Resizing a Data Lake
Data Lake resizing is the process of scaling up a light duty or medium duty Data Lake to the medium duty or enterprise form factor, which have greater resiliency than light duty and can service a larger number of clients. You can trigger the resize in the Cloudera UI or through the CDP CLI. As part of Data Lake resizing via CDP CLI, you can also resize from single-AZ to multi-AZ.
Overview
During a typical Data Lake scaling operation, the metadata maintained in the Data Lake services is automatically backed up, a new enterprise or medium duty Data Lake is created within the environment, and the Data Lake metadata is automatically restored to the new enterprise or medium duty Data Lake.
As part of the Data Lake resizing, you can optionally resize an existing single
availability zone (single-AZ) Data Lake to a multiple availability zone (multi-AZ) Data
Lake. To resize your Data Lake from single to multi-AZ, add the --multi-az
flag to the Data Lake resize command.
Supportability matrix
| Source | Target | Supported? | |||
|---|---|---|---|---|---|
| Cloudera Runtime version | Scale | Deployment | Scale | Deployment | |
| 7.2.16 and prior | Light | SingleAZ | Medium | SingleAZ | Yes |
| 7.2.16 and prior | Light | SingleAZ | Medium | MultiAZ | Yes |
| 7.2.16 and prior | Light | SingleAZ | Enterprise | Any | No |
| 7.2.16 and prior | Medium | Any | Enterprise | Any | No |
| 7.2.17+ | Light | SingleAZ | Medium | Any | No |
| 7.2.17+ | Light/Medium | SingleAZ | Enterprise | SingleAZ | Yes |
| 7.2.17+ | Light/Medium | SingleAZ | Enterprise | MultiAZ | Yes |
| 7.2.17+ | Medium | MultiAZ | Enterprise | SingleAZ | No |
| 7.2.17+ | Medium | MultiAZ | Enterprise | MultiAZ | Yes |
| 7.2.17+ | Enterprise | SingleAZ | Enterprise | MultiAZ | Yes |
Resizing a Data Lake is supported with all data services.
Before you begin, note the following:
- The resizing operation requires an outage and should be performed during a maintenance window. No metadata changes may occur during the resizing, as these changes will no longer be present once the resizing operation completes (the previously backed up metadata is being restored). Suspend any operations that may result in any SDX metadata change during the resizing operation.
- Cloudera Data Hub clusters should be stopped before the resizing operation begins. For any cluster that cannot be stopped, stop all of the services on the Cloudera Data Hub cluster through the Cloudera Manager UI.
- With CDF 2.0 or lower, some flows must be re-created after a resizing operation.
Limitations
- Cloudera Manager configurations are not retained when a Data Lake is resized (they are lost when a new Data Lake cluster is created as part of backup and restore operation). Therefore, prior to performing a resize you should note all the custom Cloudera Manager configurations of your Data Lake and then once the resizing operation is completed, reapply them.
If a Data Lake has been vertically scaled, the following limitations apply:-
If Data Lake VM instances are vertically scaled using runbooks or via vertical scaling, they will return to default types after resizing.
-
If Data Lake storage disks are vertically scaled using runbooks or via vertical scaling, they will return to default sizes after resizing.
-
If the storage and/or image type of the remote database are resized using the cloud provider console, they will fall back to defaults after resizing.
As a workaround, you need to resize the Data Lake via CDP CLI (instead of Cloudera user interface) and make sure to add one or more of the following to the resize command to reapply the scaling changes made during vertical scaling:
If Data Lake VM instances were scaled:
--custom-instance-types [***VALUE***]For example:
--custom-instance-types name=core,instanceType=r5.xlargeIf Data Lake remote database was scaled:
--custom-database-compute-storage [***VALUE***]For example:
--custom-database-compute-storage instanceType=db.m5.large,storageSize=500If Data Lake storage disks were scaled:
--custom-instance-disks [***VALUE***]For example:
--custom-instance-disks name=core,diskSize=3000If you do not do this, your scaling changes will be lost after the resizing.
