CVE-2021-44228 remediation for Cloudera Data Warehouse
March 8, 2022 Update
Cloudera has released a new version of Cloudera Data Warehouse that upgrades the embedded Log4j version to 2.17.1.
December 22, 2021 Update
Cloudera has released a new version of Cloudera Data Warehouse which upgrades the embedded Log4j version to 2.16. This provides a permanent fix for CVE-2021-44228.
To use this version you must upgrade your Database Catalog(s) and Virtual Warehouse(s) to the latest version, which is 2021.0.4.1-3. Additionally, you can create new Virtual Warehouses using the latest version, and those will also have the fix for this vulnerability.
If you had previously applied the configurations shared below, then those are no longer required. Please reach out to Cloudera Support if you have additional questions.
Introduction
As mentioned in Cloudera Technical Service Bulletin 2021-545 (Critical vulnerability in log4j2 CVE-2021-44228), the Cloudera data service is impacted by the recent Apache Log4j2 vulnerability. As per that bulletin:
The Apache Security team has released a security advisory for CVE-2021-44228 which affects Apache Log4j2. A malicious user could exploit this vulnerability to run arbitrary code as the user or service account running the affected software. Software products using log4j versions 2.0 through 2.14.1 are affected and log4j 1.x is not affected. Cloudera is making short-term workarounds available for affected software and is in the process of creating new releases containing fixes for this CVE.
Short Term Resolution - Cloudera Data Warehouse
If you are using the Cloudera Data Warehouse data service in Cloudera on cloud, please follow the steps below to implement an immediate manual workaround. This will change the configurations within your running Cloudera Data Warehouse environment so that this vulnerability is mostly, but not completely mitigated. There will still remain some potential attack vectors, as per the official Apache guidance.
Note that this will not upgrade the specific Log4j libraries to a version that does not have this vulnerability. Instead, it protects against most attack vectors via configuration changes. See the “Long Term Resolution - Cloudera Data Warehouse” section below for information on what Cloudera is doing for the permanent fix to the Cloudera Data Warehouse data service.
These manual workaround steps need to be applied to already-running kubernetes pods. Some of the steps involve running kubectl commands to edit the configurations of the pods. Once these kubectl commands are run, if you edit the corresponding Virtual Warehouse (VW) or Database Catalog (DBC) - via the Cloudera Data Warehouse UI or CLI - then the changes you made via kubectl will be overwritten. So either refrain from making further edits to the VW/DBC, or re-apply the kubectl commands.
- Create new VW
- Existing VW that was stopped is now started (manually or via autostart)
- Already-running VW is autoscaled up
- Need to edit some other VW config (via the Cloudera Data Warehouse UI or CLI), in which case the VW will be restarted with new pods that have the original configurations as they existed prior to having run the kubectl commands
- Upgrade of an environment
We understand that it puts additional operational burden to manage this vulnerability while the release with the permanent fix is delivered. If you prefer to simplify the operation while still keeping your Cloudera Data Warehouse environment online, then we recommend you disable autosuspend and auto-scale until the permanent fix is released. If autosuspend is disabled, then you would need to manually suspend the VW whenever it is not needed to avoid extra cost; then when it starts back up the kubectl commands need to be run again on the new pods.
Please see Appendix A below for the manual configuration workaround steps.
Long Term Resolution - Cloudera Data Warehouse
See the “December 22, 2021 Update” section above for details on the permanent fix for CVE-2021-44228. Please note that Cloudera will be releasing a subsequent version containing Log4j 2.17 in January. Moving forward, Cloudera will continue to monitor for other CVEs that are found, and will release updates appropriately to address them.
Cloudera JDBC and ODBC Drivers
The ODBC drivers for Impala and Hive are not affected by this vulnerability.
The Apache Hive JDBC driver uses the SLF4J API, but does not bundle Log4j as a logging provider. If an end user or a client application makes Log4j available as a provider when using the driver, then the user/client must make sure that they are using a Log4j version that is not affected by this vulnerability.
The following JDBC drivers for Impala and Hive are affected. Of those published on the Cloudera Downloads page, only the following versions are impacted. Each of these use Log4j version 2.12.1 or 2.13.3.
- v2.6.12
- v2.6.12
- v2.6.13
- v2.6.14
- v2.6.15
- v2.6.18
- v2.6.19
- v2.6.20
- v2.6.21
- v2.6.22
- v2.6.23
- v2.6.24
Note that earlier versions of these JDBC drivers use Log4j versions that are not affected by this vulnerability, and can be ignored.
