Component description
This section includes an overview of the VNet, subnets, gateways and route tables, and security groups required for Cloudera on Azure.
VNet
An Azure Virtual Network (VNet) is needed for deploying Cloudera workloads into the customer’s cloud account. VNet is similar to a traditional network that you would operate in your own data center, but brings with it additional benefits of Azure's infrastructure such as scale, availability, and isolation.
- The CIDR block for the VNet should be sufficiently large for supporting all
the Cloudera Data Hub clusters and data services that you intend to run.
Refer to
VNet and subnet planning
to understand how to compute the CIDR block range. - In addition, you may want to ensure that the CIDR ranges assigned to the VNet do not overlap with any of your on-premise network CIDR ranges, as this may be a requirement for setting up connectivity from your on-premise network to the subnets.
Subnets
A subnet is a partition of the virtual network in which Cloudera workloads are launched.
- The CIDR block for the subnet should be sufficiently large for supporting the Cloudera workload targeted to run inside it. Refer to
VNet and subnet planning
to understand how to compute the CIDR block range. - Several Cloudera data services run on Kubernetes
and use Kubenet CNI plugin for networking. Azure's Kubenet CNI plugin requires that the subnet
is not shared between multiple Kubernetes clusters as it adds custom routes (see
Bring your own subnet and route table with kubenet
). Therefore, as many subnets as the expected number of workloads need to be created. - In addition, you may want to ensure that the CIDR ranges assigned to the subnets do not overlap with any of your on-premise network CIDR ranges, as this may be a requirement for setting up connectivity from your on-prem network to the subnets.
- A subnet can be associated with a Network Security Group (NSG). However, since Cloudera works with a fully private network configuration where communication is always initiated from VMs within the subnets, an NSG at subnet level is generally not useful for this configuration.
Gateways and route tables
This topic covers recommended gateway and route table configurations for Cloudera on Azure.
Connectivity from Cloudera Control Plane to Cloudera workloads
- As described in the
Subnets
section above, each Cloudera data service workload requires its own subnet and a non-shared route table associated with it (seeBring your own subnet and route table with kubenet
). - As described in the
Taxonomy of network architectures
, nodes in the Cloudera workloads need to connect to the Cloudera Control Plane over the internet to establish a “tunnel” over which the Cloudera Control Plane can send instructions to the workloads. - Private AKS cluster is a feature that lets Cloudera access a Kubernetes workload cluster over a private IP address (see
Enabling a private Cloudera Data Warehouse environment in Azure Kubernetes Service
). When it is enabled for a Cloudera Data Warehouse workload, Cloudera Data Warehouse requires the user to have already set up internet connectivity for the subnet (seeOutbound type of userDefinedRouting)
. - Cloudera data services such as Datalake and Cloudera AI create a public load balancer for internet connectivity.
- If a firewall is configured, the destinations described in
Azure outbound network access destinations
need to be allowed for the Cloudera workloads to work.
Connectivity from customer on-prem to Cloudera workloads
- As described in the
Use cases
section (seeCloudera on cloud reference network architecture for Azure
>Use Cases
), data consumers need to access data processing or consumption services in the Cloudera workloads. - Given that these are created with private IP addresses in private subnets, the customers need to arrange for access to these addresses from their on-prem or corporate networks in specific ways.
- There are several possible solutions for achieving this, but one that is depicted
in the architectural diagram, uses
Azure VPN Gateway
. - Each workload provides an option to connect to the workload endpoint over a public or a private IP. It's recommended that the public IPs are disabled and that users rely on the corporate network connectivity for accessing the workloads with private IPs.
Private endpoints
Cloudera workloads can be configured to access the Azure resources over a private IP (which is called a private endpoint) or over a public IP (which is called a service endpoint).
The private endpoint setup requires a private DNS zone which the VNet is linked to
and resolves the Azure resources to private IP addresses. Cloudera supports a private endpoint configuration for Azure postgres only. Cloudera admin can choose to either create the private DNS zone and
link it to the VNet as described in Bringing your own private DNS
, or let the Cloudera create them when provided with necessary configuration
described in Using Cloudera-managed private DNS
.