-
- If the Data Lake root disk volume was manually resized to a size larger than 200 GB (200 GB being the default value), then it goes back to 200 GB after resize. In this case you need to resize the disk size manually again after Data Lake resize.
- If resizing from Medium Duty to Enterprise Data Lake, you must be on Cloudera Runtime 7.2.17 before attempting the resize.
-
If you would like to resize an existing single availability zone (single-AZ) Data Lake to a multiple availability zone (multi-AZ) Data Lake, the following limitations apply:
-
The AZ resizing functionality is currently available for AWS and Azure only.
-
Existing Cloudera Data Hub clusters attached to the Data Lake are not resized to multi-AZ as part of the Data Lake resizing process.
-
The single to multi-AZ resizing is only available when resizing a Data Lake via CDP CLI. The single-AZ to multi-AZ resizing is not available via the Data Lake resizing option in the Cloudera web interface.
-
Prerequisites
Prior to resizing the Data Lake, ensure that the following are in place:
- The Data Lake must be running to perform the resizing operation.
- The Data Lake and Cloudera Data Hub databases must be upgraded to PostgreSQL 14. For more information, see Upgrading Data Lake/Cloudera Data Hub database.
- If you are using an Azure environment, you must upgrade the PostgreSQL database used by the Data Lake to Azure Flexible Server before you can perform the Data Lake resize operation. For more information, see Upgrading Azure Single Server to Flexible Server. The Single to Flexible Server upgrade happens automatically when you upgrade from PostgreSQL 11 to PostgreSQL 14. Make sure to review both the database upgrade and the Azure Single to Flexible Server upgrade documentation.