Short Term Resolution - Drivers
Remove the JndiLookup class from the driver jar file. The following command shows an example of how to do this, using the Impala JDBC 2.6.24 version of the driver. This is one command, with all parts to be included on a single line.
zip -q -d ~/JDBC-Drivers/ClouderaImpalaJDBC-2.6.24.1029/ClouderaImpalaJDBC42-2.6.24.1029/ImpalaJDBC42.jar
com/cloudera/impala/jdbc42/internal/apache/logging/log4j/core/lookup/JndiLookup.classMore information on this workaround is provided by the Apache Software Foundation here: https://logging.apache.org/log4j/2.x/security.html
Long Term Resolution - Drivers
New versions of the drivers will be released shortly that are not affected by this vulnerability. As these become available Cloudera will notify customers and make the new drivers available on the Cloudera Downloads page.
If there are further questions related to configuration of these drivers, please open a support case with Cloudera.
Appendix A - Manual Configuration Workaround
In several of the steps below it is required to use kubectl. In order to do this you will need the kubeconfig for the kubernetes cluster. You can see how to do this on AWS here, and on Azure here. Also, the kubectl commands require an ID for the virtual warehouse that is being updated. This ID is of the form “compute-##########-####” or “impala-##########-####”, and it can be found underneath the VW name on the Cloudera Data Warehouse Overview page.
Please note that the configuration changes made via the web console (for Data Analytics Studio, Hive Metastore, and Hue) must be completed before the remaining changes, done via kubectl, are applied. Once the web console changes are made, be sure to wait for the DBC/VW to restart completely before continuing on with the kubectl commands.
- Go to the DBC
- Edit
- Configuration → Das Event Processor → env → Add key
LOG4J_FORMAT_MSG_NO_LOOKUPS=true - Apply
Hive Metastore
- Go to the DBC
- Edit
- Configuration → Metastore → env → SERVICE_OPTS, append
“
-Dlog4j2.formatMsgNoLookups=true” (with a space in front of -D)Note: if the env doesn’t show SERVICE_OPTS, select any other configuration file and then select “env” again.
-
Apply
Hue
- Go to the Hive VW
- Edit
- Configuration → Hue → env →hue-query-processor-log4j2.yaml → add the following under Property
-name: formatMsgNoLookups value: true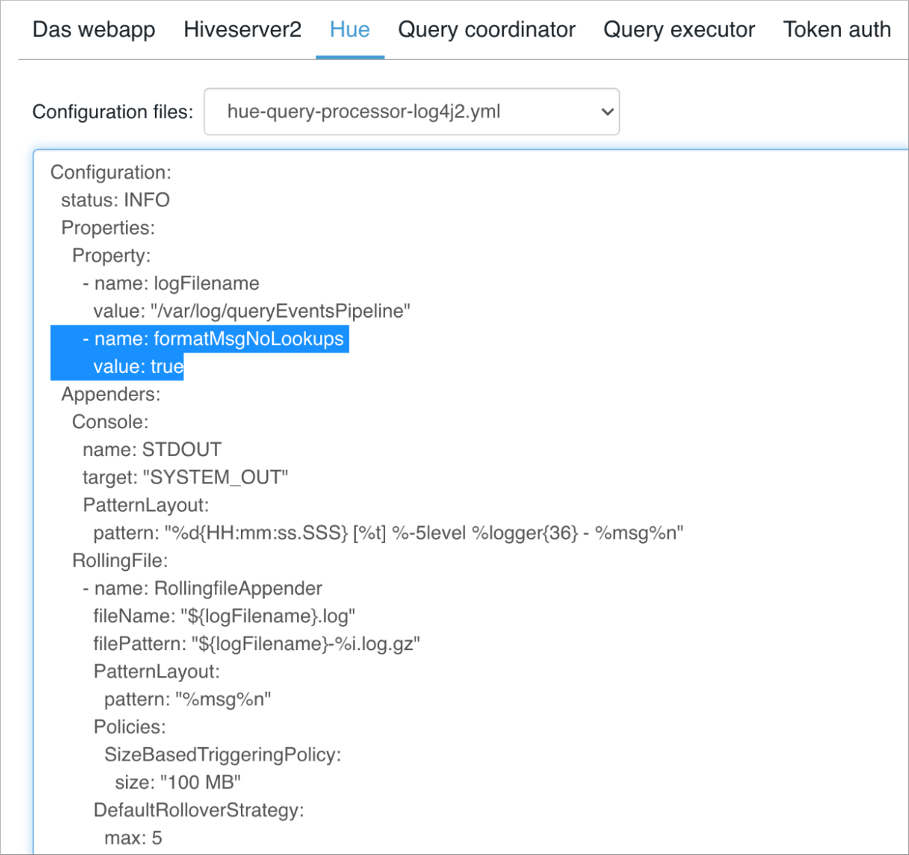
- Apply
Hive Virtual Warehouse: Hive Server2
-
Fetch the statefulsets for hiveserver2 pod using “kubectl”
$ kubectl -n compute-1639516105-l76g get sts NAME READY AGE das-webapp 1/1 4h20m hiveserver2 1/1 4h20m huebackend 1/1 4h20m hueep 1/1 4h20m hueqp 1/1 4h20m query-coordinator-0 2/2 4h20m query-executor-0 2/2 4h20m standalone-compute-operator 1/1 4h20m - Edit the statefulset and append
-Dlog4j2.formatMsgNoLookups=trueto the HADOOP_CLIENT_OPTS for container with EDWS_SERVICE_NAME=hiveserver2In the editor, change the following section:kubectl -n compute-1639516105-l76g edit sts hiveserver2containers: - env: - name: EDWS_SERVICE_NAME value: hiveserver2 - name: HADOOP_CLIENT_OPTS value: -DGroup_ID=compute-1639516105-l76g -Dorg.wildfly.openssl.path=/usr/lib64 -Dzookeeper.sasl.client=false -Djdk.tls.disabledAlgorithms=SSLv3,GCM -Xms8192M -Xmx11468M -Xss512k -Xloggc:/var/log/hive/hiveserver2-gc-%t.log -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -Dlog4j2.formatMsgNoLookups=true - This will restart the containers automatically. Wait until all the containers have restarted