Cloudera supports only service endpoint configuration
for other Azure resources(such as Microsoft Storage). The subnets need to be enabled to support
the service endpoints. See Service endpoint for Azure Postgres
for detailed steps.
Security groups
During the specification of a VNet to Cloudera, the Cloudera admin specifies security groups that will be associated with all the Cloudera workloads launched within that VNet. These security groups will be used in allowing the incoming traffic to the hosts.
Security groups for Data Lakes
During the specification of a VNet to Cloudera, the Cloudera admin can either let Cloudera create the required security groups, taking a list of IP address CIDRs as input; or create them in Azure and then provide them to Cloudera.
When getting started with Cloudera, the Cloudera admin can let Cloudera create security groups, taking a list of IP address CIDRs as input. These will be used in allowing the incoming traffic to the hosts. The list of CIDR ranges should correspond to the address ranges from which the Cloudera workloads will be accessed. In a VPN-peered VNet, this would also include address ranges from customer’s on-prem network. This model is useful for initial testing given the ease of set up.
Alternatively, the Cloudera admin can create security groups on their own and select them during the setup of the VNet and other network configuration. This model is better for production workloads, as it allows for greater control in the hands of the Cloudera admin. However, note that the Cloudera admin must ensure that the rules meet the requirements described below.
For a fully private network, network security groups should be configured
according to the types of access requirements needed by the different services in the workloads.
The Network security groups
section includes all the details of the necessary rules that
need to be configured.
Note that for a fully private network, even specifying an open access here (such as 0.0.0.0/0) is restrictive because these services are deployed in a private subnet without a public IP address and hence do not have an incoming route from the Internet. However, the list of CIDR ranges may be useful to restrict which private subnets of the customer’s on-prem network can access the services.
Rules for AKS based workloads are described separately in the following section.
Additional rules for AKS-based workloads
At the time of enabling a Cloudera data service, the Cloudera admin can specify a list of CIDR ranges that will be used in allowing the incoming traffic to the workload Load Balancer.
This list of CIDR ranges should correspond to the address ranges from which the Cloudera data service workloads will be accessed. In a VPN peered VNet, this would also include address ranges from customer’s on-prem network. In a fully private network setup, 0.0.0.0/0 implies access only within the VNet and the peered VPN network which is still restrictive.
Cloudera Data Warehouse data service currently supports fully private AKS clusters, which means the Kubernetes API server will have a private IP address. Cloudera AI uses a public endpoint by default for all AKS cluster control planes. It is highly recommended to provide a list of outbound public CIDR ranges at the time of provisioning a data service to restrict access to the AKS clusters. In addition, the data service adds Cloudera public CIDR range to allow access between workloads and Cloudera Control Plane. An example configuration section for a data service looks like below:
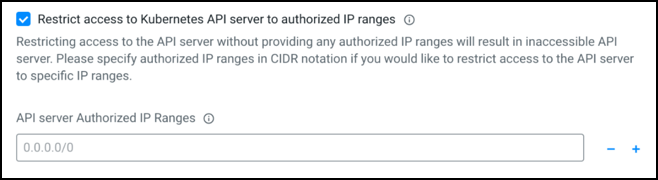
Specific guidelines for restricting access to Kubernetes API server and workloads are
detailed in Restricting access for Cloudera services that
create their own security groups on Azure
by each data service.
Within the AKS cluster, security groups are defined to facilitate AKS control plane-pod communication, inter-pod and inter-worker node communication as well as workload communication through Load Balancers.
Outbound connectivity requirements
Outbound traffic from the worker nodes is unrestricted and is targeted at other Azure
services and Cloudera services. The comprehensive list of services
that get accessed from a Cloudera environment can be found in
Azure outbound network access destinations
.
Domain names for the endpoints
The previous sections dealt with how connectivity is established to the workload infrastructure. This section deals with “addressability”.
The workloads launched by Cloudera contain a few services that need to be accessed by the Cloudera admins and data consumers. These include services such as Cloudera Manager; metadata services such as the Hive Metastore, Atlas, or Ranger; and data processing or consumption services such as Oozie server, Hue, and so on. Given the nature of the cloud infrastructure, the IP addresses for the nodes running these services may change (for example if the infrastructure is restarted or repaired). However, these should have statically addressable DNS names so that users can access them with the same names.
