Troubleshooting for RAZ-enabled AWS environment
This section includes common errors that might occur while using a RAZ-enabled AWS environment and the steps to resolve the issues.
Why does the "AccessDeniedException" error appear? How do I resolve it?
org.apache.hadoop.hive.ql.metadata.HiveException: java.nio.file.AccessDeniedException:
s3a://abc-eu-central/abc/hive: getFileStatus on s3a://abc-eu-central/abc/hive:
com.amazonaws.services.signer.model.AccessDeniedException: Ranger result: DENIED, Audit:
[AuditInfo={auditId={null} accessType={read} result={NOT_DETERMINED} policyId={-1} policyVersion={null} }],
Username: hive/demo-dh-master0.abc.xcu2-8y8x.dev.cldr.work@abc.XCU2-8Y8X.DEV.CLDR.WORK (Service: null;
Status Code: 403; Error Code: AccessDeniedException; Request ID: f137c7b2-4448-4599-b75e-d96ae9308c5b;
Proxy: null):AccessDeniedExceptionCause
This error appears when the hive user does not have the required S3 policy.
Remedy
For more information, see Ranger policy options for RAZ-enabled AWS environment.
Why does the "Permission denied" error appear? How do I resolve it?
Error: Error while compiling statement:
FAILED: HiveAccessControlException Permission denied: user [csso_abc] does not have
[READ] privilege on [s3a://abc-eu-central/abc/hive] (state=42000,code=40000)Cause
This error appears if you did not add the required Hive URL authorization policy to the user.
Remedy
Why does the "S3 access in hive/spark/mapreduce fails despite having an "allow" policy" error message appear? How do I resolve it?
S3 access in hive/spark/mapreduce fails despite having an "allow" policy defined for the path
with ‘java.nio.file.AccessDeniedException: s3a://sshiv-cdp-bucket/data/exttable/000000_0: getFileStatus on
s3a://sshivalingamurthy-cdp-bucket/data/exttable/000000_0: com.amazonaws.services.signer.model.AccessDeniedException:
Ranger result: NOT_DETERMINED, Audit: [AuditInfo={auditId={a6904660-1a0f-3149-8a0b-c0792aec3e19} accessType={read}
result={NOT_DETERMINED} policyId={-1} policyVersion={null} }] (Service: null; Status Code: 403; Error Code: AccessDeniedException;
Request ID: null):AccessDeniedException’
Cause
In some cases, RAZ S3 requires a non-recursive READ access on the parent S3 path. This error appears when the non-recursive READ access is not provided to the parent S3 path.
Remedy
-
Add the missing Ranger policy to the end user.
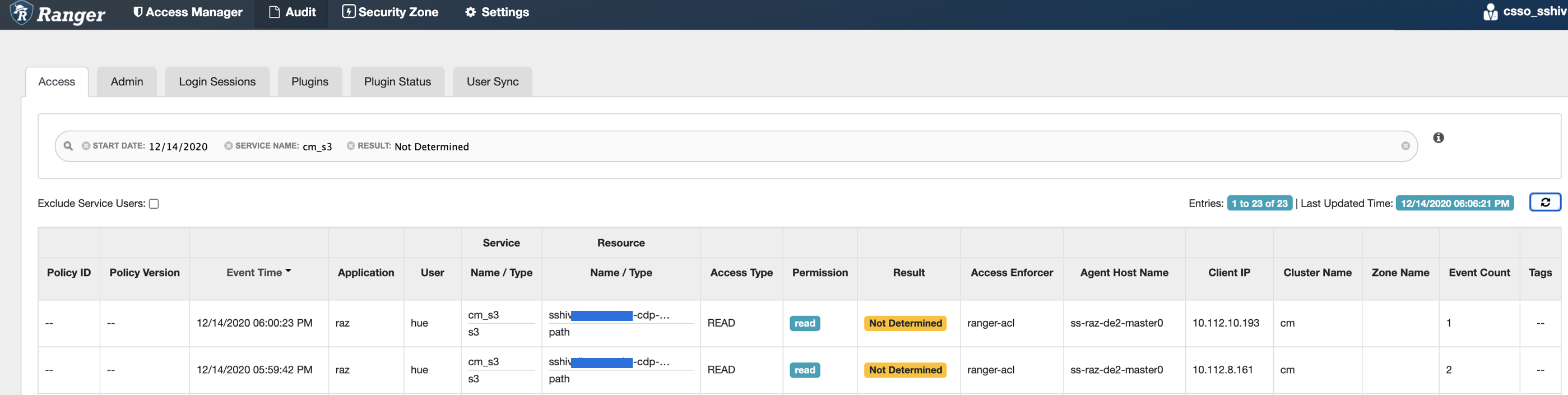
The following sample image shows the Access tab on the page where you can track the user and the path:
An error related to Apache Flink appears after the job fails. How do I resolve this issue?
2021-06-01 00:00:18,872 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint
- Shutting YarnJobClusterEntrypoint down with application status FAILED. Diagnostics java.nio.file.AccessDeniedException:
s3a://jon-s3-raz/data/flink/araujo-flink/ha/application_1622436888784_0031/blob: getFileStatus on
s3a://jon-s3-raz/data/flink/araujo-flink/ha/application_1622436888784_0031/blob: com.amazonaws.services.signer.model.AccessDeniedException:
Ranger result: DENIED, Audit: [AuditInfo={auditId={84aba1b3-82b5-3d0c-a05b-8f5512e0fd36} accessType={read} result={NOT_DETERMINED}
policyId={-1} policyVersion={null} }], Username: srv_kafka-client@PM-AWS-R.A465-4K.CLOUDERA.SITE (Service: null; Status Code: 403;
Error Code: AccessDeniedException; Request ID: null; Proxy: null):AccessDeniedExceptionCause
This error appears if there is no policy granting the necessary access to the /data/flink/araujo-flink/ha path.
Remedy
What do I do to display the Thread ID in logs for RAZ?
When you enable the DEBUG level for RAZ, a detailed verbose log is generated. It is cumbersome and tedious to identify the issue pertaining to a specific RAZ authorization request; therefore, Thread ID is good information to capture in the debug log.
Remedy
-
Restart the Ranger RAZ service.
The service prints the debug log details with Thread ID. To debug an issue, you can filter the logs based on the Thread ID.
The sample snippet shows the log generated with Thread ID:
What do I do when a long-running job consistently fails with the expired token error?
Sample error snippet - “Caused by: com.amazonaws.services.s3.model.AmazonS3Exception: The provided token has expired. (Service: Amazon S3; Status Code: 400; Error Code: ExpiredToken; Request ID: xxxx; S3 Extended Request ID:xxxx...“
Cause
This issue appears when the S3 Security token has expired for the s3 call.