- To confirm that the change has taken effect, ssh to the container and execute something like
“ps auxww”. This shows the hiveserver2 process and the command line should include the
'-Dlog4j2.formatMsgNoLookups=true' property, which was added above.
hive 1 4.6 3.7 14128040 1228016 ? Ssl 01:31 0:30 /etc/alternatives/jre/bin/java -Dproc_jar -Dproc_hiveserver2 -DGroup_ID=compute-1639516105-l76g -Dorg.wildfly.openssl.path=/usr/lib64 -Dzookeeper.sasl.client=false -Djdk.tls.disabledAlgorithms=SSLv3,GCM -Xms8192M -Xmx11468M -Xss512k -Xloggc:/var/log/hive/hiveserver2-gc-%t.log -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -Dlog4j2.formatMsgNoLookups=true -javaagent:/jmx-exporter/jmx_prometheus_javaagent-0.11.0.jar=35000:/jmx-exporter/config.yml -Dlog4j.configurationFile=hive-edws-log4j2.properties -Djava.util.logging.config.file=/usr/lib/hive/bin/../conf/parquet-logging.properties -Dyarn.log.dir=/usr/lib/hadoop/logs -Dyarn.log.file=hadoop.log -Dyarn.home.dir=/usr/lib/hadoop-yarn -Dyarn.root.logger=INFO,console -Djava.library.path=/usr/lib/hadoop/lib/native -Dhadoop.log.dir=/usr/lib/hadoop/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/usr/lib/hadoop -Dhadoop.id.str=hive -Dhadoop.root.logger=INFO,console -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /usr/lib/hive/lib/hive-service-3.1.3000.2021.0.5-b17.jar org.apache.hive.service.server.HiveServer2
Hive Virtual Warehouse: Query Co-ordinator
- Fetch the statefulsets for hiveserver2 pod using “kubectl”
$ kubectl -n compute-1639516105-l76g get sts NAME READY AGE das-webapp 1/1 4h20m hiveserver2 1/1 4h20m huebackend 1/1 4h20m hueep 1/1 4h20m hueqp 1/1 4h20m query-coordinator-0 2/2 4h20m query-executor-0 2/2 4h20m standalone-compute-operator 1/1 4h20m - Edit the statefulset and append -Dlog4j2.formatMsgNoLookups=true to the JAVA_OPTS for
container with EDWS_SERVICE_NAME=query-coordinator
kubectl -n compute-1639516105-l76g edit sts query-coordinator-0 containers: - env: - name: EDWS_SERVICE_NAME value: query-coordinator - name: JAVA_OPTS value: -Dorg.wildfly.openssl.path=/usr/lib64 -Dzookeeper.sasl.client=false -Djdk.tls.disabledAlgorithms=SSLv3,GCM -Xms2048M -Xmx2867M -server -Djava.net.preferIPv4Stack=true -XX:NewRatio=8 -XX:+UseNUMA -XX:+ResizeTLAB -Xloggc:/var/log/hive/query-coordinator-gc-%t.log -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -verbose:gc -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -Dlog4j2.formatMsgNoLookups=true - This will restart the containers automatically. Wait until all the containers have restarted
- To confirm that the change has taken effect, ssh to the container and execute something like
“ps auxww”. This shows the query coordinator process and the command line should include
the '-Dlog4j2.formatMsgNoLookups=true' property, which was added above.