In order to help with this, Cloudera assigns DNS names to these nodes. These naming schemes have the following properties:
- The DNS name is of the following format for each Data Lake node and the Data Lake
cluster endpoint:
An example could be:<CLUSTER_NAME>-{<HOST_GROUP><i>}.<ENVIRONMENT-IDENTIFIER>.<CUSTOMER_IDENTIFIER>.cloudera.sitemy-dataeng-master0.my-envir.aaaa-1234.cloudera.siteThis name has the following components:
- The base domain is cloudera.site. This is a publicly registered
DNS suffix
. It is also a registered Route53 hosted zone in a Cloudera owned AWS account. - The
<CUSTOMER_IDENTIFIER>is unique to a customer account on Cloudera made of alphanumeric characters and a “-” (dash). - The
<ENVIRONMENT_IDENTIFIER>is generated based on the environment name and is truncated to 8 characters. - The
<CLUSTER_NAME>is the cluster name given to the Data Lake or Cloudera Data Hub. It is appended with a<HOST_GROUP>name such as “gateway”, “master”, “worker”, and so on, depending on the role that the node plays in the cluster. If there are more than one of these nodes playing the same role, they are appended with a serial number<i>.
- The base domain is cloudera.site. This is a publicly registered
- The DNS name of the endpoints of the Cloudera data
services is of the following format:
- For a Virtual Warehouse in Cloudera Data Warehouse, it is:
<VIRTUAL_WAREHOUSE_NAME>.dw-<CDW_ENVIRONMENT_IDENTIFIER>.<CUSTOMER_IDENTIFIER>.cloudera.site<VIRTUAL_WAREHOUSE_NAME>is the name of the Virtual Warehouse created. There could be multiple virtual warehouses for a given Cloudera environment.<CDW_ENVIRONMENT_IDENTIFIER>is the identifier for the Cloudera environment.
- For a Session Terminal in Cloudera AI
workbench, it
is:
<TTY_SESSION_ID>.<CML_WORKSPACE_ID>.<ENVIRONMENT_IDENTIFIER>.<CUSTOMER_IDENTIFIER>.cloudera.site<TTY_SESSION_ID>is the ID of the Cloudera AI Terminal Session ID.<CML_WORKSPACE_ID>is the ID of the Cloudera AI workspace created.- The
<ENVIRONMENT_IDENTIFIER>is generated based on the environment name and is truncated to 8 characters. If the 8th character is a “-” (dash), then it is truncated to 7 characters instead.
- For all the Cloudera data services listed
above, the common portions of the DNS include:
- The base domain is cloudera.site. This is a publicly registered
DNS Suffix
. It is also a registered Route53 hosted zone in a Cloudera owned AWS account. - The
<CUSTOMER_IDENTIFIER>is unique to a customer account on Cloudera made of alphanumeric characters and a “-” (dash).
- The base domain is cloudera.site. This is a publicly registered
- The length of the DNS name is restricted to 64 characters due to some limitations with Hue workloads.
- These names are stored as A records in the Route53 hosted zone in the Cloudera managed Cloudera Control Plane AWS account. Hence, you can resolve these names from any location outside of the VPC. However, note that they would still resolve to private IP addresses and hence are constrained by the connectivity setup described in preceding sections.
- Within a Cloudera environment, the DNS resolution happens differently. Every Cloudera environment has a DNS server that is played by a component called FreeIPA. This server is seeded with the hostnames of the nodes of all workload clusters in the environment. Every node in a Data Lake, Cloudera Data Hub and data service is configured to look up the FreeIPA DNS service for name resolution within the cluster.
- FreeIPA nodes are internal to the Cloudera environment both for resolving and use. They don't have public DNS records.
- For a Virtual Warehouse in Cloudera Data Warehouse, it is:
DNS
Azure-provided DNS is recommended for the VNet. This is required to enable private AKS
clusters and private access to Postgres databases among others, as described in Private
endpoints
above.