data Hub provides complete workload isolation and full elasticity so that every workload, every application, or every department can have their own cluster with a different version of the software, different configuration, and running on different infrastructure. This enables a more agile development process.
Since Cloudera Data Hub clusters are easy to launch and their lifecycle can be automated, you can create them on demand and when you don’t need them, you can return the resources to the cloud.
Data services
Cloudera Data Engineering is an all-inclusive data engineering toolset building on Apache Spark that enables orchestration automation with Apache Airflow, advanced pipeline monitoring, visual troubleshooting, and comprehensive management tools to streamline ETL processes across enterprise analytics teams.
Cloudera DataFlow is a cloud-native universal data distribution service powered by Apache NiFi that lets developers connect to any data source anywhere with any structure, process it, and deliver to any destination. It offers a flow-based low-code development paradigm that aligns best with how developers design, develop, and test data distribution pipelines.
Cloudera Data Warehouse is a service for creating and managing self-service data warehouses for teams of data analysts. This service makes it easy for an enterprise to provision a new data warehouse and share a subset of the data with a specific team or department. The service is ephemeral, allowing you to quickly create data warehouses and terminate them once the task at hand is done.
Cloudera AI is a service for creating and managing self-service Cloudera AI Workbenches. This enables teams of data scientists to develop, test, train, and ultimately deploy machine learning models for building predictive applications all on the data under management within the enterprise data cloud.
Cloudera Operational Database is a service for self-service creation of an operational database. Cloudera Operational Database is a scale-out, autonomous database powered by Apache HBase and Apache Phoenix. You can use it for your low-latency and high-throughput use cases with the same storage and access layers that you are familiar with using in CDH and HDP.
Security and governance
Shared Data Experience (SDX) is a suite of technologies that make it possible for enterprises to pull all their data into one place to be able to share it with many different teams and services in a secure and governed manner. There are four discrete services within SDX technologies: Data Lake, Cloudera Data Catalog, Cloudera Replication Manager, and Cloudera Observability.
Data Lake is a set of functionality for creating safe, secure, and governed data lakes which provides a protective ring around the data wherever that’s stored, be that in cloud object storage or HDFS. Data Lake functionality is subsumed by the Cloudera Management Console service and related Cloudera Runtime functionality (Ranger, Atlas, Hive MetaStore).
Cloudera Data Catalog is a service for searching, organizing, securing, and governing data within the enterprise data cloud. Cloudera Data Catalog is used by data stewards to browse, search, and tag the content of a data lake, create and manage authorization policies (by file, table, column, row, and so on), identify what data a user has accessed, and access the lineage of a particular data set.
Cloudera Replication Manager is a service for copying, migrating, snapshotting, and restoring data between environments within the enterprise data cloud. This service is used by administrators and data stewards to move, copy, backup, replicate, and restore data in or between data lakes. This can be done for backup, disaster recovery, or migration purposes, or to facilitate dev/test in another virtual environment.
Cloudera Observability is a service for analyzing and optimizing workloads within the enterprise data cloud. This service is used by database and workload administrators to troubleshoot, analyze, and optimize workloads in order to improve performance and/or cost.
The following table illustrates which services are available on supported cloud providers:
| Cloudera service | AWS | Azure | GCP | |
|---|---|---|---|---|
| Data services | Cloudera Data Engineering | GA | GA | Not available |
| Cloudera DataFlow | GA | GA | Only DataFlow Functions are available on GCP. Other DataFlow features are not available. | |
| Cloudera Data Hub | GA | GA | GA | |
| Cloudera Data Warehouse | GA | GA | Not available | |
| Cloudera AI | GA | GA | Not available | |
| Cloudera Operational Database | GA | GA | GA | |
| Control Plane services | Cloudera Data Catalog | GA | GA | GA |
| Cloudera Management Console | GA | GA | GA | |
| Cloudera Replication Manager | GA | GA | GA | |
| Cloudera Observability | GA | GA | GA |