hive 1 5.9 2.8 8917460 918892 ? Ssl 01:47 0:24 /etc/alternatives/jre/bin/java -Dproc_querycoordinator -classpath /etc/hive/conf:/custom-jars/*:/custom-jars/lib/*:/usr/lib/hive/lib/*:/etc/tez/conf:/usr/lib/tez/*:/usr/lib/tez/lib/*:/etc/hadoop/conf:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/.//*:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/.//*:/usr/lib/hadoop-mapreduce/.//*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/.//*:/efs/udf-jars/conf:/efs/udf-jars/lib/udfs/* -server -Djava.net.preferIPv4Stack=true -Dlog4j.configurationFile=tez-edws-log4j2.properties -DisThreadContextMapInheritable=true -DLog4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector -Dlog4j2.asyncLoggerRingBufferSize=1000000 -Dorg.wildfly.openssl.path=/usr/lib64 -Dzookeeper.sasl.client=false -Djdk.tls.disabledAlgorithms=SSLv3,GCM -Xms2048M -Xmx2867M -server -Djava.net.preferIPv4Stack=true -XX:NewRatio=8 -XX:+UseNUMA -XX:+ResizeTLAB -Xloggc:/var/log/hive/query-coordinator-gc-%t.log -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -verbose:gc -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -Dlog4j2.formatMsgNoLookups=true -javaagent:/jmx-exporter/jmx_prometheus_javaagent-0.11.0.jar=35001:/jmx-exporter/config.yml org.apache.tez.dag.app.DAGAppMaster --session
Impala Virtual Warehouse
- Coordinator
- Update coordinator statefulset and set
-Dlog4j2.formatMsgNoLookups=truein JAVA_TOOL_OPTIONS environment variable$kubectl --kubeconfig ~/kubeconfig edit sts coordinator -n impala-1639530043-8fnb ... - /opt/impala/bin/impalad - --flagfile=/opt/impala/conf/flagfile command: - /opt/impala/bin/daemon_entrypoint.sh env: - name: JAVA_TOOL_OPTIONS value: -Xms2G -Xmx4G -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/impala/dump.hprof -XX:+UseConcMarkSweepGC -Dlog4j2.formatMsgNoLookups=true - name: POD_NAME valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.name image: container-dev.repo.cloudera.com/cloudera/impalad_coordinator:2021.0.5-b17 imagePullPolicy: IfNotPresent name: impalad-coordinator ...
- Update coordinator statefulset and set
- Executor
- Update impala-executor-<xxx> statefulset and set
-Dlog4j2.formatMsgNoLookups=truein JAVA_TOOL_OPTIONS environment variable$kubectl --kubeconfig ~/kubeconfig edit sts impala-executor-000 -n impala-1639530043-8fnb ... env: - name: JAVA_TOOL_OPTIONS value: -Xms2G -Xmx4G -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/impala/dump.hprof -XX:+UseConcMarkSweepGC -Dhttp.maxConnections=16 -Dlog4j2.formatMsgNoLookups=true image: container-dev.repo.cloudera.com/cloudera/impalad_executor:2021.0.5-b17 imagePullPolicy: IfNotPresent lifecycle: preStop: exec: command: - /bin/bash - /opt/impala/bin/graceful_shutdown_backends.sh - "3600" name: impalad-executor ... - If there are multiple impala-executor-<xxx> statefulsets then the above steps should be repeated for all of them.
- Update impala-executor-<xxx> statefulset and set
- Catalogd
- Update catalogd deployment and set
-Dlog4j2.formatMsgNoLookups=truein JAVA_TOOL_OPTIONS environment variable$kubectl --kubeconfig ~/kubeconfig edit deployment catalogd -n impala-1639530043-8fnb ... env: - name: JAVA_TOOL_OPTIONS value: -Xms2G -Xmx6G -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/impala/dump.hprof -XX:+UseConcMarkSweepGC -Dlog4j2.formatMsgNoLookups=true image: container-dev.repo.cloudera.com/cloudera/catalogd:2021.0.5-b17 imagePullPolicy: IfNotPresent livenessProbe: exec: command: - sh - -c - curl -I --silent http://localhost:25021/metrics | grep -q "HTTP/1.1 200 OK" failureThreshold: 20 initialDelaySeconds: 1 periodSeconds: 20 successThreshold: 1 timeoutSeconds: 2 name: catalogd . . .
- Update catalogd deployment and set