- For RAZ-enabled Data Lakes, update the appropriate Ranger policy to give the backup and restore feature permission to access the backup location in the cloud. See instructions for configuring RAZ for backup here.
- Make sure that Atlas is up to date and has processed all the lineage data in Kafka. To do this, follow the steps in Checking that Atlas is up-to-date. If Atlas is not up to date, lineage/audit information in Kafka that is not processed by Atlas will be lost.
- If you are using Cloudera Data Warehouse, you must upgrade to version
1.4.1 or higher before you can resize the Data Lake. Determine the Cloudera Data Warehouse version you are on by clicking edit on the
environment:
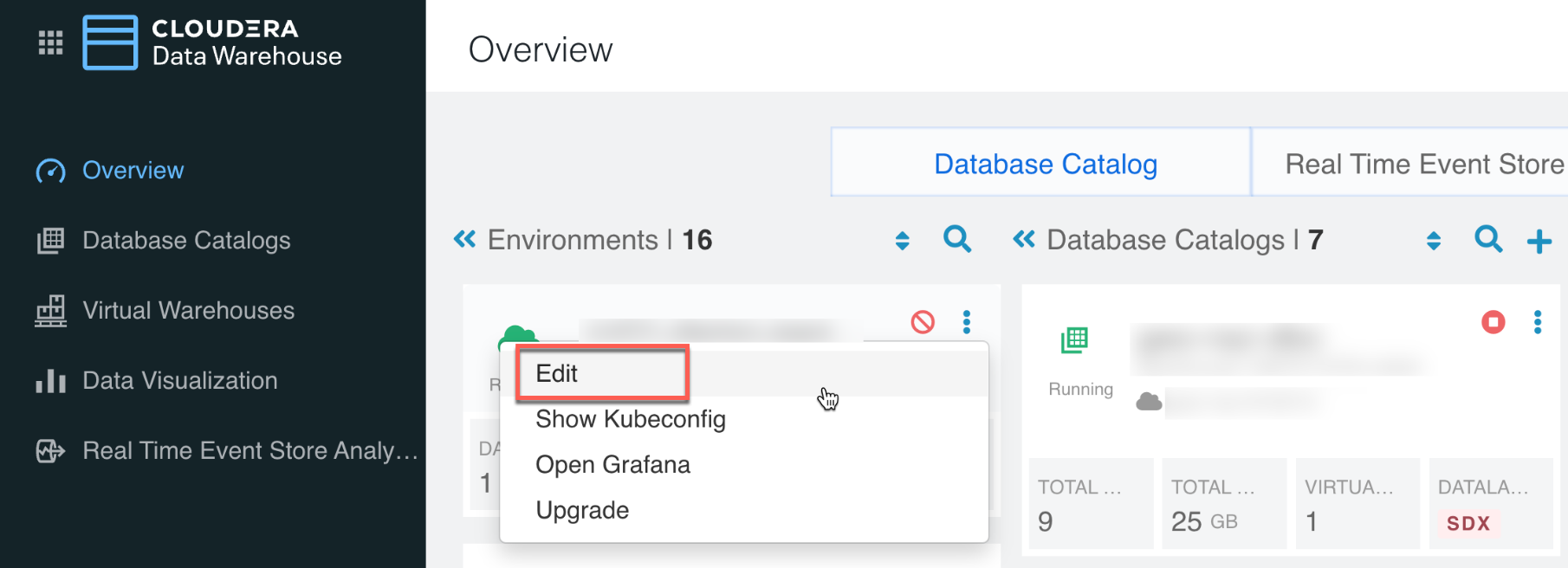
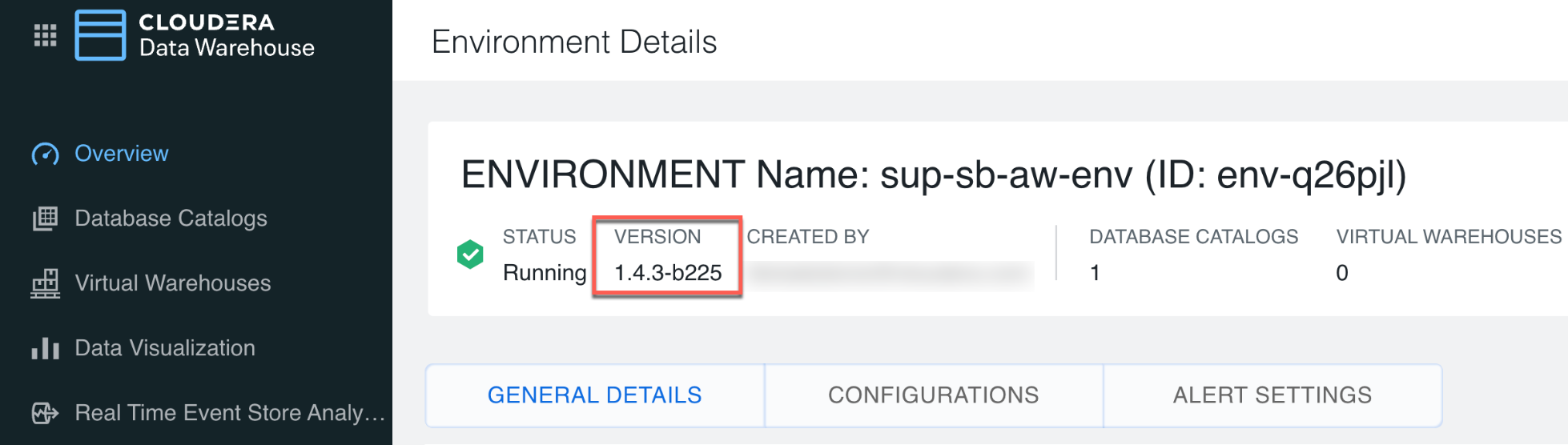
- If you are using Cloudera Data Warehouse, stop the virtual warehouses and data catalogs associated with the environment.
- If you are using a lower version than Cloudera Data Engineering 1.15,
upgrade to Cloudera Data Engineering 1.15 and complete the following
steps:
- Take a backup of your jobs following Backing up Cloudera Data Engineering jobs.
- Create a new Cloudera Data Engineering service and virtual cluster.
- Restore the jobs following the instructions in Restoring Cloudera Data Engineering jobs from backup.
- If you are using Cloudera AI:
- Backup Cloudera AI workbenches (AWS only). If backup is not supported, then proceed to the next step.
- Suspend Cloudera AI workbenches. If the suspend capability is not available, follow the steps in Refreshing Cloudera AI governance pods after resizing the Data Lake.